使用 Java 的 AWS Lambda:快速且低成本的方法
AWS Lambda 是一个流行的无服务器开发平台,作为一名 Java 开发人员,我想使用它,但有一些问题需要解决。我将通过下面文章,和大家分享一下Java AWS Lambda开发平台的内容。
引入
AWS Lambda 是一个流行的无服务器开发平台,作为一名 Java 开发人员,我喜欢能够使用这个平台,但有一些要点需要首先解决。
- AWS Lambda 上的无服务器函数的成本对于 JVM 来说会很昂贵。
- AWS Lambda 上的冷启动在 JVM 上可能是一个真正的问题。
- 在 AWS Lambda 上为每个请求最大化效率可能代价高昂,并且在 JVM 中效率不高。
本文的两个主要目的如下:
- 学习如何在无服务器平台(Lambda)上使用 AWS 服务,例如 Quarkus 框架的 DynamoDB。
- 在 AWS Lambda 上获得最佳性能并降低成本。
演示应用程序
此存储库包含一个由 JDK 11 和 Quarkus 开发的 Java 应用程序示例,它是一个简单的 AWS Lambda 函数。这个简单的函数将接受一个 JSON 格式的水果名称(输入)并返回一种水果类型。
{
"name": "apple"
}水果的类型将是:
- 春季水果
- 夏季水果
- 秋季水果
- 冬季水果
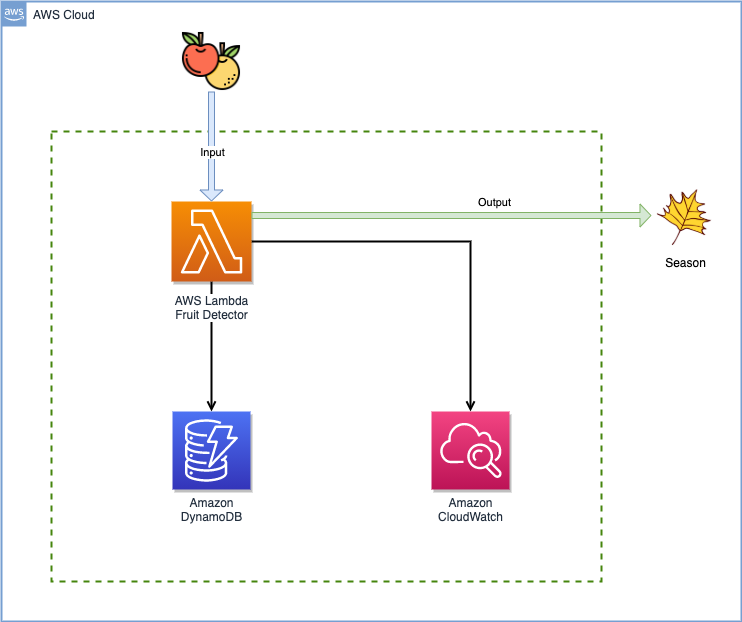
演示应用程序工作流程
这个演示是一个简单的 Java 应用程序,它获取请求的水果信息,提取水果的类型,并返回正确的水果类型。哪有那么简单?!

创建基于 Quarkus 的 Java 应用程序
Quarkus 提供了扩展 AWS Lambda 项目的明确指南。可以使用 Maven 命令轻松访问此项目模板。
mvn archetype:generate \ -DarchetypeGroupId=com.thinksky \ -DarchetypeArtifactId=aws-lambda-handler-qaurkus \ -DarchetypeVersion=2.1.3.Final
该命令将使用 AWS Java SDK 生成应用程序。
Quarkus 框架具有针对 DynamoDB、S3、SNS、SQS 等的扩展,我更喜欢使用提供非阻塞功能的 AWS Java SDK V2。因此,项目 pom.xml 文件需要按照本指南进行修改。
该项目具有 Lambda,它是 pom 文件中的一个依赖项。
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-amazon-lambda</artifactId>
</dependency>需要添加依赖项以使用 AWS DynamoDB 建立与 DynamoDB 的连接
<dependencies>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-amazon-dynamodb</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-apache-httpclient</artifactId>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>apache-client</artifactId>
<exclusions>
<exclusion>
<artifactId>commons-logging</artifactId>
<groupId>commons-logging</groupId>
</exclusion>
</exclusions>
</dependency>
</dependencies>我将在可以使用apache-client依赖项添加的应用程序的设置上使用 apache 客户端。
quarkus.dynamodb.sync-client.type=apache
使用 Quarkus 在 AWS Lambda 上开发 Java 应用程序的好处
常规的 AWS Lambda Java 项目将是一个普通的 Java 项目;然而,Quarkus 将在 Java 项目中引入依赖注入。
@ApplicationScoped
public class FruitService extends AbstractService {
@Inject
DynamoDbClient dynamoDB;
public List<Fruit> findAll() {
return dynamoDB.scanPaginator(scanRequest()).items().stream()
.map(Fruit::from)
.collect(Collectors.toList());
}
public List<Fruit> add(Fruit fruit) {
dynamoDB.putItem(putRequest(fruit));
return findAll();
}
}DynamoDbClient是 AWS Java SDK.v2 中的一个类,Quarkus 将在其依赖注入生态系统中构建并提供该类。该FruitService是由叫做抽象类继承AbstractService,这抽象类提供的基本对象DynamoDbClient的需求,例如ScanRequest,PutItemRequest等等。
反射在 Java 框架中很流行,但这将是 GraalVM native-image 的新挑战。(但是 Quarkus 有一个简单的解决方案来应对这个挑战,那就是对 classes 的注释@RegisterForReflection。这不是在 GraalVM 中注册反射类的最简单方法吗?
@RegisterForReflection
public class Fruit {
private String name;
private Season type;
public Fruit() {
}
public Fruit(String name, Season type) {
this.name = name;
this.type = type;
}
}还值得一提的是,Quarkus 在使用 AWS Lambda 平台的同时还提供了许多其他好处。我将在以后的一系列文章中描述它们。
在 AWS Lambda 上部署演示应用程序
现在是 AWS 上的部署时间,使用 Maven 和 Quarkus 框架的过程会相对简单。但是,在部署和运行应用程序之前,需要在 AWS 上做更多准备。部署过程包括以下步骤:
1) 在 DynamoDB 中定义 Fruits_TBL 表
$ aws dynamodb create-table --table-name Fruits_TBL \
--attribute-definitions AttributeName=fruitName,AttributeType=S \
AttributeName=fruitType,AttributeType=S \
--key-schema AttributeName=fruitName,KeyType=HASH \ AttributeName=fruitType,KeyType=RANGE \
--provisioned-throughput ReadCapacityUnits=1,WriteCapacityUnits=1然后在桌子上插入一些 fruits。
$ aws dynamodb put-item --table-name Fruits_TBL \
--item file://item.json \
--return-consumed-capacity TOTAL \
--return-item-collection-metrics SIZE这是 item.json 的内容
{
"fruitName": {
"S": "Apple"
},
"fruitType": {
"S": "Fall"
}
}最后,从 Dynamodb 运行查询以确保我们有项目。
$ aws dynamodb query \
--table-name Fruits_TBL \
--key-condition-expression "fruitName = :name" \
--expression-attribute-values '{":name":{"S":"Apple"}}'2) 在 IAM 中定义一个角色以访问 DynamoBD 并将其分配给我们的 Lambda 应用程序。
$ aws iam create-role --role-name Fruits_service_role --assume-role-policy-document file://policy.json
policy.json
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Principal": {
"Service": [
"dynamodb.amazonaws.com",
"lambda.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
}然后,将 DynamoDB 权限分配给该角色。
$ aws iam attach-role-policy --role-name Fruits_service_role -- policy-arn "arn:aws:iam::aws:policy/AmazonDynamoDBFullAccess"
然后这个。
$ aws iam attach-role-policy --role-name Fruits_service_role --policy-arn "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
并且该角色可能还需要以下权限。
$ aws iam attach-role-policy --role-name Fruits_service_role --policy-arn "arn:aws:iam::aws:policy/AWSLambda_FullAccess"
最后,AWS 平台现已准备好托管我们的应用程序。
为了继续部署过程,我们需要构建我们的应用程序并修改生成的文章。
$ mvn clean install
Quarkus 框架将负责创建 JAR 工件文件、压缩该 JAR 文件并准备AWS的SAM 模板。这次应该使用JVM版本,修改方法如下:
1) 将定义的角色添加到 Lambda 以获得适当的访问权限
Role:arn:aws:iam::{Your-Account-Number-On-AWS}:role/fruits_service_role2)增加超时时间
因此,SAM 模板现在已准备好部署在 AWS Lambda 上。
$ sam deploy -t target/sam.jvm.yaml -g
此命令会将 jar 文件以 zip 格式上传到 AWS 并将其部署为 Lambda 函数。下一步将是通过调用请求来测试应用程序
在 AWS Lambda + JVM 平台上观看演示应用程序的性能
是时候运行部署的 Lambda 函数、测试它并查看它的执行情况了。
$ aws lambda invoke response.txt --cli-binary-format raw-in-base64-out --function-name {:fruitApp} --payload file://payload.json --log-type Tail --query LogResult --output text | base64 --decode我们可以使用以下命令找出 FUNCTION_NAME。
$ aws lambda list-functions --query 'Functions[?starts_with(FunctionName, `fruitAppJVM`) == `true`].FunctionName'
FruitAppJVM 是我在部署过程中给 SAM CLI 的 Lambda 的名称。
然后我们可以参考AWS的web控制台查看调用该函数的结果。
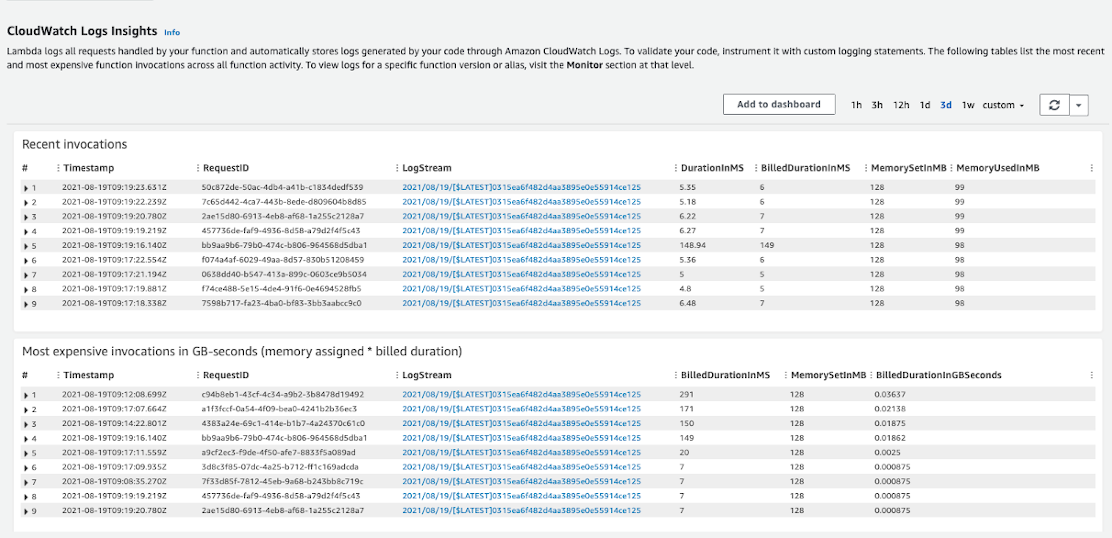
数字在说话,由于 AWS Lambda 的冷启动功能,这对于一个简单的应用程序来说是一个可怕的性能。
什么是 AWS Lambda 冷启动?
运行 Lambda 函数时,只要它被积极使用,它就会保持活动状态,这意味着您的容器保持活动状态并准备好执行。但是,AWS 将在一段时间不活动(通常很短)后丢弃容器,并且您的函数将变得不活动或冷。当请求到达空闲 lambda 函数时,会发生冷启动。之后,Lambda 函数将被初始化以能够响应请求。(Java 框架的初始化模式)。
另一方面,当有可用的 lambda 容器时会发生热启动。
冷启动是我们有这种糟糕性能的主要原因,因为每次冷启动发生时,AWS 都会初始化我们的 Java 应用程序,显然,每个请求都需要很长时间。
AWS Lambda 冷启动挑战的可用解决方案
有两种方法可以应对这一基本挑战。
- 使用不属于本文范围的预配置并发。
- 在应用程序的初始化和响应时间上获得更好的性能带来了如何在我们的 Java 应用程序中实现更好性能的问题。答案是从我们的 Java 应用程序创建一个本地二进制可执行文件,并使用Oracle GraalVM将其部署在 AWS Lambda 上。
GraalVM 是什么?
GraalVM 是一种高性能 JDK 发行版,旨在加速用 Java 和其他 JVM 语言编写的应用程序的执行,同时支持 JavaScript、Ruby、Python 和许多其他流行语言。Native-Image 是一种提前技术,可将 Java 代码编译为独立的可执行文件。此可执行文件包括应用程序类、其依赖项中的类、运行时库类以及来自 JDK 的静态链接本机代码。它不在 Java VM 上运行,但包括来自不同运行时系统(称为“Substrate VM”)的必要组件,如内存管理、线程调度等。
从 Java 应用程序构建本机二进制可执行文件
首先,我们需要安装 GraalVM 及其 Native-Image 。然后,通过安装 GraalVM,我们可以使用 GraalVM 将 Java 应用程序转换为原生二进制可执行文件。Quarkus 使它变得简单,它有一个 Maven/Gradle 插件,所以在一个典型的基于 Quarkus 的应用程序中,我们将有一个名为native.
$ mvn clean install -Pnative
Maven 将根据您使用的操作系统构建一个本地二进制可执行文件。如果你在 Windows 上开发,这个文件将只能在 Windows 机器上运行;但是,AWS Lambda 需要基于 Linux 的二进制可执行文件。在这种情况下,Quarkus 框架将通过其插件上的一个简单参数来满足此要求-Dquarkus.native.container-build=true。
$ mvn clean install -Pnative \
-Dquarkus.native.container-build=true \
-Dquarkus.native.builder-image=quay.io/quarkus/ubi-quarkus-native-image:21.2-java11如上命令所示, using-Dquarkus.native.builder-image可以指定我们要使用的 GraalVm 版本。
AWS Lambda 环境
AWS Lambda 有几个不同的可部署环境。
╔═════════╦═══════════════════╦════════════════════╗ ║ Runtime ║ Amazon Linux ║ Amazon Linux 2 ║ ╠═════════╬═══════════════════╬════════════════════╣ ║ Node.js ║ nodejs12.x ║ nodejs10.x ║ ║ Python ║ python3.7 and 3.6 ║ python3.8 ║ ║ Ruby ║ ruby2.5 ║ ruby2.7 ║ ║ Java ║ java ║ java11 , java8.al2 ║ ║ Go ║ go1.x ║ provided.al2 ║ ║ .NET ║ dotnetcore2.1 ║ dotnetcore3.1 ║ ║ Custom ║ provided ║ provided.al2 ║ ╚═════════╩═══════════════════╩════════════════════╝
所以我们之前通过java11(Corretto 11)在Lambda上部署了Java Application,并没有表现出很好的性能。
对于 Lambda 上的纯 Linux 平台,我们目前有两个选项,它们是provided和provided.al2。
值得一提的是,provided会使用Amazon Linux,并且provided.al2会使用Amazon Linux 2,因此,由于版本2的长期支持,强烈推荐使用版本2。
在 AWS Lambda 上部署二进制可执行文件
正如我们所见,Quarkus 会为我们生成两个 sam 模板;一个用于 JVM 基础 Lambda,第二个是本机二进制可执行文件。这次我们应该使用原生的 sam 模板,它也需要一些小的修改。
1.更改为 AWS Linux V2
Runtime: provided.al2
2. 将定义的角色添加到 Lambda 以获得适当的访问权限。
Role: arn:aws:iam::{Your-Account-Number-On-AWS}:role/fruits_service_role3.增加超时时间
Timeout: 30
原生 SAM 模板的最终版本将是这样的final.sam.native.yaml;它现在已准备好部署在 AWS 上。
$ sam deploy -t target/sam.native.yaml -g
此命令会将二进制文件作为 zip 格式上传到 AWS 并将其部署为 Lambda 函数,与 JVM 版本完全一样。现在,我们可以跳到令人兴奋的部分,即监控性能。
在 AWS Lambda + 自定义平台上观看演示应用程序的性能
是时候运行部署的 Lambda 函数、测试它并查看它的执行情况了。
$ aws lambda invoke response.txt --cli-binary-format raw-in-base64-out --function-name {:fruitApp} --payload file://payload.json --log-type Tail --query LogResult --output text | base64 --decode我们可以使用以下命令找出 FUNCTION_NAME。
$ aws lambda list-functions --query 'Functions[?starts_with(FunctionName, `fruitAppNative`) == `true`].FunctionName'
FruitAppNative 是我在部署过程中给 SAM CLI 的 Lambda 的名称。
然后我们可以打开 AWS Web 控制台查看调用该函数的结果。
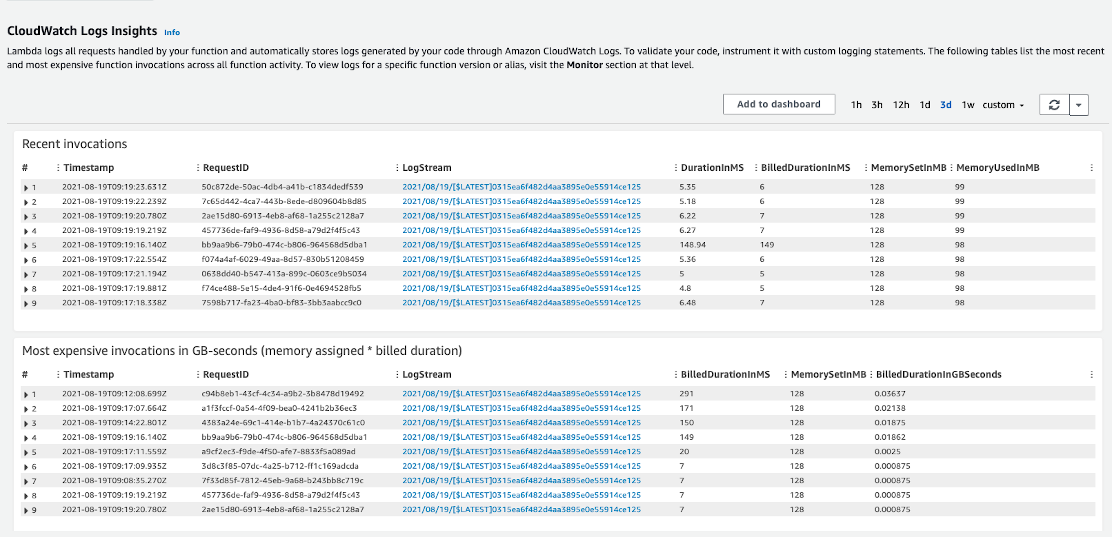
在 AWS Lambda 上分析 JVM 与原生二进制的性能
我们可以在两个类别中分析和比较 AWS Lambda 平台上应用程序的两个版本。
- 初始化时间:第一次调用或调用 Lambda 函数所消耗的时间称为初始化时间。这几乎是在 Lambda 上调用应用程序的最长持续时间,因为在此阶段我们的 Java 应用程序将从头开始。

- JVM 和 Binary 版本之间存在相当大的差异,这意味着原生二进制版本的初始化时间几乎比 JVM 版本快八倍。
- 请求时间:我在初始化步骤后调用了 9 次 Lambda 函数,这是性能结果。

根据结果,JVM 版本和 Native 二进制文件之间的性能存在显着差异。
结论
Quarkus 框架将通过提供一些很好的特性,如依赖注入,帮助我们在 Java 应用程序上拥有清晰和结构化的代码。此外,它还有助于在 GraalVM 的帮助下将我们的 Java 应用程序转换为原生二进制文件。
与 JVM 版本相比,本机二进制版本具有明显更好的性能。
- 二进制版本仅使用 128 MB 内存,而 JVM 版本使用 512 MB,从而在 AWS Lambda 上节省了大量资源。
- 二进制版本提供比 JVM 版本更好的请求时间,这意味着在 AWS Lambda 上可以节省更多时间。
总的来说,通过节省资源和时间,原生二进制方法已被证明是一种低成本的选择。