大语言模型排行榜!ChatGPT 稳居榜首,国产模型表现亮眼
近年来,随着人工智能技术的飞速发展,大语言模型(LLM)逐渐成为科技领域的热门话题。
这些模型拥有强大的语言理解和生成能力,可以进行文本摘要、问答、翻译、代码生成等多种任务,并展现出巨大的应用潜力。
然而,面对琳琅满目的模型,如何判断哪个模型更强大、更适合自己的需求呢?
为了更好地了解不同模型的优劣,各大研究机构和科技公司纷纷发布了大语言模型排行榜,为用户提供参考。
这些排行榜通常基于模型在不同任务上的表现进行排名,例如语言理解、生成能力、代码生成等。
SuperCLUE是一个由中国科学院自动化研究所和清华大学联合发布的中文语言理解评估基准,其总排行榜涵盖了多个语言理解任务,为我们提供了一个重要的参考标准。
今天我们一起看看SuperCLUE给出的9月大模型语言排行榜。
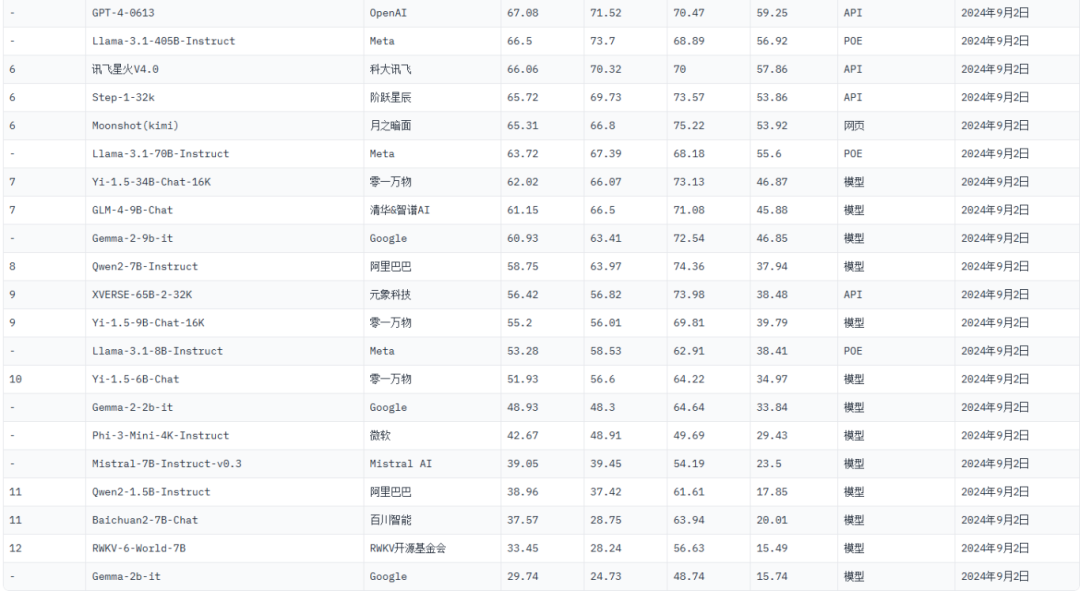
1.排名总榜
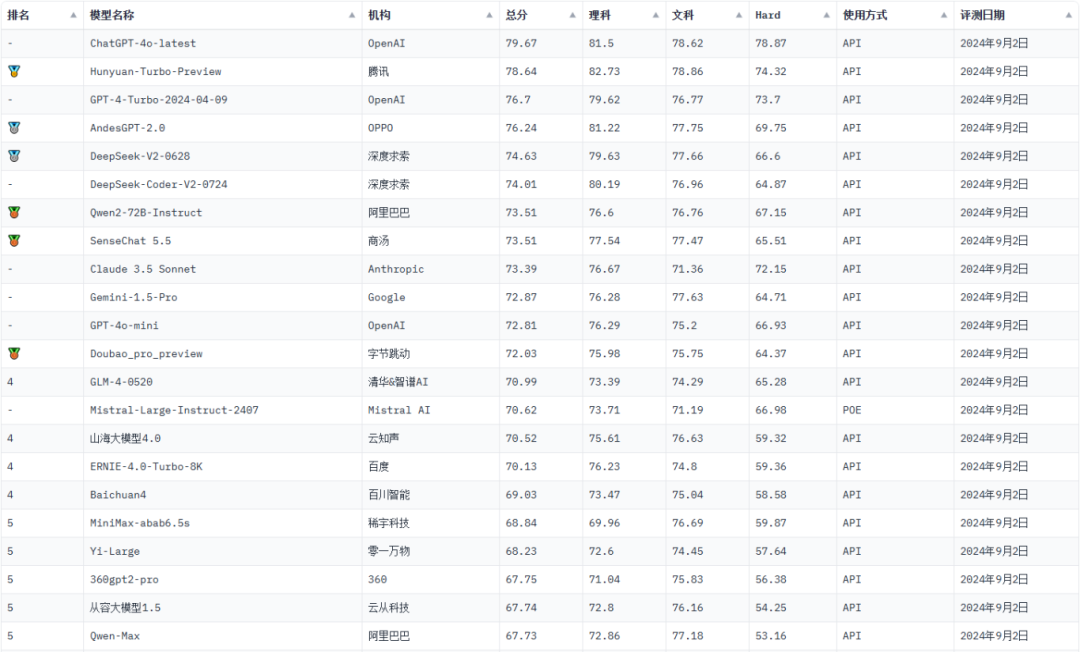
OpenAI的ChatGPT-4o-latest稳居榜首,总分为79.67, 在理科、文科和Hard任务上均取得了领先优势,展现出强大的综合能力。
腾讯的Hunyuan-Turbo-Preview位居第二,总分为78.64, 在理科任务上表现突出,展现出其在逻辑推理和知识理解方面的优势。
OpenAI的GPT-4-Turbo-2024-04-09位居第三,总分为76.7, 在文科任务上表现出色,展现出其在语言表达和情感分析方面的优势。
2.榜单亮点
国产模型崛起
除了OpenAI和Google等国际巨头,国内厂商也涌现出许多优秀的模型。
例如百度的文心一言、华为的盘古模型、阿里的通义千问等,在榜单中占据重要地位,展现出国产大模型的蓬勃发展态势。
多任务能力提升
榜单中大多数模型在多个任务上都取得了不错的成绩,展现出大语言模型在多任务处理能力上的进步。
模型规模和性能的平衡
榜单中既有参数规模巨大的模型,例如GPT-4、文心一言等;也有参数规模相对较小的模型,例如Qwen2-7B-Instruct、GLM-4-9B-Chat等,展现出模型规模和性能之间的平衡。
3.选择建议
根据需求选择
用户应根据自己的实际需求选择合适的模型,例如需要进行逻辑推理和知识理解的任务可以选择Hunyuan-Turbo-Preview,需要进行语言表达和情感分析的任务可以选择GPT-4-Turbo-2024-04-09。
综合考虑多个指标
用户应综合考虑模型在不同任务上的表现,以及模型的可用性、成本等因素,进行综合判断。
关注模型更新
大语言模型领域发展迅速,用户应关注模型的最新更新和改进,选择最符合自身需求的模型。
SuperCLUE总榜为我们提供了当前大语言模型的竞争格局,并为用户选择合适的模型提供了重要参考。
未来,随着人工智能技术的不断发展,大语言模型将会继续朝着更加强大、更加智能的方向发展,并为我们的生活带来更多便利和改变。
排名榜单链接🔗
https://www.superclueai.com/