在Java中的无死锁同步实现方法分享!内容解析!干货分享!
线程同步是克服多线程程序中竞争条件的好工具。但是,它也有阴暗面。死锁:难以发现、重现和修复的严重错误。防止它们发生的唯一可靠方法是正确设计您的代码,这是本文的主题。我们将看看死锁的起源,考虑一种发现现有代码中潜在死锁的方法,并提出设计无死锁同步的实用方法。这些概念将通过一个简单的演示项目进行说明。
假设读者已经熟悉多线程编程,并且对 Java 中的线程同步原语有很好的理解。在接下来的部分中,我们不会区分同步语句和锁 API,使用术语“锁”来表示这两种类型的可重入锁,在示例中更喜欢前者。
一、死锁机制
让我们回顾一下死锁是如何工作的。考虑以下两种方法:
java:
void increment ({
synchronized(lock1) {
synchronized(lock2){
variablel ++;
}
}
}
void decrement ({
synchronized(lock2){
synchronized(lock1) {
variable--;
}
}}
这些方法被有意设计为产生死锁。让我们详细考虑这是如何发生的。
increment() 和 decrement()基本上由以下5个步骤:
表格1
Step | increment() | decrement() |
1 | Acquire lock1 | Acquire lock2 |
2 | Acquire lock2 | Acquire lock1 |
3 | Perform increment | Perform decrement |
4 | Release lock2 | Release lock1 |
5 | Release lock1 | Release lock2 |
假设有两个并行线程,一个执行increment(),另一个执行decrement()。每个线程的步骤将按正常顺序执行,但是,如果我们将两个线程放在一起考虑,一个线程的步骤将与另一个线程的步骤随机交错。随机性来自系统线程调度程序强加的不可预测的延迟。可能的交织模式或场景非常多(准确地说,有 252 种)并且可以分为两组。第一组是其中一个线程足够快以获取两个锁(参见表 2)。显然,这两种方法中的第 1 步和第 2 步只有在相应的锁空闲时才能通过,否则,执行线程将不得不等待它们的释放。
表格2
No deadlock | ||
Thread-1 | Thread-2 | Result |
1: Acquire lock1 |
| lock1 busy |
2: Acquire lock2 |
| lock2 busy |
| 1: Acquire lock2 | wait for lock2 release |
3: Perform increment | Waiting at lock2 |
|
4: Release lock2 | Intercept lock2 | lock2 changed owner |
| 2: Acquire lock1 | wait for lock1 release |
5: Release lock1 | Intercept lock1 | lock1 changed owner |
| 3: Perform decrement |
|
| 4: Release lock1 | lock1 free |
| 5: Release lock2 | lock2 free |
在第二组中,两个线程都成功获取了锁。结果见表3:该组中的所有案例均成功完成。
表格3
Deadlock | ||
Thread-1 | Thread-2 | Result |
1: Acquire lock1 |
| lock1 busy |
| 1: Acquire lock2 | Lock2 busy |
2: Acquire lock2 |
| wait for lock2 release |
| 2: Acquire lock1 | wait for lock1 release |
Waiting at lock2 | Waiting at lock1 |
|
… | … |
|
该组中的所有情况都会导致第一个线程等待第二个线程拥有的锁,而第二个线程等待第一个线程拥有的锁,因此两个线程都无法进一步进行:
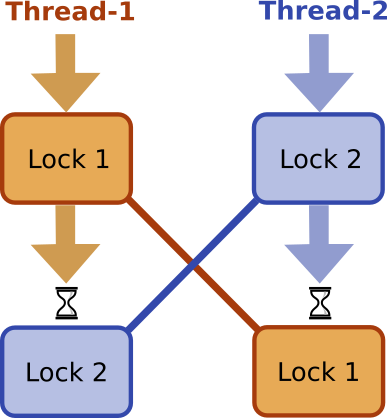
图1
这是具有所有典型属性的经典死锁情况。让我们概述重要的:
- 至少有两个线程,每个线程至少占用两个锁。
- 死锁只发生在特定的线程时序组合中。
- 死锁的发生取决于锁定顺序。
第二个属性意味着死锁不能随意重现。此外,它们的再现性取决于操作系统、CPU 频率、CPU 负载和其他因素。后者意味着软件测试的概念不适用于死锁,因为相同的代码可能在一个系统上完美运行而在另一个系统上失败。因此,交付正确应用程序的唯一方法是通过设计消除死锁。这种设计有两种基本方法,现在让我们从更简单的方法开始。
2. 粗粒度同步
从上面列表中的第一个属性可以看出,如果我们的应用程序中的任何线程都不允许同时持有多个锁,则不会发生死锁。好的,这听起来像是一个计划,但是我们应该使用多少锁以及将它们放在哪里?
最简单和最直接的答案是用一个锁保护所有事务。例如,为了保护一个复杂的数据对象,您可以将其所有公共方法声明为同步的。这种方法用于java.util.Hashtable. 简单的代价是由于缺乏并发而导致的性能损失,因为所有方法都是相互阻塞的。
幸运的是,在许多情况下,粗粒度同步可以以较少限制的方式执行,从而允许一些并发和更好的性能。为了解释它,我们应该引入一个事务连接变量的概念。假设如果满足两个条件中的任何一个,则两个变量在事务上连接:
- 存在涉及两个变量的交易。
- 两个变量都连接到第三个变量(传递性)。
因此,您首先以这样一种方式对变量进行分组,即同一组中的任何两个变量都具有事务性连接,而不同组中的任何两个变量都没有。然后通过单独的专用锁保护每个组:

图2
上面的解释对于“transaction”和“involves”这两个术语的确切含义来说有点短,但如果要准确地解释,那么解释的篇文章就太长了,所以这篇文章只有留给读者直觉和经验。
这种高级粗粒度同步的一个很好的现实例子是java.util.concurrent.ConcurrentHashMap. 在这个对象内部,有许多相同的数据结构(“桶(buckets)”),每个桶都由自己的锁保护。事务被分派到由键的哈希码确定的存储桶。因此,具有不同密钥的事务大多会进入不同的存储桶,这使得它们可以并发执行而不会牺牲线程安全性,由于存储桶的事务独立性,这是可能的。
但是,某些解决方案需要比粗粒度同步可以实现的更高级别的并发性。稍后,我们将考虑如何处理这个问题,但首先,我们需要介绍一种分析同步方案的有效方法。
3. 锁定图
假设您需要确定给定的代码是否包含潜在的死锁。让我们称这种任务为“同步分析”或“死锁分析”。你会如何处理这个问题?
最有可能的是,您会尝试对线程争用锁的所有可能场景进行排序,试图找出是否存在不良场景。在第 1 节中,我们采用了如此简单的方法,结果发现场景太多了。即使在最简单的情况下,也有 252 个,因此彻底检查它们是不可能的。在实践中,您可能最终只会考虑几个场景,并希望您没有遗漏一些重要的东西。换句话说,公平的死锁分析无法通过幼稚的方法完成,我们需要一种专门的、更有效的方法。
此方法包括构建锁定图并检查它是否存在循环依赖关系。锁定图是显示锁和线程在这些锁上的交互的图形。此类图中的每个闭环都表示可能存在死锁,并且没有闭环保证了代码的死锁安全性。
这是绘制锁定图的秘诀。它以第 1 节中的代码为例:
- 对于代码中的每个锁,在图表上放置一个相应的节点;在这个例子中,这些是
lock1和lock2 - 对于所有线程试图在已经持有锁 A 的情况下获取锁 B 的语句,画一个从节点 A 到节点 B 的箭头;在该示例中,将有“锁1 - >锁2”在
increment()和lock2 -> lock1中decrement()。如果一个线程按顺序使用多个锁,则为每两个连续的锁绘制一个箭头。
第 1 节中示例的最终图表如下所示:
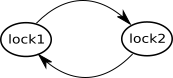
图 3
它有一个闭环: lock1 -> lock2 -> lock1,它立即告诉我们代码包含潜在的死锁。
让我们再做一个练习。思考以下代码:
java:
void transaction1 (int amount){
synchronized(lock1) {
synchronized(lock2) {
// do something}
}
void transaction2(int amount){
synchronized(lock2) {
synchronized(lock3) {
// do something}
}
void transaction3(int amount){
synchronized(lock3) {
synchronized(lock1) {
// do zomething}
}
让我们看看这段代码是否是死锁安全的。有3把锁:lock1,lock2,lock3和3条锁定路径:lock1 -> lock2在transaction1(),lock2 -> lock3在transaction2(),lock3 -> lock1在transaction3()。
结果图如图 4-A 所示:
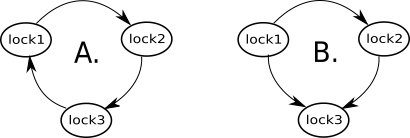
图 4
同样,此图立即表明我们的设计包含潜在的死锁。但是,不仅如此。它还提示我们如何修复设计;我们只需要打破循环!例如,我们可以交换方法中的锁transaction3()。相应的箭头改变方向,图 4-B 中的图变为无循环,这保证了固定代码的死锁安全性。
现在我们已经熟悉了图表的神奇之处,我们准备继续使用更复杂但更有效的方法来设计无死锁同步。
4. 带锁排序的细粒度同步
这一次,我们走的是让同步尽可能细粒度的路线,希望得到最大可能的事务并发度作为回报。这种设计基于两个原则。
第一个原则是禁止任何变量同时参与多个交易。为了实现这一点,我们将每个变量与一个唯一的锁相关联,并通过获取与相关变量关联的所有锁来启动每个事务。以下代码说明了这一点:
java:
void transaction(Item i1,Item i2, Item i3,double amount){
synchronized(i1.lock) {
synchronized(i2.lock){
synchronized(i3.lock) {
// do actual transaction on the items
}
}
}
}
一旦获得锁,其他事务就不能访问这些变量,因此它们不会被并发修改。这意味着系统中的所有事务都是一致的。同时,允许在不相交变量集上的事务并发运行。因此,我们获得了一个高度并发但线程安全的系统。
但是,这样的设计会立即导致死锁的可能性,因为现在我们处理多个线程和每个线程的多个锁。
然后,第二个设计原则开始发挥作用,它指出必须以规范的顺序获取锁以防止死锁。这意味着我们将每个锁与一个唯一的常量索引相关联,并始终按照它们的索引定义的顺序获取锁。将这个原理应用到上面的代码中,我们得到了细粒度设计的完整说明:
java:
void transaction(Item i1,Item i2,Item i3,double… amounts) {
// Our plan is to use item IDs as canonical indices for locks
Item[] order = {i1, i2, i3} ;
Arrays.sort(order,(a, b) -> Long. compare(a.id,b.id)) ;
synchronized(order [o].lock){
synchronized(order[1].lock){
synchronized(order[2].lock) {
// do actual transaction on the items
}
}
}
}
但是,确定规范排序确实可以防止死锁吗?我们能证明吗?答案是肯定的,我们可以使用锁定图来完成。
假设我们有一个有 N 个变量的系统,所以有 N 个关联的锁,因此图中有 N 个节点。如果没有强制排序,锁会以随机顺序被抓取,所以在图中,会有两个方向的随机箭头,并且肯定会存在表示死锁的闭环:

图 5
如果我们强制执行锁排序,从高到低索引的锁路径将被排除,所以唯一剩下的箭头将是那些从左到右的箭头:

图 6
无论我们多么努力,我们都不会在这个图上找到一个闭环,因为只有当箭头在两个方向上时才可能存在闭环,但事实并非如此。而且,没有闭环意味着没有死锁。证明是完整的。
好吧,通过使用细粒度锁和锁排序,我们可以构建一个高并发、线程安全和无死锁的系统。但是,提高并发性是否需要付出代价?让我们考虑一下。
首先,在低并发的情况下,与粗粒度的方法相比,存在一定的速度损失。每个锁捕获是一个相当昂贵的操作,但细粒度设计假设锁捕获至少是两倍。但是,随着并发请求数量的增加,由于使用了多个 CPU 内核,细粒度设计很快就会变得更好。
其次,由于大量的锁对象,存在内存开销。幸运的是,这很容易解决。如果受保护的变量是对象,我们可以摆脱单独的锁对象,并将变量本身用作自己的锁。否则,例如,如果变量是原始数组元素,我们可能只需要有限数量的额外对象。为此,我们定义了从变量 ID 到中等大小的锁数组的映射。在这种情况下,锁必须按它们的实际索引排序,而不是按变量 ID。
最后但并非最不重要的是代码的复杂性。虽然粗粒度的设计可以通过声明一些方法同步来完成,细粒度的方法需要编写相当数量的相当长的代码,有时我们甚至可能需要弄乱业务逻辑。这样的代码需要仔细编写并且更难维护。不幸的是,这个困难无法解决,但结果值得麻烦,这将在下面演示。
5. 演示项目
要了解提议的设计模式在实际代码中的外观,让我们看一下简单的演示项目。该项目的目标是构建一个模拟银行一些基本功能的库。为简洁起见,它使用一组固定的账户,仅实现四种操作:查询余额、存款、取款和账户间资金转移。为了使任务更有趣,要求账户余额不能为负,也不能超过某个值。违反这些规则的交易应该被拒绝。库 API 在接口MockBank 中定义。
此接口有三种使用上述不同同步方法的实现:
- CoarseGrainedImpl使用粗粒度同步。
- FineGrainedImpl使用细粒度同步的基本版本。
- FineGrainedWithMappingImpl使用细粒度同步的内存高效版本。
还有一个对实现的性能和正确性的测试,MockBankCrashTest。每个源文件在类注释中包含算法的详细描述。多次测试运行未显示线程安全违规或死锁。在多核系统上,细粒度设计的性能是粗粒度设计的几倍,正如预期的那样。
所有项目文件都在这里。
6. 隐形锁
到目前为止,所提出的设计模式似乎可以自动解决任何同步问题。虽然这并非完全不真实,但存在一些您应该注意的问题。
上述部分中的注意事项虽然本身是正确和有效的,但并未考虑环境。通常,这是一个错误,因为我们的代码不可避免地要与操作系统和库进行交互,其中可能存在隐藏的锁,这些锁可能会干扰我们的同步代码,从而导致意外死锁。让我们看一个例子。考虑以下代码:
java:
private Hashtable<String,Long> db = new Hashtable<>();
private long version;
public void put (String key,long value) {
updateversion (key);
db. put (key,value) ;
}
public long increment (String key){
db.computeIfPresent (key,(k, v)->{
updateversion(k);
return v+1 ;
}):
}
private synchronized void updateversion (String key){
db.put (key+".version", versiontl++);
}
这么一看,这段代码应该是无死锁的,因为updateVersion(). 但是,这种印象是错误的,因为Hashtable实例中实际上存在一个额外的隐藏锁。调用链put()-updateVersion()并increment()-computeIfPresent()-updateVersion()以相反的顺序获取这两个锁,这会导致潜在的死锁。
一位有经验的读者可能会在这里正确地争辩说,上面的代码相当蹩脚,并且是故意设计来导致死锁的。然后,这里是更简洁的示例,我们尝试在映射中原子地交换两个值:
java:
private final Map<Integer,String> map = new ConcurrentHashMap<>();
map.put (1,"1");
map. put (2,“2");}
public void swapalues(Integer key1,Integer key2) {
map.compute(key1,(k1,v1) ->{
return map. put (key2, v1);
// returns v2
}):
}
这一次,根本没有锁,代码看起来完全合法,但是,我们再次遇到了潜在的死锁。原因是在内部设计ConcurrentHashMap,这已在第 2 节中概述 。以相反的顺序调用swapValues(1,2)和swapValues(2,1)获取相应桶的锁,这意味着代码可能会死锁。这就是文档 ConcurrentHashMap.compute()强烈不鼓励尝试从回调中更改地图的原因。不幸的是,在许多情况下,文档中缺少此类警告。
如上例所示,对隐藏锁的干扰最有可能发生在回调方法中。因此,建议保持回调简短、简单且不调用同步方法。如果这是不可能的,您应该始终牢记执行回调的线程可能持有一个或多个隐藏锁,并相应地计划同步。
结论
在本文中,我们探讨了多线程编程中的死锁问题。我们发现如果按照一定的设计模式编写同步代码,可以完全避免死锁。我们还研究了此类设计为何以及如何工作,其适用性的限制是什么,以及如何有效地发现和修复现有代码中的潜在死锁。预计所提供的材料为设计完美的无死锁同步提供了足够的实用指南。
所有源文件都可以作为zip 存档从 Github 下载。