如何使用 openpyxl:excel 文件的 python 模块
2021-08-24 14:06:56
浏览数 (6633)
下面,我为大家带来了一篇关于Python中用于excel文件的openpyxl模块的文章,介绍了openpyxl模块从安装到使用的一个详细过程,我们一起来学习本篇文章的内容。
在开始之前,默认各位都已经具备了以下的基础知识:
先决条件
- Python基础知识
- Excel基础知识
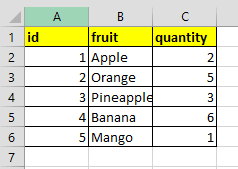
我们正在使用的示例 excel 如下:
文件名:sampleData.xlsx
Sheet1: Sheet2:

安装 Openpyxl
在 Python 终端中运行以下代码以安装openpyxl.
你可以选择 全局安装 或者在 虚拟机环境中 安装。
pip install openpyxl安装后,我们需要把openpyxl模块导入到我们的python代码中
import openpyxl 加载工作簿
用下面的代码来加载我们的第一个excel文件。
# 加载工作簿
from openpyxl import load_workbook
# 加载对应的excel文件
wb = load_workbook(filename='sampleData.xlsx')
print(wb) 在上面的代码导入load_workbook方法读取excel文件并将其存储在变量“wb”中
注意,我们正在访问的文件必须位于我们正在使用的同一文件夹中。
输出:

使用表格
下面的代码具有以下逻辑:
- 从我们读取的 excel 中获取工作表名称
- 显示哪个工作表当前处于活动状态
- 使用索引或工作表名称激活特定工作表
# 使用表格
from openpyxl import load_workbook
# 加载对应的excel文件
wb = load_workbook(filename='sampleData.xlsx')
# 获取我们从excel中读取的工作表名
print(wb.sheetnames) # OUTPUT: ['Sheet1', 'Sheet2']
# 显示当前使用的工作表
print(wb.active) # OUTPUT: <Worksheet "Sheet1">
# 我们可以指定要激活的工作表,让它从索引0,1,从左到右开始,以此类推...
wb.active = 0
print(wb.active) # OUTPUT: <Worksheet "Sheet1">
wb.active = 1
print(wb.active) # OUTPUT: <Worksheet "Sheet2">
# 使用工作表名访问工作表
sheet = wb['Sheet2']
print(sheet) # OUTPUT: <Worksheet "Sheet2">
print(sheet.title) # OUTPUT: Sheet2检索单元格值
下面的代码具有以下逻辑:
- 指定我们需要从中获取数据的工作表和单元格编号
- 获取行索引、列索引、单元格值和单元格坐标
# 检索单元格的值
from openpyxl import load_workbook
# 加载对应的excel文件
wb = load_workbook(filename='sampleData.xlsx')
sheet = wb['Sheet1']
# 从当前使用的工作表中我们尝试获取B3位置的值
cell_coordinates = sheet['B3']
# 获取单元格坐标的行和列
print(cell_coordinates.value) # OUTPUT: Jojo
print(cell_coordinates.row) # OUTPUT: 3
print(cell_coordinates.column) # OUTPUT: 2
print(cell_coordinates.coordinate) # OUTPUT: B3
# 如果获取的单元格是空的
print(sheet['B9'].value) # OUTPUT: None
# 使用单元格返回值
print(sheet.cell(row=2, column=2).value) # OUTPUT: Shijo检索多个值
下面的代码具有以下逻辑:
- 获取特定列的数据
- 获取带索引/不带索引的列对象范围
- 获取行和列对象
- 获取行和列值
# 检索多个值
from openpyxl import load_workbook
# 加载对应的excel文件
wb = load_workbook(filename='sampleData.xlsx')
sheet = wb['Sheet2']
# 获取A列所有有的数据
# 输出: (<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.A2>, <Cell 'Sheet2'.A3>, <Cell 'Sheet2'.A4>, <Cell 'Sheet2'.A5>, <Cell 'Sheet2'.A6>)
print(sheet['A'])
# 获取不带索引的列范围
print(sheet['A:C'])
'''
OUTOUT:
((<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.A2>, <Cell 'Sheet2'.A3>, <Cell 'Sheet2'.A4>, <Cell 'Sheet2'.A5>, <Cell 'Sheet2'.A6>),
(<Cell 'Sheet2'.B1>, <Cell 'Sheet2'.B2>, <Cell 'Sheet2'.B3>, <Cell 'Sheet2'.B4>, <Cell 'Sheet2'.B5>, <Cell 'Sheet2'.B6>),
(<Cell 'Sheet2'.C1>, <Cell 'Sheet2'.C2>, <Cell 'Sheet2'.C3>, <Cell 'Sheet2'.C4>, <Cell 'Sheet2'.C5>, <Cell 'Sheet2'.C6>))
'''
# 获取具有索引的列的范围
print(sheet['1:3'])
'''
输出:
((<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.B1>, <Cell 'Sheet2'.C1>),
(<Cell 'Sheet2'.A2>, <Cell 'Sheet2'.B2>, <Cell 'Sheet2'.C2>),
(<Cell 'Sheet2'.A3>, <Cell 'Sheet2'.B3>, <Cell 'Sheet2'.C3>))
'''
# 获取行和列的对象
for row in sheet.rows:
print(row)
'''
输出:
(<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.B1>, <Cell 'Sheet2'.C1>)
(<Cell 'Sheet2'.A2>, <Cell 'Sheet2'.B2>, <Cell 'Sheet2'.C2>)
(<Cell 'Sheet2'.A3>, <Cell 'Sheet2'.B3>, <Cell 'Sheet2'.C3>)
(<Cell 'Sheet2'.A4>, <Cell 'Sheet2'.B4>, <Cell 'Sheet2'.C4>)
(<Cell 'Sheet2'.A5>, <Cell 'Sheet2'.B5>, <Cell 'Sheet2'.C5>)
(<Cell 'Sheet2'.A6>, <Cell 'Sheet2'.B6>, <Cell 'Sheet2'.C6>)
'''
for col in sheet.columns:
print(col)
'''
输出:
(<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.A2>, <Cell 'Sheet2'.A3>, <Cell 'Sheet2'.A4>, <Cell 'Sheet2'.A5>, <Cell 'Sheet2'.A6>)
(<Cell 'Sheet2'.B1>, <Cell 'Sheet2'.B2>, <Cell 'Sheet2'.B3>, <Cell 'Sheet2'.B4>, <Cell 'Sheet2'.B5>, <Cell 'Sheet2'.B6>)
(<Cell 'Sheet2'.C1>, <Cell 'Sheet2'.C2>, <Cell 'Sheet2'.C3>, <Cell 'Sheet2'.C4>, <Cell 'Sheet2'.C5>, <Cell 'Sheet2'.C6>)
'''
# 仅显示值
for row in sheet.iter_rows(values_only=True):
print(row)
'''
输出:
('id', 'fruit', 'quantity')
(1, 'Apple', 2)
(2, 'Orange', 5)
(3, 'Pineapple', 3)
(4, 'Banana', 6)
(5, 'Mango', 1)
'''
for col in sheet.iter_cols(values_only=True):
print(col)
'''
OUTPUT:
('id', 1, 2, 3, 4, 5)
('fruit', 'Apple', 'Orange', 'Pineapple', 'Banana', 'Mango')
('quantity', 2, 5, 3, 6, 1)
'''
将数据转换为 Python 结构
# 将数据转换为Python结构
import json
from openpyxl import load_workbook
# 加载对应的excel文件
wb = load_workbook(filename='sampleData.xlsx')
sheet = wb['Sheet2']
# 保留excel中的值的空字典
books = {}
for row in sheet.iter_rows(min_row=2, min_col=1, values_only=True):
book_id = row[0]
book = {
'Fruit': row[1],
'Qty': row[2]
}
books[book_id] = book
print(json.dumps(books, indent=3))
'''
输出:
{
"1": {
"Fruit": "Apple",
"Qty": 2
},
"2": {
"Fruit": "Orange",
"Qty": 5
},
"3": {
"Fruit": "Pineapple",
"Qty": 3
},
"4": {
"Fruit": "Banana",
"Qty": 6
},
"5": {
"Fruit": "Mango",
"Qty": 1
}
}
'''