Python包使用:使用 Faker 生成有意义的模拟数据
2021-09-07 10:25:32
浏览数 (5881)
Faker是一个开源 Python 包,可生成合成数据,可用于多种用途,例如填充数据库、进行负载测试或匿名化生产数据以用于开发或机器学习。生成完全随机的数据并不是一个好的选择:使用 Faker,你可以驱动生成过程并根据你的特定需求定制生成的数据:这是 Faker 提供的最大价值。这个包带有 23 个内置的数据提供者,一些其他的提供者可以从社区获得。可用的数据提供程序涵盖了大多数数据类型和案例,但通过实现自定义提供程序,可以通过任何方式使生成的数据更有意义。
Faker 支持 Python 3.6+,可通过 PyPI 或 Anaconda 安装。
下面是一个代码示例,展示了如何实现自定义提供程序以生成遵循结构和约束的合成数据,如与具有消费者评级的餐厅数据相关的Kaggle数据集,并将它们保存到 CSV 文件中。
示例数据集包含用户配置文件数据并具有 19 个特征。为简单起见,我将只考虑其中的 10 个:
- userID:以“U”开头,后跟 4 位数字
- latitude:-90、90度范围内的十进制数
- longitude:-180、180度范围内的十进制数
- smoker:可真可假
- Drink_level: 节制的、随意的饮酒者或社交饮酒者
- dress_preference:无偏好,正式或非正式
- ambience:孤独、家人或朋友
- transport:步行、车主或公众
- marital_status:单身、已婚或寡妇
- hijos:独立、依赖或孩子
可以为此功能生成模拟数据的 Python 代码如下:
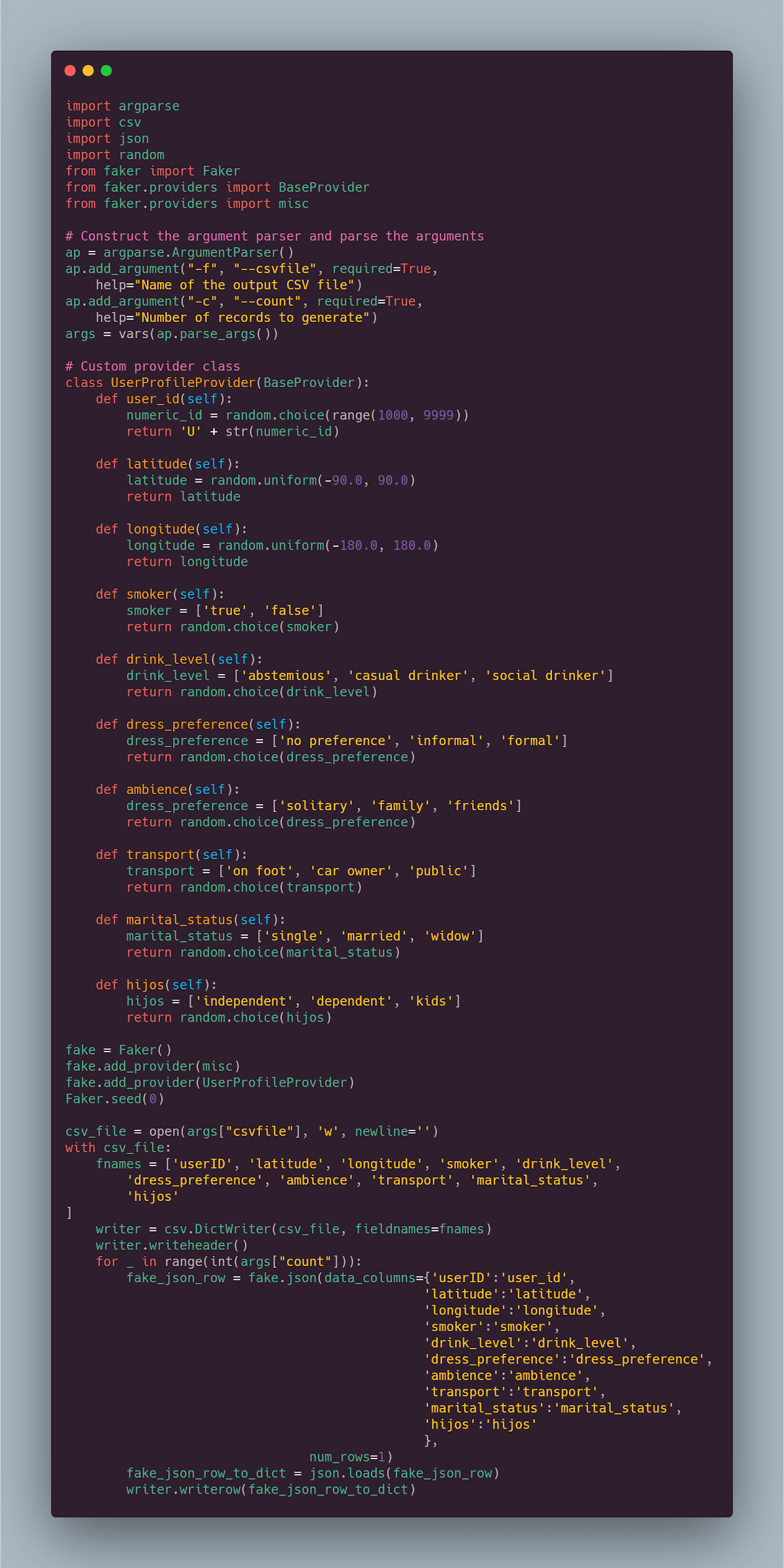
它结合了一个内置的 Faker 提供程序和一个自定义的提供程序。该 Faker 类创建并初始化 Faker 生成器,将数据生成委托给提供程序。
以下是执行上述代码后生成的数据示例:
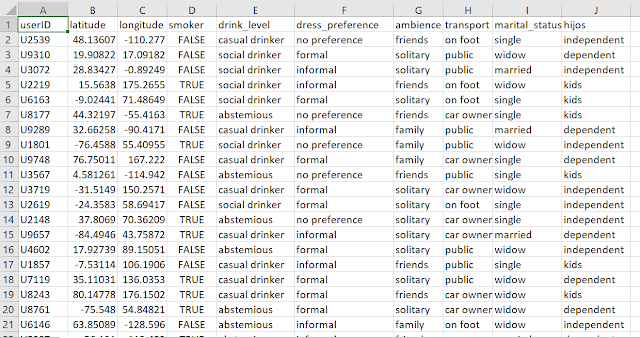
Faker 支持本地化(对于同一数据生成任务也有多个语言环境),并且也可以通过faker命令从命令行执行。