Python怎么实现自动提取并收集信息?
2021-08-03 15:26:12
浏览数 (4974)
在日常生活中我们可能需要批量收集一些图片内的信息(比如从截图中收集信息),这时候我们可以使用python来进行信息提取。一种可行的方案是使用OpenCV对目标图片的特定内容进行裁剪,然后使用python文字识别的方式获取裁剪图片的文字内容,最后使用python对这些数据进行一个收集整理。那么具体怎么操作呢?接下来这篇文章告诉你。
一、简介
- 本功能目的在于提取收据/发票上的信息,用机器代替人的方式,提高工作效率
- 实现方式是通过cv2模块截取需要的信息,调用百度的api文字识别接口

二、代码实现
1.导入需要的库,包括百度的api接口跟cv2图像截图图库
import cv2
from aip import AipOcr
# 读取图片,利用imshow显示图片
pic = cv2.imread(r'Y:cutimg1.png')
pic = cv2.resize(pic,None,fx = 0.5, fy = 0.5)
cv2.imshow('img',pic)
cv2.waitKey(0)
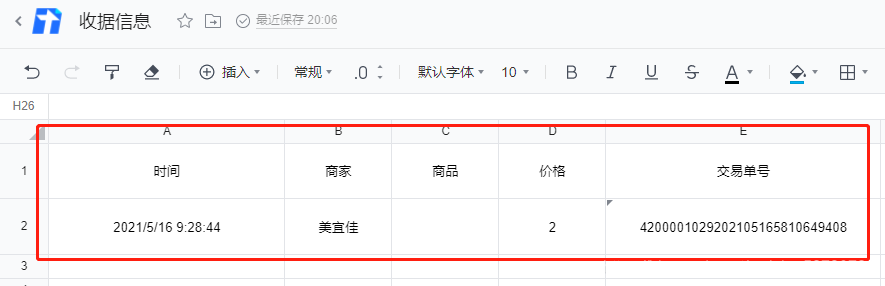
2.截取图片,获取需要的信息,包括以下信息
- 时间Time
- 商家business
- 商品goods
- 价格money
- 单号num
# 删除不必要的部分
img = pic[210:500, 100:580]
# 截取各部分的文字
time = pic[400:430, 100:580]
business = pic[370:400, 100:580]
goods = pic[350:380, 100:580]
money = pic[210:300, 100:580]
num = pic[460:500, 100:580]
# 查看截取的部分是否合适
gener_name = ['time','business','goods','money','num']
excel_data = {}
pd_columns = ["a","b","c","d","e"] # 标题




3.定义函数将截取好的图片另存到文件夹
def shotcut_image(args):
for index in gener:
cv2.imwrite('image/{}.png'.format(args), img)4.调用百度api接口,实现文字识别
# 导入api
AppID = '24177719'
API_Key = 'p8skmRYfHGoVGR4UU03Q5jiM'
Secret_Key = 'dyM0tzSILBZu9CFqZ7IkjWwECGaws4xo'
cilent = AipOcr(AppID,API_Key,Secret_Key)
def get_words(img_name):
with open('image/{}.png'.format(img_name), 'rb') as f:
result = cilent.basicAccurate(f.read())
return result
5.最后将信息转为Dataframe,利用pandas的to_exccel功能,将数据放到excel里面
def convert_to_dataframe(words):
# 构建dataframe
result = words['words_result']
for word in result:
excel_data.setdefault('a', []).append(word['words'])
# 将所有words读取后,取出语句存入excel
def convert_to_excel():
frame = DataFrame(excel_data, columns=pd_columns)
# todo 表头需要额外处理,这里指定不设置表头
frame.to_excel('out.xls',index=False, header=False)
到此这篇python信息提取和python文字识别的应用介绍就介绍到这了。更多Python学习内容请搜索W3Cschool以前的文章或继续浏览下面的相关文章。