利用Python爬取当当、京东、亚马逊图书信息代码实例源码
2021-01-18 18:09:41
浏览数 (6686)
本文主要介绍了利用 Python 来爬取当当、京东、亚马逊平台上的图书信息代码实例,具有一定借鉴价值,正在学习Python爬虫 或正好有需要的朋友可以参考下。
注:
1.本程序采用 MSSQLserver 数据库存储,请运行程序前手动修改程序开头处的数据库链接信息;
2.需要 bs4、requests、pymssql 库支持;
3.支持多线程。
源码
from bs4 import BeautifulSoup
import re,requests,pymysql,threading,os,traceback
try:
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root', db='book',charset="utf8")
cursor = conn.cursor()
except:
print('\\\\n错误:数据库连接失败')
#返回指定页面的html信息
def getHTMLText(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
r = requests.get(url,headers = headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
#返回指定url的Soup对象
def getSoupObject(url):
try:
html = getHTMLText(url)
soup = BeautifulSoup(html,'html.parser')
return soup
except:
return ''
#获取该关键字在图书网站上的总页数
def getPageLength(webSiteName,url):
try:
soup = getSoupObject(url)
if webSiteName == 'DangDang':
a = soup('a',{'name':'bottom-page-turn'})
return a[-1].string
elif webSiteName == 'Amazon':
a = soup('span',{'class':'pagnDisabled'})
return a[-1].string
except:
print('\\\\n错误:获取{}总页数时出错...'.format(webSiteName))
return -1
class DangDangThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\\\\n提示:开始爬取当当网数据...')
count = 1
length = getPageLength('DangDang','http://search.dangdang.com/?key={}'.format(self.keyword))#总页数
tableName = 'db_{}_dangdang'.format(self.keyword)
try:
print('\\\\n提示:正在创建DangDang表...')
cursor.execute('create table {} (id int ,title text,prNow text,prPre text,link text)'.format(tableName))
print('\\\\n提示:开始爬取当当网页面...')
for i in range(1,int(length)):
url = 'http://search.dangdang.com/?key={}&page_index={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'class':re.compile(r'line'),'id':re.compile(r'p')})
for li in lis:
a = li.find_all('a',{'name':'itemlist-title','dd_name':'单品标题'})
pn = li.find_all('span',{'class': 'search_now_price'})
pp = li.find_all('span',{'class': 'search_pre_price'})
if not len(a) == 0:
link = a[0].attrs['href']
title = a[0].attrs['title'].strip()
else:
link = 'NULL'
title = 'NULL'
if not len(pn) == 0:
prNow = pn[0].string
else:
prNow = 'NULL'
if not len(pp) == 0:
prPre = pp[0].string
else:
prPre = 'NULL'
sql = "insert into {} (id,title,prNow,prPre,link) values ({},'{}','{}','{}','{}')".format(tableName,count,title,prNow,prPre,link)
cursor.execute(sql)
print('\\\\r提示:正在存入当当数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except:
pass
class AmazonThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\\\\n提示:开始爬取亚马逊数据...')
count = 1
length = getPageLength('Amazon','https://www.amazon.cn/s/keywords={}'.format(self.keyword))#总页数
tableName = 'db_{}_amazon'.format(self.keyword)
try:
print('\\\\n提示:正在创建Amazon表...')
cursor.execute('create table {} (id int ,title text,prNow text,link text)'.format(tableName))
print('\\\\n提示:开始爬取亚马逊页面...')
for i in range(1,int(length)):
url = 'https://www.amazon.cn/s/keywords={}&page={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'id':re.compile(r'result_')})
for li in lis:
a = li.find_all('a',{'class':'a-link-normal s-access-detail-page a-text-normal'})
pn = li.find_all('span',{'class': 'a-size-base a-color-price s-price a-text-bold'})
if not len(a) == 0:
link = a[0].attrs['href']
title = a[0].attrs['title'].strip()
else:
link = 'NULL'
title = 'NULL'
if not len(pn) == 0:
prNow = pn[0].string
else:
prNow = 'NULL'
sql = "insert into {} (id,title,prNow,link) values ({},'{}','{}','{}')".format(tableName,count,title,prNow,link)
cursor.execute(sql)
print('\\\\r提示:正在存入亚马逊数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except:
pass
class JDThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\\\\n提示:开始爬取京东数据...')
count = 1
tableName = 'db_{}_jd'.format(self.keyword)
try:
print('\\\\n提示:正在创建JD表...')
cursor.execute('create table {} (id int,title text,prNow text,link text)'.format(tableName))
print('\\\\n提示:开始爬取京东页面...')
for i in range(1,100):
url = 'https://search.jd.com/Search?keyword={}&page={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'class':'gl-item'})
for li in lis:
a = li.find_all('div',{'class':'p-name'})
pn = li.find_all('div',{'class': 'p-price'})[0].find_all('i')
if not len(a) == 0:
link = 'http:' + a[0].find_all('a')[0].attrs['href']
title = a[0].find_all('em')[0].get_text()
else:
link = 'NULL'
title = 'NULL'
if(len(link) > 128):
link = 'TooLong'
if not len(pn) == 0:
prNow = '¥'+ pn[0].string
else:
prNow = 'NULL'
sql = "insert into {} (id,title,prNow,link) values ({},'{}','{}','{}')".format(tableName,count,title,prNow,link)
cursor.execute(sql)
print('\\\\r提示:正在存入京东网数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except :
pass
def closeDB():
global conn,cursor
conn.close()
cursor.close()
def main():
print('提示:使用本程序,请手动创建空数据库:Book,并修改本程序开头的数据库连接语句')
keyword = input("\\\\n提示:请输入要爬取的关键字:")
dangdangThread = DangDangThread(keyword)
amazonThread = AmazonThread(keyword)
jdThread = JDThread(keyword)
dangdangThread.start()
amazonThread.start()
jdThread.start()
dangdangThread.join()
amazonThread.join()
jdThread.join()
closeDB()
print('\\\\n爬取已经结束,即将关闭....')
os.system('pause')
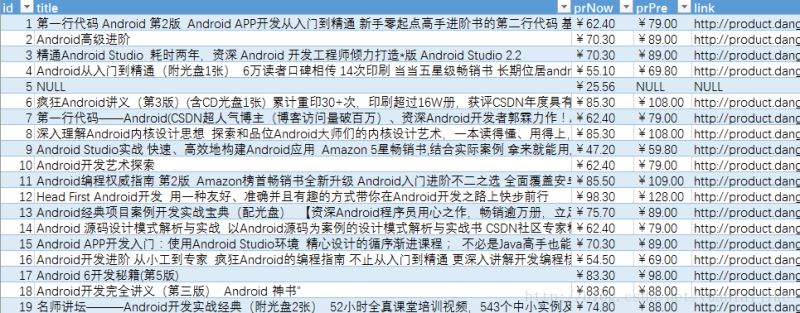
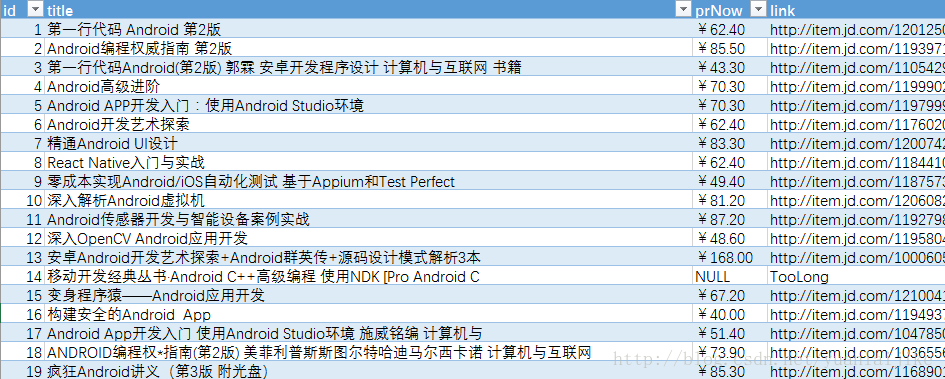
main() 示例截图:
关键词:Android 下的部分运行结果(以导出至 Excel )

总结
以上就是编程狮(w3cschool.cn) 为你整理的关于Python爬取当当、京东、亚马逊图书信息代码实例的全部内容,希望对大家有所帮助。