Redis分布式锁如何实现 ?
在分布式系统中,保证数据一致性和并发控制是至关重要的挑战之一。分布式锁是一种常用的解决方案,而Redis作为一个快速、可靠的内存数据库,提供了实现分布式锁的有效方法。本文将介绍Redis分布式锁的实现原理和使用方法,以确保数据一致性并控制并发访问,帮助读者理解和应用这一关键技术。
Redis分布式锁主要依靠一个 SETNX 指令实现的 , 这条命令的含义就是“SET if Not Exists”,即不存在的时候才会设置值。只有在key不存在的情况下,将键key的值设置为value。如果key已经存在,则SETNX命令不做任何操作。这个命令的返回值如下:
- 命令在设置成功时返回1。
- 命令在设置失败时返回0。
假设此时有线程A和线程B同时访问临界区代码,假设线程A首先执行了SETNX命令,并返回结果1,继续向下执行。而此时线程B再次执行SETNX命令时,返回的结果为0,则线程B不能继续向下执行。只有当线程A执行DELETE命令将设置的锁状态删除时,线程B才会成功执行SETNX命令设置加锁状态后继续向下执行
Boolean isLocked = stringRedisTemplate.opsForValue().setIfAbsent(PRODUCT_ID, "binghe");当然我们在使用分布式锁的时候也不能这么简单, 会考虑到一些实际场景下的问题 , 例如 :
- 死锁问题:在使用分布式锁的时候, 如果因为一些原因导致系统宕机, 锁资源没有被释放, 就会产生死锁,解决的方案 : 上锁的时候设置锁的超时时间
Boolean isLocked = stringRedisTemplate.opsForValue().setIfAbsent(PRODUCT_ID, "binghe", 30, TimeUnit.SECONDS);- 锁超时问题:如果业务执行需要的时间, 超过的锁的超时时间 , 这个时候业务还没有执行完成, 锁就已经自动被删除了 ,其他请求就能获取锁, 操作这个资源 , 这个时候就会出现并发问题 , 解决的方案 :
1.引入Redis的watch dog机制, 自动为锁续期
2.开启子线程 , 每隔20S运行一次, 重新设置锁的超时时间
- 归一问题:如果一个线程获取了分布式锁, 但是这个线程业务没有执行完成之前 , 锁被其他的线程删掉了, 又会出现线程并发问题 , 这个时候就需要考虑归一化问题,就是一个线程执行了加锁操作后,后续必须由这个线程执行解锁操作,加锁和解锁操作由同一个线程来完成。为了解决只有加锁的线程才能进行相应的解锁操作的问题,那么,我们就需要将加锁和解锁操作绑定到同一个线程中,可以使用ThreadLocal来解决这个问题 , 加锁的时候生成唯一标识保存到ThreadLocal , 并且设置到锁的值中 , 释放锁的时候, 判断线程中的唯一标识和锁的唯一标识是否相同, 只有相同才会释放。
public class RedisLockImpl implements RedisLock{
@Autowired
private StringRedisTemplate stringRedisTemplate;
private ThreadLocal<String> threadLocal = new ThreadLocal<String>();
@Override
public boolean tryLock(String key, long timeout, TimeUnit unit){
String uuid = UUID.randomUUID().toString();
threadLocal.set(uuid);
return stringRedisTemplate.opsForValue().setIfAbsent(key, uuid,timeout, unit);
}
@Override
public void releaseLock(String key){
//当前线程中绑定的uuid与Redis中的uuid相同时,再执行删除锁的操作
if(threadLocal.get().equals(stringRedisTemplate.opsForValue().get(key))){
stringRedisTemplate.delete(key);
}
}
}- 可重入问题:当一个线程成功设置了锁标志位后,其他的线程再设置锁标志位时,就会返回失败。还有一种场景就是在一个业务中, 有个操作都需要获取到锁, 这个时候第二个操作就无法获取锁了 , 操作会失败
例如 : 下单业务中, 扣减商品库存会给商品加锁, 增加商品销量也需要给商品加锁 , 这个时候需要获取二次锁。第二次获取商品锁就会失败 , 这就需要我们的分布式锁能够实现可重入。实现可重入锁最简单的方式就是使用计数器 , 加锁成功之后计数器+ 1 , 取消锁之后计数器
-1 , 计数器减为0 , 真正从Redis删除锁。
public class RedisLockImpl implements RedisLock{
@Autowired
private StringRedisTemplate stringRedisTemplate;
private ThreadLocal<String> threadLocal = new ThreadLocal<String>();
private ThreadLocal<Integer> threadLocalInteger = new ThreadLocal<Integer>();
@Override
public boolean tryLock(String key, long timeout, TimeUnit unit){
Boolean isLocked = false;
if(threadLocal.get() == null){
String uuid = UUID.randomUUID().toString();
threadLocal.set(uuid);
isLocked = stringRedisTemplate.opsForValue().setIfAbsent(key,uuid, timeout, unit);
}else{
isLocked = true;
}
//加锁成功后将计数器加1
if(isLocked){
Integer count = threadLocalInteger.get() == null ? 0 :threadLocalInteger.get();
threadLocalInteger.set(count++);
}
return isLocked;
}
@Override
public void releaseLock(String key){
//当前线程中绑定的uuid与Redis中的uuid相同时,再执行删除锁的操作
if(threadLocal.get().equals(stringRedisTemplate.opsForValue().get(key))){
Integer count = threadLocalInteger.get();
//计数器减为0时释放锁
if(count == null || --count <= 0){
stringRedisTemplate.delete(key);
}
}
}
}- 阻塞与非阻塞问题:在使用分布式锁的时候 , 如果当前需要操作的资源已经加了锁, 这个时候会获取锁失败, 直接向用户返回失败信息 , 用户的体验非常不好 , 所以我们在实现分布式锁的时候, 我们可以将后续的请求进行阻塞,直到当前请求释放锁后,再唤醒阻塞的请求获得分布式锁来执行方法。具体的实现就是参考自旋锁的思想, 获取锁失败自选获取锁, 直到成功为止 , 当然为了防止多条线程自旋带来的系统资料消耗, 可以设置一个自旋的超时时间 , 超过时间之后, 自动终止线程 , 返回失败信息。
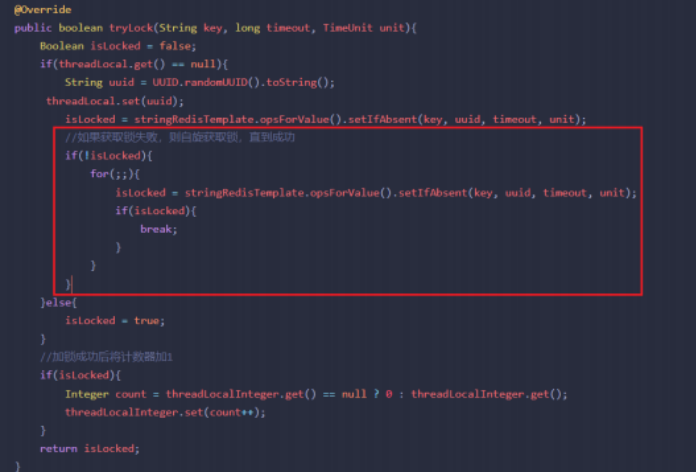
总结
Redis分布式锁是一种强大的工具,用于确保在分布式系统中数据的一致性和并发控制。通过Redis的SETNX命令和过期时间的设置,我们可以实现简单而有效的分布式锁机制。然而,在使用Redis分布式锁时,我们需要注意原子性、异常处理和适当的配置等方面,以确保锁的可靠性和系统的稳定性。在实际应用中,根据业务需求选择合适的过期时间和锁的管理策略,并考虑使用更复杂的算法和工具来增强分布式锁的功能。通过合理的设计和使用,Redis分布式锁将成为分布式系统中实现数据一致性和并发控制的重要利器。

如果你对编程知识和相关职业感兴趣,欢迎访问编程狮官网(https://www.w3cschool.cn/)。在编程狮,我们提供广泛的技术教程、文章和资源,帮助你在技术领域不断成长。无论你是刚刚起步还是已经拥有多年经验,我们都有适合你的内容,助你取得成功。