关于RavenDB中的递归索引的使用方法分享!
2021-09-24 16:17:52
浏览数 (4802)
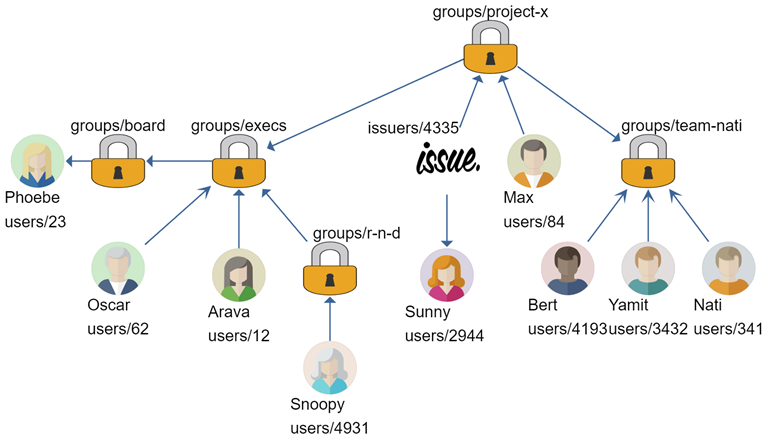
在这篇文章中,我想展示另一种处理相同问题的方法,但不使用图形查询,只使用我们在 RavenDB 4.1 中的功能。
这个想法是,给定一个用户,我希望能够对该用户有权访问的所有问题发出查询,要么直接(如图中的 Sunny),要么通过一个组(如 Max,通过 project-x 组) ) 或通过递归组,例如 (Nati,通过 project-x –> team-nati 组)。
从这篇文章的名称可以想象,这需要递归。您可以阅读有关此的文档,但我想增加一些趣味并同时使用多个功能。
我们来看下面的索引(Issues/Permissions):
// Issues/Permissions index definition
map("Issues", issue =>{
var groups = issue.Groups.reduce(recurse_groups, {});
return { Groups: Object.keys(groups), Users: issue.Users };
});
function recurse_groups(accumulator, grpId) {
if(grpId == null || accumulator.hasOwnProperty(grpId))
return accumulator;
accumulator[grpId] = null;
var grp = load(grpId, "Groups");
if(grp == null || grp.Parents == null)
return accumulator;
return grp.Parents.reduce(recurse_groups, accumulator);
}这是一个 JS 索引,它在 Issues 集合上有一个 map() 函数。对于每个问题,我们为问题的用户和允许访问它的组(递归地)编制索引。
对于图中的问题,此索引的输出如下:

现在让我们看看如何查询这个。

这个查询有两个子句;要么直接分配给我们,要么通过一个小组分配给我们。这里的关键是在recurse_groups () 和里面,索引中的load()调用。它向上扫描定义的组及其父级,直到我们在索引中有一个易于搜索的简单结构。
RavenDB 将确保每当索引中的load()引用的文档被更新时,所有引用它的文档都将被重新索引。在我们这里的情况下,每当更新组时,我们都会重新索引所有相关问题以匹配新的权限结构。
RavenDB 的核心原则之一是您可以将更多工作推向索引并保持查询快速和简单。这是一个很好的例子,说明我们如何以一种非常优雅的方式将工作推送到后台索引的方式排列数据。