怎么使用Python根据模板批量生成docx文档
2021-08-18 14:39:04
浏览数 (6002)
有些word文档的内容有相当大一部分是完全相同的,只有部分的内容有所更改,比如成绩单、录取通知书等。这些文档如果使用手工一个一个去创建的话是一件相当大的工程。如果能根据模板批量生产docx文档就好了。这样的美梦,已经可以用python实现了,接下来,我们就来了解如何用python根据模板批量生成docx文档。
一、需求说明
能够根据模板批量生成docx文档。具体而言,读取excel中的数据,然后使用python批量生成docx文档。
二、实验准备
准备excel数据:
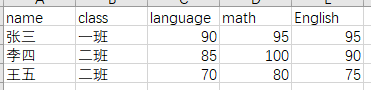
这里是关于学生语数英成绩的统计表,文件名为score.xls
准备模板:

这是给学生家长的成绩通知书,文件名为template.doc
另外,在使用python进行实验之前,需要先安装第三方库docxtpl和xlrd,直接pip install就行:
pip install docxtpl pip install xlrd
然后将xls和doc和python文件放在同一个目录下
三、代码实现
首先打开xls,读取数据:
workbook = xlrd.open_workbook(sheet_path)然后从文件中获取第一个表格:
sheet = workbook.sheet_by_index(0)然后遍历表格的每一行,将数据存入字典列表:
tables = []
for num in range(1, sheet.nrows):
stu = {}
stu['name'] = sheet.cell_value(num, 0)
stu['class'] = sheet.cell_value(num, 1)
stu['language'] = sheet.cell_value(num, 2)
stu['math'] = sheet.cell_value(num, 3)
stu['English'] = sheet.cell_value(num, 4)
tables.append(stu)
接下来将列表中的数据写入docx文档,其实这个过程可以在读数据时同时进行,即读完一行数据,然后生成一个文档。
首先在指定路径生成一个docx文档:
document = Document(word_path)然后逐行进行正则表达式的替换:
paragraphs = document.paragraphs
text = re.sub('name', stu['name'], paragraphs[1].text)
paragraphs[1].text = text
text = re.sub('name', stu['name'], paragraphs[2].text)
text = re.sub('class', stu['class'], text)
text = re.sub('language', str(stu['language']), text)
text = re.sub('math', str(stu['math']), text)
text = re.sub('English', str(stu['English']), text)
paragraphs[2].text = text
其实不关心格式问题的,到现在为止就已经结束了。但是这样替换后docx中被替换的文字格式也被更改为系统默认的正文格式,所以接下来是将这些改成自己想要的格式:
遍历需要更改格式的段落,然后更改字体大小和字体格式:
for run in paragraph.runs:
run.font.size = Pt(16)
run.font.name = "宋体"
r = run._element.rPr.rFonts
r.set(qn("w:eastAsia"), "宋体")
最后保存文件:
document.save(path + "\" + r"{}的成绩通知单.docx".format(stu['name']))完整代码:
from docxtpl import DocxTemplate
import pandas as pd
import os
import xlrd
path = os.getcwd()
# 读表格
sheet_path = path + "score.xls"
workbook = xlrd.open_workbook(sheet_path)
sheet = workbook.sheet_by_index(0)
tables = []
for num in range(1, sheet.nrows):
stu = {}
stu['name'] = sheet.cell_value(num, 0)
stu['class'] = sheet.cell_value(num, 1)
stu['language'] = sheet.cell_value(num, 2)
stu['math'] = sheet.cell_value(num, 3)
stu['English'] = sheet.cell_value(num, 4)
tables.append(stu)
print(tables)
# 写文档
from docx import Document
import re
from docx.oxml.ns import qn
from docx.shared import Cm,Pt
for stu in tables:
word_path = path + "\template.doc"
document = Document(word_path)
paragraphs = document.paragraphs
text = re.sub('name', stu['name'], paragraphs[1].text)
paragraphs[1].text = text
text = re.sub('name', stu['name'], paragraphs[2].text)
text = re.sub('class', stu['class'], text)
text = re.sub('language', str(stu['language']), text)
text = re.sub('math', str(stu['math']), text)
text = re.sub('English', str(stu['English']), text)
paragraphs[2].text = text
for paragraph in paragraphs[1:]:
for run in paragraph.runs:
run.font.size = Pt(16)
run.font.name = "宋体"
r = run._element.rPr.rFonts
r.set(qn("w:eastAsia"), "宋体")
document.save(path + "\" + r"{}的成绩通知单.docx".format(stu['name']))
四、实验结果
文件中的文件:
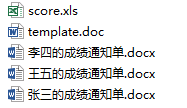
生成的文件样例:

到此这篇如何用python根据模板批量生成docx文档的文章就介绍到这了,更多Python批量处理操作请搜索W3Cschool以前的文章或继续浏览下面的相关文章。