
Ada标量类型
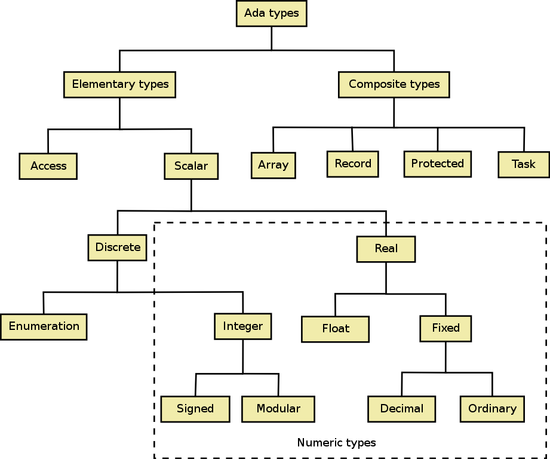
大部份语言,基本的数据类型如果按照该类型所表示的数据类型来分,一般来说可分为整型(integer),实型(real),布尔型(boolean),字符型(character)这四类,并以它们为基础构成了数组,记录等其它更复杂的数据类型。在程序包 Standard 中预定义了一些简单数据类型,例如Integer,Long_Integer,Float,Long_Float,Boolean,Character,Wide_Character,以及这些数据类型的运算符。下面我们除了学习上述的4种标量类型(Scalar Type)外,还要学习一下枚举类型(Enumration)。由于 Ada 中布尔型和字符型都是由枚举类型实现的,因此也可将这两种类型认为是枚举类型。
整型(Integer)
Integer 整型
一个整型数据能存放一个整数。预定义的整型有Integer,Short_Integer,Short_Short_Integer,Long_Integer,Long_Long_Integer还有Integer的子类型 Positive ,Natural。RM95 没有规定 Integer及其它整型的具体取值范围及其位数,由编译器决定。只规定了没多大意思的最小取值范围,如要求一个Integer 至少要为16位数,最小取值范围为-32767..32767(-2 ** 15+1 .. 2**15-1)。因此还有Integer_8,Integer_16,Integer_32,Integer_64这些指定了位数的整型,以方便用户。在RM95里,也就是编译器实现里,以上类型声明格式为:
type Integer is range implementation_defined(Long_Integer它们也一样)
subtype Positive is Integer range 1..Integer'Last;
subtype Natural is Integer range 0..Integer'Last; (Integer'Last 表示Integer的最后一个值,即上限,见2.5 数据类型属性)
程序 System 里定义了整数的取值范围:
type Integer is range implementation_defined(Long_Integer它们也一样)
subtype Positive is Integer range 1..Integer'Last;
Modular 整型
还有一类整型是 Modular,异于上面的整型。如果将 Integer 整型与 C 中的 signed int 相类比,它们的取值范围可包括负数;那么 Modular 类型就是unsigned int,不能包含负数。其声明格式为:
type tyep_name is mod range_specification;
其中的 range_specification 应为一个正数; type_name 的取值范围为(0..range_specification - 1)。
如下面类型 Byte:
type Byte is mod 256;
这里 Byte 的取值范围为 0 .. 255。
Modular 类型在程序包 System 也有常量限制,range_specification 如是2的幂则不能大于 Max_Binary_Modulus ,如不是幂的形式则不能大于Max_Nonbinary_Modulus。 这两个常量的声明一般如下:
Max_Binary_Modulus : constant := 2 ** Long_Long_Integer'Size;
Max_Nonbinary_Modulus : constant := Integer'Last;
诸位可能会发现上面两个常量的值实际上是不一样的,也就是说 Modular 类型实际上有两个不同的限制。RM95 关于这点的解释是,2进制兼容机上,Max_Nonbinary_Modulus 的值大于 Max_int 很难实现。
实型(Real)
相对于整型表示整数,实型则表示浮点数。实型分为两大类: 浮点类型(floating point) 和定点类型 (fixed point)。它们之间的区别在于浮点类型有一个相对误差;定点类型则有一个界定误差,该误差的绝对值称为 delta。下面就分类介绍这两类数据类型。
浮点类型
浮点类型预定义的有Float,Short_Float,Short_Short_Float,Long_Float,Long_Long_Float等,它们的声明格式入下:
type type_name is digits number [range range_specification] ;
digits number 表示这个浮点类型精度,即取 number 位有效数字,因此 number 要大于0;range range_specification 是可选的,表示该类型的取值范围。下面是几个例子:
type Real is digits 8;
type Mass is digits 7 range 0.0 .. 1.0E35;
subtype Probability is Real range 0.0 .. 1.0;
Real 表示精度为8位的符点数类型,它的取值范围由于没给定,实际上由编译器来决定;RM 95里关于这种情况是给出了安全范围(safe range), 取值范围是-10.0**(4*D) .. +10.0**(4*D), D 表示精度,此例中为8,所以 Real 的安全取值范围一般来说应为 -10.0E32 .. +10.0E32。
Mass 是表示精度为7位的符点型,取值范围为 00.. 1.0E35;
Probability 是Real的子类型,精度也是8位,取值范围 0.0..1.0;
程序包 System 定义了精度的两个上限:Max_Base_Digits 和 Max_Digits ,一般来说应为
Max_Base_Digits : constant := Long_Long_Float'digits;(即Long_Long_Float的精度)
Max_Digits : constant := Long_Long_Float'digits;
当range_specification指定时,所定义类型的精度不能大于 Max_Base_Digits;当range_specification没有指定时,所定义类型的精度不能大于 Max_Digits。
定点类型
定点类型主要是多了一个delta,它表示该浮点类型的绝对误差。比方说美元精确到 0.01 元(美分),则表示美元的数据类型 Dollar 的 delta 为 0.01,不像浮点型是近似到 0.01。
定点型的声明格式有两种:
普通定点型:type type_name is delta delta_number_range range_specification;
十进制定点型:type type_name is delta delta_number digits digit_number [rangerange_specification];
除 delta delta_number 外,各部份意义与浮点型相同。
定点型中有一个 small 的概念。定点数由一个数字的整数倍组成,这个数字就称为该定点数类型的 small。如果是普通定点型,则 small 的值可以被用户指定(见下节 数据类型属性),但不能大于该类型的 delat;如果没有指定,small 值由具体实现决定,但不能大于 delta。如果是十进制定点型,则 small 值为 delta,delta 应为 10 的幂,如果指定了该定点型的取值范围,则范围应在 -(10**digits-1)*delta..+(10**digits-1)*delta 之间。看一下下例:
type Volt is delta 0.125 range 0.0..255.0;
type Fraction is delta System.Fine_Delta range -1.0..1.0;
type Money is delta 0.01 digits 15;
subtype Salary is Money digits 10;
布尔型(Boolean)
逻辑运算通常需要表示"是"和"非"这两个值,这时就需要使用布尔型。Ada 中的布尔型与 Pascal 中的类似,是 True 和 False 两个值。布尔型属于枚举数据类型,它在程序包 Standard 中定义如下:
type Boolean is (True, False);
习惯于 C 语言的朋友在这里需要注意一下,Boolean 的两个值 True,False 和整型没有什么关系,而不是 C 语言中往往将True 定义为值1,False 为2。
字符型(Character)
Ada83 最初只支持 7 位字符. 这条限制在 Ada95 制订前已经放松了,但一些老编译器如 Meridian Ada 还是强制执行. 这导致在一台PC上显示图形字符时出现问题;因此,在一般情况下,是使用整型来显示 Ascii 127以后的字符,并使用编译器厂商提供的特殊函数。
在 Ada95 里,基本字符集已由原来的ISO 646 标准的7位字符变为ISO 8859标准的8位字符,基于 Latin-1并且提供了 256 个字符位置。 Ada95 同样也支持宽字符 ISO 10646,有2**16个的字符位置。因此现代编译器能很好地处理 8 位字符和 16 位字符。
7 位字符在已经废弃的程序包 Standard.Ascii 内定义。在程序包 Standard 内预定义的字符型 Character 和 Wide_Character 分别表示Latin-1 字符集和宽字符集,类型 Wide_Character 已经包含了类型 Character 并以它作为前 256 个字符。程序包 Ada.Characters.Latin_1和Ada.Characters.Wide_Latin_1 提供了 Latin-1 字符集的可用名称,Ada.Characters.Handling 则提供一些基本的字符处理函数。
从下例可以了解一下字符型:
000 -- filename: puta.adb
001 with Ada.Text_IO; use Ada.Text_IO;
002 procedure puta is
003 subtype Small_Character is {'a' ,'b','c', 'd'};
004 Level : Small_Character := 'a';
005 begin
006 Put ("You level is");
007 Put (Level);
008 New_Line;
009 end puta;
[003] 创建了一个字符类型 Small_Character,包含 a,b,c,d四个字母;如 C 语言一样,使用字符时需加' '。
[004]声明变量 Level,类型为Small_Character,值为字母 a 。
上面这个例子主要还是说明一下字符类是怎样定义的,但 Character和Wide_Chracter 实际实现却不是这么简单。
枚举类型(Enumeration)
有时候我们需要一个变量能表示一组特定值中的一个。如 today 这个变量,我们希望它的值是Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday其中的一个,这时枚举类型就相当有用,上述情况中就可以创建新类型 Day,如下:
type Day is ( Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday);
然后声明变量 today 的数据类型为 Day:
today : Day ;
这样today 就能接受Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday这几个值中的任意一个。
前面提及的类型 Character ,Wide_Character,Boolean 都是枚举类型,也按照下面给出的格式声明:
type type_name is (elememt_list);
element_list 需列举出该类型所有的可能值。
Ada 能自动检测上下文,因此大部份情况下能分辨不同枚举数据类型下的枚举元素,如再声明一个类型 Weekend:
type Weekend is ( Saturday, Sunday);或subtype Weekend is range Saturday .. Sunday;
赋给上例中的变量 Today 值为 Sunday时,不会产生歧义;但在有些情况下,Ada 无法分辨枚举元素时则会产生问题,这时就要使用类型限制。
Ada 中的基本数据类型就讲到这里,实际上本节是基于上一节内容的扩展,说穿了还是创建数据类型。Ada 在数据类型处理上提供的强大功能在接下的章节里我们将会接触的更多,在这方面 Ada 的确比其它大部份语言做的好多了,熟悉 C ,Pascal的朋友大概会感到相当有意思。