Apache Spark 核心编程
Spark核心是整个项目的基础。它提供了分布式任务调度,调度和基本的I / O功能。Spark使用一种被称为RDD(弹性分布式数据集)一个专门的基本的数据结构,是整个机器的分区数据的逻辑集合。 RDDS可以通过两种方式来创建;一个是在外部存储系统的数据集引用和第二是通过应用变换(如地图,过滤器,减速机,加入)现有RDDS。
该RDD抽象通过语言集成API暴露。这简化了编程的复杂性,因为应用程序的方式操纵RDDS类似于操纵数据的本地集合。
Spark Shell
Spark提供了一个交互的shell - 一个强大的工具,以交互方式分析数据。这是在任何Scala或Python语言的版本。Spark的主要抽象是称为弹性分布式数据集(RDD)项目的分布式集合。 RDDS可以从Hadoop的输入格式被创建(如HDFS文件)或通过转化其他RDDS。
打开Spark Shell
下面的命令用来打开Spark Shell。
$ spark-shell
创建简单的RDD
让我们从文本文件中创建一个简单的RDD。使用下面的命令来创建一个简单的RDD。
scala> val inputfile = sc.textFile(“input.txt”)
对上述命令的输出
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12
SparkRDD API引入了一些变革和一些动作来操纵RDD。
RDD转换
RDD转换返回指向新RDD,并允许您创建RDDS之间的依赖关系。每个RDD在依赖链(依赖的字符串)有计算其数据的功能,并有一个指针(依赖)其父RDD。
Spark是懒惰的,所以除非你调用一些改造或行动将触发创造就业机会和执行什么都不会被执行。看字计数的例子的片断。
因此,RDD转型不是一组数据,但在程序的一个步骤(可能是唯一的步骤)告诉Spark如何获取数据以及如何使用它。
下面给出是RDD变换的列表。
| S.No | 转换及意义 |
|---|---|
| 1 | 图(FUNC) 返回一个新的分布式数据集,通过传递源的每一个元素通过一个函数func形成。 |
| 2 | 过滤器(FUNC) 返回选择在其FUNC返回true源的这些元素组成了一个新的数据集。 |
| 3 | flatMap(FUNC) 类似图,但每个输入项可以被映射到0以上输出项(所以FUNC应返回SEQ而不是单一的项目)。 |
| 4 | mapPartitions(FUNC) 类似的图,但分别在RDD的每个分区(块)上运行,所以FUNC必须是类型的Iterator <T>⇒的Iterator <U>的类型T的RDD运行时, |
| 五 | mapPartitionsWithIndex(FUNC) 类似地图分区,而且还提供FUNC与代表分区索引的整数值,因此FUNC必须是类型(智力,迭代器<T>)的⇒迭代器<U>的类型T的RDD运行时, |
| 6 | 样品(withReplacement,片段,种子) 采样数据的一小部分 ,有或没有更换,利用给定的随机数发生器的种子。 |
| 7 | 工会(otherDataset) 返回包含在源数据集和参数的元素结合新的数据集。 |
| 8 | 路口(otherDataset) 返回包含在源数据集和参数元素的交集新RDD。 |
| 9 | 不同的([numTasks]) 返回包含源数据集的不同元件的一个新的数据集。 |
| 10 | groupByKey([numTasks]) 当对(K,V)对数据集调用,返回(K,可迭代<V>)对数据集。 注意 -如果是为了执行聚合(例如总和或平均值)在每个键分组,使用reduceByKey或aggregateByKey会产生更好的性能。 |
| 11 | reduceByKey(FUNC,[numTasks]) 当对(K,V)对数据集调用,返回(K,V)对,其中每个键的值是使用汇总给定的减少函数func,它必须是类型(V,V)⇒伏的数据集一样在groupByKey,减少任务的数量是通过可选的第二个参数进行配置。 |
| 12 | aggregateByKey(零值)(SEQOP,combOp,[numTasks]) 当对(K,V)对数据集调用,返回,其中每个键的值是使用给定的结合功能和中立的“零”值汇总(K,U)对数据集。允许聚合值类型,它是从输入值的类型不同,同时避免不必要的分配。像在groupByKey,减少任务的数量是通过可选的第二个参数进行配置。 |
| 13 | sortByKey([上升],[numTasks]) 当对(K,V)对数据集,其中K农具有序调用,返回在升序或降序键进行排序,如布尔上升参数指定(K,V)对的数据集。 |
| 14 | 加入(otherDataset,[numTasks]) 当(K,V)和(K,W)类型的数据集调用,返回(K,(V,W))对所有成对每个键元件的一个数据集。外连接通过leftOuterJoin,rightOuterJoin和fullOuterJoin的支持。 |
| 15 | 协同组(otherDataset,[numTasks]) 当(K,V)和(K,W)类型的数据集调用,返回的数据集(K,(可迭代<V>,可迭代<W>))元组。这种操作也被称为组带。 |
| 16 | 笛卡尔(otherDataset) 当类型T和U的数据集调用,返回(T,U)对数据集(所有元素对)。 |
| 17 | 管(指挥,[envvars中]) 管道通过一个shell命令,例如,一个Perl或bash脚本的RDD的每个分区。 RDD元素被写入到进程的标准输入和线路输出,标准输出返回字符串的RDD。 |
| 18 | 合并(numPartitions) 减少在RDD到numPartitions分区的数量。有用的过滤下来的大型数据集后,更高效地运行的操作。 |
| 19 | 重新分区(numPartitions) 洗牌的RDD数据随机创造更多或更少的分区,并在它们之间平衡。这总是慢腾腾在网络上的所有数据。 |
| 20 | repartitionAndSortWithinPartitions(分区) 根据给定的分区重新对RDD和,每个结果分区中,排序钥匙记录。这是比调用再分配然后在每个分区内的排序,因为它可以推动分拣向下进入洗牌机械效率更高。 |
操作
下表给出了操作,其返回值的列表。
| S.No | 动作及意义 |
|---|---|
| 1 | 减少(FUNC) 合计使用函数func(其中有两个参数,并返回一个)数据集的元素。该函数应当是可交换并且关联,以便它可以正确地在并行计算。 |
| 2 | 搜集() 返回数据集作为在驱动程序的数组的所有元素。这是一个过滤器或返回的数据的足够小的子集的其他操作之后,通常是有用的。 |
| 3 | 计数() 返回的数据集的元素数。 |
| 4 | 第一() 返回的数据集的第一元件(类似于采取(1))。 |
| 五 | 采取(N) 返回的数据集的前n个元素的数组。 |
| 6 | takeSample(withReplacement,NUM,[种子]) 返回与数据集的NUM元件,具有或不具有取代,任选预先指定的随机数发生器种子的随机样本的阵列。 |
| 7 | takeOrdered(N,[排序]) 返回使用或者按其自然顺序或自定义比较的RDD的第n个元素。 |
| 8 | saveAsTextFile(路径) 写入数据集的元素为文本文件(或一组文本文件)在本地文件系统,HDFS或任何其他的Hadoop支持的文件系统给定目录。Spark呼吁每个元素的toString将其转换为文件中的一行文字。 |
| 9 | saveAsSequenceFile(路径)(Java和Scala) 将DataSet作为Hadoop的SequenceFile的元素在本地文件系统,HDFS或任何其他的Hadoop支持的文件系统给定的路径。这是适用于实现Hadoop的可写界面键 - 值对RDDS。在Scala中,它也可在那些隐式转换为可写(Spark包括基本类型如int,双,字符串等转换)类型。 |
| 10 | saveAsObjectFile(路径)(Java和Scala) 写入的数据集的元素使用Java序列化一个简单的格式,然后可以使用SparkContext.objectFile被加载()。 |
| 11 | countByKey() 仅适用于类型的RDDS(K,V)。返回(K,智力)对与每个键的计数的一个HashMap。 |
| 12 | 的foreach(FUNC) 运行数据集的每个元素的函数func。这通常是,对于副作用例如更新累加器或与外部存储系统进行交互进行。 注 -修改的foreach以外的蓄电池相比其他变量()可能会导致不确定的行为。请参阅了解闭包的更多细节。 |
与RDD编程
让我们来看看几个RDD转变和行动的RDD编程实现用一个例子的帮助。
例
考虑一个字计数的例子 - 它计算出现在文档中的每个字。请看下面的文本输入,并保存为一个主目录的input.txt的文件。
input.txt的 -输入文件。
people are not as beautiful as they look, as they walk or as they talk. they are only as beautiful as they love, as they care as they share.
按照下面给出执行给定的示例程序。
打开Spark Shell
下面的命令用来打开Spark Shell。一般情况下,Spark使用Scala构建。因此,Spark计划的Scala环境中运行。
$ spark-shell
如果Spark Shell成功打开,然后你会发现下面的输出。查看输出“作为SCSpark环境”的最后一行意味着Spark容器会自动创建Spark上下文对象名为SC。启动程序的第一步骤之前,应该创建SparkContext对象。
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>
创建RDD
首先,我们必须读取使用SparkScalaAPI输入文件,并创建一个RDD。
下面的命令被用于从给定位置读出的文件。在这里,新RDD与inputfile的名称创建。这是考虑在文本文件的参数字符串(“”)的方法是用于输入文件名的绝对路径。然而,如果仅给出文件名,则意味着输入文件是在当前位置。
scala> val inputfile = sc.textFile("input.txt")
执行字数转型
我们的目标是在一个文件来算的话。分裂各行成词创建平面地图(flatMap(线⇒line.split(“”))。
接下来,读每个词作为一个价值的关键'1'(<键,值> = <字,1>),使用地图功能( 图(字⇒(字,1))。
最后,加入类似键的值(; _)reduceByKey(_&加 )减少这些密钥。
下面的命令用于执行字数统计逻辑。执行此之后,你不会找到任何输出,因为这不是一个动作,这是一个转变;指向一个新的RDD或者告诉Spark,如何处理给定的数据做)
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);
当前RDD
同时与RDD工作,如果你想了解当前RDD,然后使用下面的命令。它会告诉你关于当前RDD及其调试依赖的描述。
scala> counts.toDebugString
缓存转换
您可以标记一个RDD使用坚持()或缓存(),它的方法来保留。第一次是在动作计算机,它将被保存在存储器中的节点上。使用以下命令来存储中间转换在内存中。
scala> counts.cache()
运用行动
应用的操作,比如存储中的所有转换,结果到一个文本文件中。对于saveAsTextFile字符串参数(“”)的方法是输出文件夹的绝对路径。请尝试以下命令将输出保存在一个文本文件中。在下面的例子中,“输出”的文件夹是在当前位置。
scala> counts.saveAsTextFile("output")
检查输出
打开另一个终端去主目录(其中Spark在其他终端执行)。用于检查输出目录下面的命令。
[hadoop@localhost ~]$ cd output/ [hadoop@localhost output]$ ls -1 part-00000 part-00001 _SUCCESS
下面的命令用于看到部分-00000的文件输出。
[hadoop@localhost output]$ cat part-00000
产量
(people,1) (are,2) (not,1) (as,8) (beautiful,2) (they, 7) (look,1)
下面的命令用于看到部分-00001的文件输出。
[hadoop@localhost output]$ cat part-00001
产量
(walk, 1) (or, 1) (talk, 1) (only, 1) (love, 1) (care, 1) (share, 1)
联合国坚持存储
联合国持续存在之前,如果你想看到一个用于此应用程序的存储空间,然后使用下面的URL在浏览器中。
http://localhost:4040
你会看到下面的屏幕,该屏幕显示用于应用程序,这些都对Sparkshell中运行的存储空间。
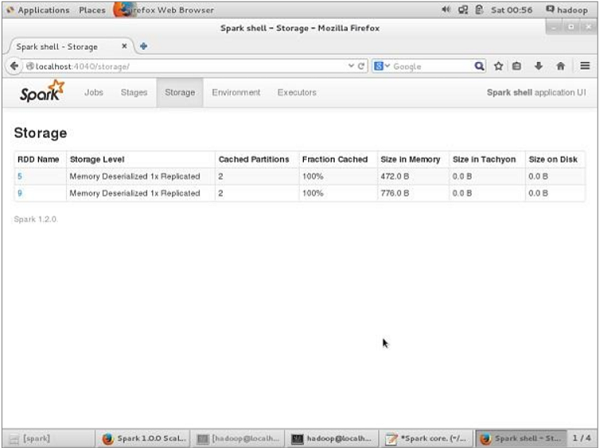
如果你想联合国坚持特别RDD的存储空间,然后使用下面的命令。
Scala> counts.unpersist()
您将看到输出如下 -
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list 15/06/27 00:57:33 INFO BlockManager: Removing RDD 9 15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1 15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810) 15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0 15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106) res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14
在浏览器中验证的存储空间,使用以下URL。
http://localhost:4040/
您将看到以下画面。它示出了用于应用程序,这是在Spark Shell运行存储空间。