
Hadoop 读取数据
MapReduce - 读取数据
通过InputFormat决定读取的数据的类型,然后拆分成一个个InputSplit,每个InputSplit对应一个Map处理,RecordReader读取InputSplit的内容给Map
InputFormat
决定读取数据的格式,可以是文件或数据库等
功能
- 验证作业输入的正确性,如格式等
- 将输入文件切割成逻辑分片(InputSplit),一个InputSplit将会被分配给一个独立的Map任务
- 提供RecordReader实现,读取InputSplit中的"K-V对"供Mapper使用
方法
List getSplits(): 获取由输入文件计算出输入分片(InputSplit),解决数据或文件分割成片问题
RecordReader createRecordReader(): 创建RecordReader,从InputSplit中读取数据,解决读取分片中数据问题
类结构
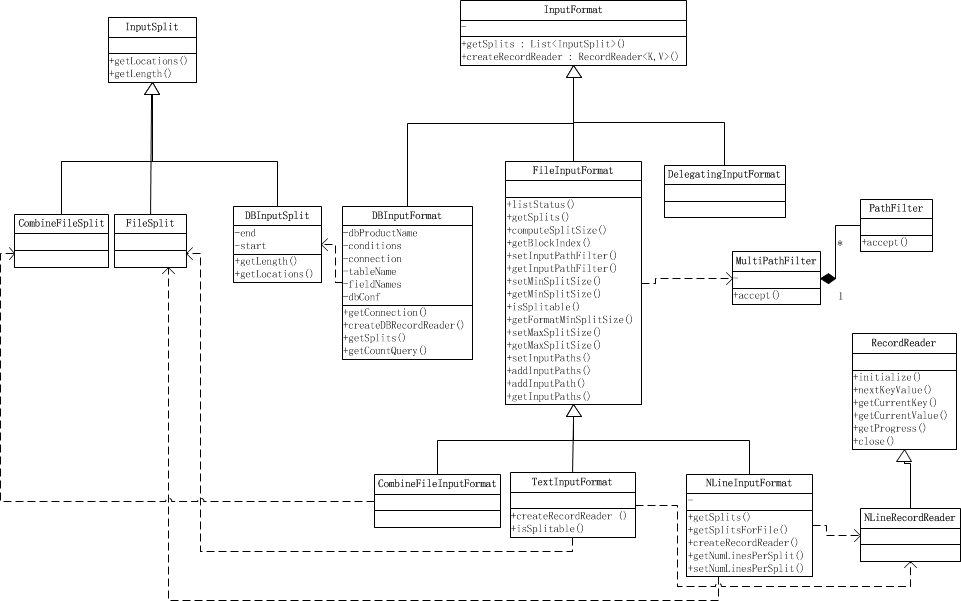
TextInputFormat: 输入文件中的每一行就是一个记录,Key是这一行的byte offset,而value是这一行的内容
KeyValueTextInputFormat: 输入文件中每一行就是一个记录,第一个分隔符字符切分每行。在分隔符字符之前的内容为Key,在之后的为Value。分隔符变量通过key.value.separator.in.input.line变量设置,默认为(\t)字符。
NLineInputFormat: 与TextInputFormat一样,但每个数据块必须保证有且只有N行,mapred.line.input.format.linespermap属性,默认为1
SequenceFileInputFormat: 一个用来读取字符流数据的InputFormat,<key,value>为用户自定义的。字符流数据是Hadoop自定义的压缩的二进制数据格式。它用来优化从一个MapReduce任务的输出到另一个MapReduce任务的输入之间的数据传输过程。</key,value>
InputSplit
代表一个个逻辑分片,并没有真正存储数据,只是提供了一个如何将数据分片的方法
Split内有Location信息,利于数据局部化
一个InputSplit给一个单独的Map处理
public abstract class InputSplit {
/**
* 获取Split的大小,支持根据size对InputSplit排序.
*/
public abstract long getLength() throws IOException, InterruptedException;
/**
* 获取存储该分片的数据所在的节点位置.
*/
public abstract String[] getLocations() throws IOException, InterruptedException;
}RecordReader
将InputSplit拆分成一个个<key,value>对给Map处理,也是实际的文件读取分隔对象</key,value>
问题
大量小文件如何处理
CombineFileInputFormat可以将若干个Split打包成一个,目的是避免过多的Map任务(因为Split的数目决定了Map的数目,大量的Mapper Task创建销毁开销将是巨大的)
怎么计算split的
通常一个split就是一个block(FileInputFormat仅仅拆分比block大的文件),这样做的好处是使得Map可以在存储有当前数据的节点上运行本地的任务,而不需要通过网络进行跨节点的任务调度
通过mapred.min.split.size, mapred.max.split.size, block.size来控制拆分的大小
如果mapred.min.split.size大于block size,则会将两个block合成到一个split,这样有部分block数据需要通过网络读取
如果mapred.max.split.size小于block size,则会将一个block拆成多个split,增加了Map任务数(Map对split进行计算并且上报结果,关闭当前计算打开新的split均需要耗费资源)
先获取文件在HDFS上的路径和Block信息,然后根据splitSize对文件进行切分( splitSize = computeSplitSize(blockSize, minSize, maxSize) ),默认splitSize 就等于blockSize的默认值(64m)
public List<InputSplit> getSplits(JobContext job) throws IOException {
// 首先计算分片的最大和最小值。这两个值将会用来计算分片的大小
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
FileSystem fs = path.getFileSystem(job.getConfiguration());
// 获取该文件所有的block信息列表[hostname, offset, length]
BlockLocation[] blkLocations = fs.getFileBlockLocations(file, 0, length);
// 判断文件是否可分割,通常是可分割的,但如果文件是压缩的,将不可分割
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
// 计算分片大小
// 即 Math.max(minSize, Math.min(maxSize, blockSize));
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
// 循环分片。
// 当剩余数据与分片大小比值大于Split_Slop时,继续分片, 小于等于时,停止分片
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts()));
bytesRemaining -= splitSize;
}
// 处理余下的数据
if (bytesRemaining != 0) {
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining, blkLocations[blkLocations.length-1].getHosts()));
}
} else {
// 不可split,整块返回
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts()));
}
} else {
// 对于长度为0的文件,创建空Hosts列表,返回
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// 设置输入文件数量
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
LOG.debug("Total # of splits: " + splits.size());
return splits;
}分片间的数据如何处理
split是根据文件大小分割的,而一般处理是根据分隔符进行分割的,这样势必存在一条记录横跨两个split

解决办法是只要不是第一个split,都会远程读取一条记录。不是第一个split的都忽略到第一条记录
public class LineRecordReader extends RecordReader<LongWritable, Text> {
private CompressionCodecFactory compressionCodecs = null;
private long start;
private long pos;
private long end;
private LineReader in;
private int maxLineLength;
private LongWritable key = null;
private Text value = null;
// initialize函数即对LineRecordReader的一个初始化
// 主要是计算分片的始末位置,打开输入流以供读取K-V对,处理分片经过压缩的情况等
public void initialize(InputSplit genericSplit, TaskAttemptContext context) throws IOException {
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
this.maxLineLength = job.getInt("mapred.linerecordreader.maxlength", Integer.MAX_VALUE);
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
compressionCodecs = new CompressionCodecFactory(job);
final CompressionCodec codec = compressionCodecs.getCodec(file);
// 打开文件,并定位到分片读取的起始位置
FileSystem fs = file.getFileSystem(job);
FSDataInputStream fileIn = fs.open(split.getPath());
boolean skipFirstLine = false;
if (codec != null) {
// 文件是压缩文件的话,直接打开文件
in = new LineReader(codec.createInputStream(fileIn), job);
end = Long.MAX_VALUE;
} else {
// 只要不是第一个split,则忽略本split的第一行数据
if (start != 0) {
skipFirstLine = true;
--start;
// 定位到偏移位置,下次读取就会从偏移位置开始
fileIn.seek(start);
}
in = new LineReader(fileIn, job);
}
if (skipFirstLine) {
// 忽略第一行数据,重新定位start
start += in.readLine(new Text(), 0, (int) Math.min((long) Integer.MAX_VALUE, end - start));
}
this.pos = start;
}
public boolean nextKeyValue() throws IOException {
if (key == null) {
key = new LongWritable();
}
key.set(pos);// key即为偏移量
if (value == null) {
value = new Text();
}
int newSize = 0;
while (pos < end) {
newSize = in.readLine(value, maxLineLength, Math.max((int) Math.min(Integer.MAX_VALUE, end - pos), maxLineLength));
// 读取的数据长度为0,则说明已读完
if (newSize == 0) {
break;
}
pos += newSize;
// 读取的数据长度小于最大行长度,也说明已读取完毕
if (newSize < maxLineLength) {
break;
}
// 执行到此处,说明该行数据没读完,继续读入
}
if (newSize == 0) {
key = null;
value = null;
return false;
} else {
return true;
}
}
}