
Kubernetes Pod拓扑分布约束
Pod 拓扑分布约束
FEATURE STATE: Kubernetes v1.19 [stable]
你可以使用 拓扑分布约束(Topology Spread Constraints) 来控制 Pods 在集群内故障域 之间的分布,例如区域(Region)、可用区(Zone)、节点和其他用户自定义拓扑域。 这样做有助于实现高可用并提升资源利用率。
先决条件
节点标签
拓扑分布约束依赖于节点标签来标识每个节点所在的拓扑域。 例如,某节点可能具有标签:node=node1,zone=us-east-1a,region=us-east-1
假设你拥有具有以下标签的一个 4 节点集群:
NAME STATUS ROLES AGE VERSION LABELS
node1 Ready <none> 4m26s v1.16.0 node=node1,zone=zoneA
node2 Ready <none> 3m58s v1.16.0 node=node2,zone=zoneA
node3 Ready <none> 3m17s v1.16.0 node=node3,zone=zoneB
node4 Ready <none> 2m43s v1.16.0 node=node4,zone=zoneB那么,从逻辑上看集群如下:
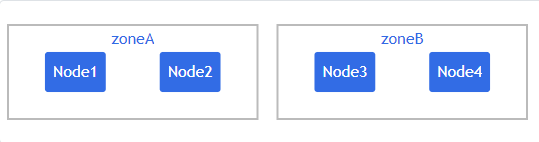
你可以复用在大多数集群上自动创建和填充的常用标签, 而不是手动添加标签。
Pod 的分布约束
API
pod.spec.topologySpreadConstraints 字段定义如下所示:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
topologySpreadConstraints:
- maxSkew: <integer>
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>你可以定义一个或多个 topologySpreadConstraint 来指示 kube-scheduler 如何根据与现有的 Pod 的关联关系将每个传入的 Pod 部署到集群中。字段包括:
- maxSkew 描述 Pod 分布不均的程度。这是给定拓扑类型中任意两个拓扑域中 匹配的 pod 之间的最大允许差值。它必须大于零。取决于
whenUnsatisfiable的 取值,其语义会有不同。 - 当
whenUnsatisfiable等于 "DoNotSchedule" 时,maxSkew是目标拓扑域 中匹配的 Pod 数与全局最小值之间可存在的差异。 - 当
whenUnsatisfiable等于 "ScheduleAnyway" 时,调度器会更为偏向能够降低 偏差值的拓扑域。 - topologyKey 是节点标签的键。如果两个节点使用此键标记并且具有相同的标签值, 则调度器会将这两个节点视为处于同一拓扑域中。调度器试图在每个拓扑域中放置数量 均衡的 Pod。
- whenUnsatisfiable 指示如果 Pod 不满足分布约束时如何处理:
-
DoNotSchedule(默认)告诉调度器不要调度。 -
ScheduleAnyway告诉调度器仍然继续调度,只是根据如何能将偏差最小化来对 节点进行排序。 - labelSelector 用于查找匹配的 pod。匹配此标签的 Pod 将被统计,以确定相应 拓扑域中 Pod 的数量。
当 Pod 定义了不止一个 topologySpreadConstraint,这些约束之间是逻辑与的关系。 kube-scheduler 会为新的 Pod 寻找一个能够满足所有约束的节点。
你可以执行 kubectl explain Pod.spec.topologySpreadConstraints 命令以 了解关于 topologySpreadConstraints 的更多信息。
例子:单个 TopologySpreadConstraint
假设你拥有一个 4 节点集群,其中标记为 foo:bar 的 3 个 Pod 分别位于 node1、node2 和 node3 中:
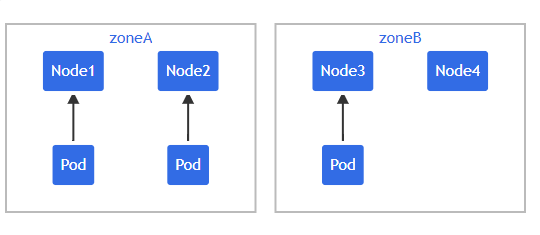
如果希望新来的 Pod 均匀分布在现有的可用区域,则可以按如下设置其规约:
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: k8s.gcr.io/pause:3.1topologyKey: zone 意味着均匀分布将只应用于存在标签键值对为 "zone:<any value>" 的节点。 whenUnsatisfiable: DoNotSchedule 告诉调度器如果新的 Pod 不满足约束, 则让它保持悬决状态。
如果调度器将新的 Pod 放入 "zoneA",Pods 分布将变为 [3, 1],因此实际的偏差 为 2(3 - 1)。这违反了 maxSkew: 1 的约定。此示例中,新 Pod 只能放置在 "zoneB" 上:
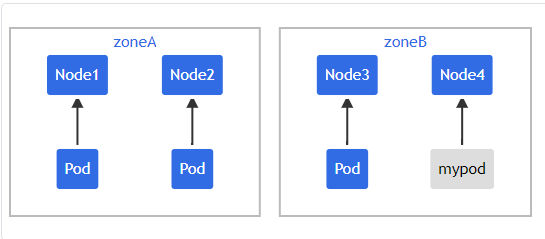
或者

你可以调整 Pod 规约以满足各种要求:
- 将
maxSkew更改为更大的值,比如 "2",这样新的 Pod 也可以放在 "zoneA" 上。 - 将
topologyKey更改为 "node",以便将 Pod 均匀分布在节点上而不是区域中。 在上面的例子中,如果 maxSkew保持为 "1",那么传入的 Pod 只能放在 "node4" 上。 - 将
whenUnsatisfiable: DoNotSchedule 更改为 whenUnsatisfiable: ScheduleAnyway, 以确保新的 Pod 始终可以被调度(假设满足其他的调度 API)。 但是,最好将其放置在匹配 Pod 数量较少的拓扑域中。 (请注意,这一优先判定会与其他内部调度优先级(如资源使用率等)排序准则一起进行标准化。)
例子:多个 TopologySpreadConstraints
下面的例子建立在前面例子的基础上。假设你拥有一个 4 节点集群,其中 3 个标记为 foo:bar 的 Pod 分别位于 node1、node2 和 node3 上:
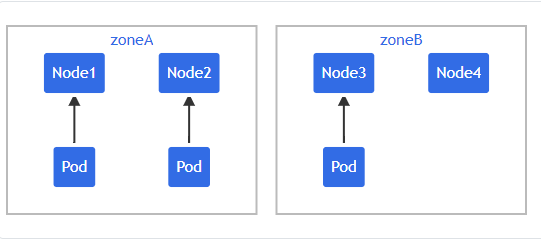
可以使用 2 个 TopologySpreadConstraint 来控制 Pod 在 区域和节点两个维度上的分布:
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
- maxSkew: 1
topologyKey: node
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: k8s.gcr.io/pause:3.1在这种情况下,为了匹配第一个约束,新的 Pod 只能放置在 "zoneB" 中;而在第二个约束中, 新的 Pod 只能放置在 "node4" 上。最后两个约束的结果加在一起,唯一可行的选择是放置 在 "node4" 上。
多个约束之间可能存在冲突。假设有一个跨越 2 个区域的 3 节点集群:
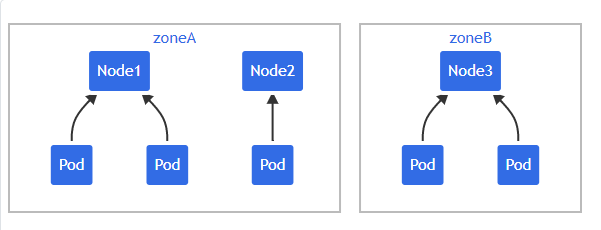
如果对集群应用 "two-constraints.yaml",会发现 "mypod" 处于 Pending 状态。 这是因为:为了满足第一个约束,"mypod" 只能放在 "zoneB" 中,而第二个约束要求 "mypod" 只能放在 "node2" 上。Pod 调度无法满足两种约束。
为了克服这种情况,你可以增加 maxSkew 或修改其中一个约束,让其使用 whenUnsatisfiable: ScheduleAnyway。
节点亲和性与节点选择器的相互作用
如果 Pod 定义了 spec.nodeSelector 或 spec.affinity.nodeAffinity, 调度器将在偏差计算中跳过不匹配的节点。
示例:TopologySpreadConstraints 与 NodeAffinity
假设你有一个跨越 zoneA 到 zoneC 的 5 节点集群:
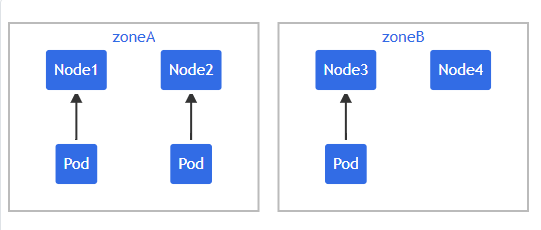

而且你知道 "zoneC" 必须被排除在外。在这种情况下,可以按如下方式编写 YAML, 以便将 "mypod" 放置在 "zoneB" 上,而不是 "zoneC" 上。同样,spec.nodeSelector 也要一样处理。
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: NotIn
values:
- zoneC
containers:
- name: pause
image: k8s.gcr.io/pause:3.1调度器不会预先知道集群拥有的所有区域和其他拓扑域。拓扑域由集群中存在的节点确定。 在自动伸缩的集群中,如果一个节点池(或节点组)的节点数量为零, 而用户正期望其扩容时,可能会导致调度出现问题。 因为在这种情况下,调度器不会考虑这些拓扑域信息,因为它们是空的,没有节点。
其他值得注意的语义
这里有一些值得注意的隐式约定:
- 只有与新的 Pod 具有相同命名空间的 Pod 才能作为匹配候选者。
- 调度器会忽略没有 topologySpreadConstraints[*].topologyKey 的节点。这意味着:
- 位于这些节点上的 Pod 不影响 maxSkew 的计算。 在上面的例子中,假设 "node1" 没有标签 "zone",那么 2 个 Pod 将被忽略, 因此传入的 Pod 将被调度到 "zoneA" 中。
- 新的 Pod 没有机会被调度到这类节点上。 在上面的例子中,假设一个带有标签 {zone-typo: zoneC} 的 "node5" 加入到集群, 它将由于没有标签键 "zone" 而被忽略。
- 注意,如果新 Pod 的 topologySpreadConstraints[*].labelSelector 与自身的 标签不匹配,将会发生什么。 在上面的例子中,如果移除新 Pod 上的标签,Pod 仍然可以调度到 "zoneB",因为约束仍然满足。 然而,在调度之后,集群的不平衡程度保持不变。zoneA 仍然有 2 个带有 {foo:bar} 标签的 Pod, zoneB 有 1 个带有 {foo:bar} 标签的 Pod。 因此,如果这不是你所期望的,建议工作负载的 topologySpreadConstraints[*].labelSelector 与其自身的标签匹配。
集群级别的默认约束
为集群设置默认的拓扑分布约束也是可能的。默认拓扑分布约束在且仅在以下条件满足 时才会应用到 Pod 上:
- Pod 没有在其
.spec.topologySpreadConstraints 设置任何约束; - Pod 隶属于某个服务、副本控制器、ReplicaSet 或 StatefulSet。
你可以在 调度方案(Scheduling Profile) 中将默认约束作为 PodTopologySpread 插件参数的一部分来设置。 约束的设置采用如前所述的 API,只是 labelSelector 必须为空。 选择算符是根据 Pod 所属的服务、副本控制器、ReplicaSet 或 StatefulSet 来设置的。
配置的示例可能看起来像下面这个样子:
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
defaultingType: List默认调度约束所生成的评分可能与 SelectorSpread 插件 所生成的评分有冲突。 建议你在为
PodTopologySpread设置默认约束是禁用调度方案中的该插件。
内部默认约束
FEATURE STATE: Kubernetes v1.20 [beta]
当你使用了默认启用的 DefaultPodTopologySpread 特性门控时,原来的 SelectorSpread 插件会被禁用。 kube-scheduler 会使用下面的默认拓扑约束作为 PodTopologySpread 插件的 配置:
defaultConstraints:
- maxSkew: 3
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: ScheduleAnyway
- maxSkew: 5
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: ScheduleAnyway此外,原来用于提供等同行为的 SelectorSpread 插件也会被禁用。
对于分布约束中所指定的拓扑键而言,PodTopologySpread插件不会为不包含这些主键的节点评分。 这可能导致在使用默认拓扑约束时,其行为与原来的 SelectorSpread插件的默认行为不同,
如果你的节点不会 同时 设置 kubernetes.io/hostname 和 topology.kubernetes.io/zone 标签,你应该定义自己的约束而不是使用 Kubernetes 的默认约束。
如果你不想为集群使用默认的 Pod 分布约束,你可以通过设置 defaultingType 参数为 List 并将 PodTopologySpread 插件配置中的 defaultConstraints 参数置空来禁用默认 Pod 分布约束。
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints: []
defaultingType: List
与 PodAffinity/PodAntiAffinity 相比较
在 Kubernetes 中,与“亲和性”相关的指令控制 Pod 的调度方式(更密集或更分散)。
- 对于
PodAffinity,你可以尝试将任意数量的 Pod 集中到符合条件的拓扑域中。 - 对于
PodAntiAffinity,只能将一个 Pod 调度到某个拓扑域中。
要实现更细粒度的控制,你可以设置拓扑分布约束来将 Pod 分布到不同的拓扑域下, 从而实现高可用性或节省成本。这也有助于工作负载的滚动更新和平稳地扩展副本规模。
已知局限性
- 当 Pod 被移除时,无法保证约束仍被满足。例如,缩减某 Deployment 的规模时, Pod 的分布可能不再均衡。 你可以使用 Descheduler 来重新实现 Pod 分布的均衡。
- 具有污点的节点上匹配的 Pods 也会被统计。 参考 Issue 80921。