
基于PhalApi的DB集群拓展Cluster (由@喵了个咪提供)
基于PhalApi的DB集群拓展 V0.1bate

前言
先在这里感谢phalapi框架创始人@dogstar,为我们提供了这样一个优秀的开源框架.
编写本次拓展出于的目的是解决大量数据写入分析的问题,也希望本拓展能对大家有些帮助,能够解决大家遇到的同样的问题.
注:V0.1bate版本,很多功能尚不完善,只提供技术交流使用,请不要用户生产环境
附上:
开源中国Git地址:http://git.oschina.net/dogstar/PhalApi/tree/release
1.起因
说到为什么写这个拓展,起因是这样的,在和产品交流的时候他们希望可以存一些东西作为数据分析用,我考虑过hadoop但是如果说使用hadoop需要投入的成本太高了,在想有没有什么好办法的时候,想到了分表分库解决数据量大的问题,那么可以有一个封装好的服务就和操作数据库一样操作可以达到良好的分表分库的效果吗,出于这个考虑就开始这个拓展的编写.
2.业务场景##
大量select
当一个数据库需要对付大量的select请求的时候,我们往往会想到使用读写分离来解决此类问题,一个写库多个读库,一台或多台服务器用一个读库,所有的写入操作使用主库操作,应为是大量的select操作,读的压力被分配到了很多个读库实例,可以很好的解决问题大量select的问题,再者就是进行添加缓存机制的优化,这样也是能很好的解决问题
大量的insert
对于大量insert上面所谓的读写分离完全不够看了,所有的压力全部会集中在负责写入的主库,但并不是应为并发请求的问题,问题是在于数据量大导致不管是干嘛都会慢,当数据量到了上亿的级别简直不敢想像,如果是通过分表分库(如果是4库4表也就是16张表),数据分均衡的分配到(库数量-乘-表数量)这么多张表里面从而达到解决大量数据的问题(在分表分库前面有一个主表),当然他也有缺陷就是当进行条件查询的时候最坏的条件会遍历(库数量-乘-表数量)这么多张表才能获得想要的结果,所以不是很建议用到查询列表比较平凡的应用中,当然结合缓存和读写分离可以缓解压力
3.使用拓展
3.1 下载/注册拓展
大家可以到Git项目PhalApi Library下载拓展文件,把其中的DB_Cluster文件夹复制到/PhalApi/Library目录下,如下图:
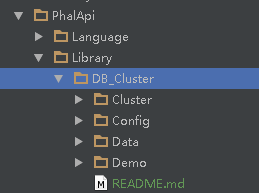
把其中的Config中的cluster.php文件放到默认的Config配置文件中
然后在init.php中注册以下两句话
//初始化配置文件
DI()->Cluster_DB = new Cluster_Lite(DI()->config->get('cluster'));
然后把框架自带的Demo文件替换成拓展自带的Demo文件如下就完成了第一步
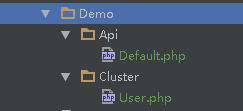
3.2 数据库集群初始化
这里使用Mysql作为集群的数据库
大家可以看到拓展文件里面有一个Data/user_cluster.sql 文件,里面有一个 user_base的建表语句和另外user0,user1,user2,user3这四个表的建表语句
在文件里面有一些注意事项这里这里再次强调一下
--本次集群采取4库每一库4表 4*4共16表的mysql集群(基础库不算在里面) --基础库(id自增长,用表索引进行列表查询条件) --库名project --当自己建立集群mysql的时候要注意以下几点 --1.一定要注意ID要加上自动增长,这里进行的分表分库都是基于自增ID进行的,如果是自定义字符串ID需要进行算法修改,也可以使用其他缓存生成自增ID --2.除了ID之外的字段(用于按条件查询列表ID)一定要加上索引或者是主键,不然数据量大的时候获取列表ID会很慢 --3.除了ID之外的字段一定要是更具业务需求进行查询比较频繁的,而且要保持尽量的少1-2个,大于2个建议在分出一张表做对应 --库名分表为user_cluster0,user_cluster1,user_cluster2,user_cluster3(可自定) --下面四张表为每一个库中都拥有的4张表(注意ID不能使用自动增长) --表名可以自定但是每个库中的表名一定要统一 --user0,user1,user2,user3
我这里使用结构如下(大家可以自由的配置可以2库+2表,2库+4表等都行,只需在配置文件中配置就可)
数据库project
-user_base表
数据库user_cluster0,user_cluster1,user_cluster2,user_cluster3
都有以下表
-user0,user1,user2,user3
3.3 配置文件详解
我们需在在默认dbs.php 数据库配置中配置链接好project库
然后大家看向cluster.php集群配置文件按照注释配置好自己的数据库,如果没有多个mysql实例,可以一个实例建立4个库模拟4个mysql分布式集群.
这里指的着重讲一下的是以下配置问题
/**
* 配置表
*/
'cluster' => array(
//集群分布配置
'list' => array(
'demo' => array(
//使用demo集群配置最大ID和最小ID,最大ID为0等于不上限
'id_min' => 0,
'id_max' => 0,
),
),
//where查询条件放到衍生表中的字段
'where' => array(
'city'
),
//ID名称
'id_name' => 'uId',
),
在list中可以配置多个集群数组KEY的名称对应配置文件上面demo集群并且可以设定ID范围,做这个设计主要是为了当我有一个2库*2表的集群,已经承载了1个亿的数据了,已经无法承担数据量了这个时候就要更换集群,在这里只需要吧demo的id_max配置成1亿,在配置一个demo1然后把id_min设定到1亿,当ID大于1亿了之后就会自己找到第二集群插入数据了(不用担心多集群了之后查询以及其他操作这里已经做好了兼容)
还有where属性,这里的where用于配置在user_base表中除了ID之外的索引字段能够增加查询的性能,但是尽量少应为这个会减少base表的性能,可以适当的取舍
3.4 开始使用
大家看向Demo的API文件中有四个接口select,delete,update,insert里面的参数都是随机生成的
在看向Cluster/User.php里面继承了Cluster_DB需要使用数据库集群就需要集成这个类并且实现以下两个方法
/**
* 获取集群实例类
*/
public function getCluster(){
return DI()->Cluster_DB;
}
/**
* 获取主数据库表实例
*/
public function getMainDB(){
return DI()->notorm->user_base;
}
getCluster方法返回在init.php中注册DI()->Cluster_DB即可,因为一个集群对应一张表可以根据需求使用不通的集群实例
getMainDB方法是为了获取base表的实例只需要把表实例返回即可
当做好这几件事情大家就可以尝试请求接口看看结果了
4. 实现思想讲解
实现架构思维
我在开始写这个拓展之前在想要让使用者如何去使用这个框架,怎么让使用者最方便,最后的到的答案是如果可以和正常使用Model层一样去使用的话是最好的,所以大家可以看到在Demo/Cluster/User.php中增删改查和正常使用基本没有区别.
分表分库算法
当我们是2库2表的情况下,我们用2*2=4然后用我们获取的ID比如55,用55%2*2 就会得到一个小于4的数字,55得到的是3,用3/表数2=1.5取整是1表,然后用3%表数2=1,也就是存入1库1表(注意是从0开始算的)
5. 基准测试
5.1 base表基准测试
因为我们的拓展是需要基于一个base表实现ID增长和where语句查询在分到集群库,所以base库需要应付的量比较大所以这里对base表进行了一次针对于不同数据量进行的单ID查询和where查询基准测试
300w数据:
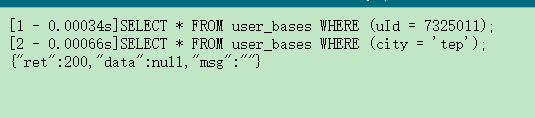
5700w数据:

1.3亿数据:

明显可以看出来随着数据量的增加查询速度有明显的降低,但是到了亿级的时候还能维持到where条件查询不上0.1秒的情况还是比较理想的,最关键的是在亿级的时候插入还是相当快的所以非常适合,大量数据的写入,如果是对查询有比较大的要求的童鞋可以考虑吧5000W作为一个分界点对基础base进行划分(后期将会把此功能集成到拓展内部)
5.2 从小.中.大数据库就集群与单表实际情况并发对比
应为工作量比较大还在进行测试中!
6. 总结
在此希望本扩展能给大家带来解决实际问题的思路,第一版是bate版本请不要使用在生产环境中,如果出现问题或者是有BUG可以直接联系我QQ591235675也可加入PhalApi交流群一同交流探讨
注:笔者能力有限有说的不对的地方希望大家能够指出,也希望多多交流!
官网QQ交流群:421032344 欢迎大家的加入!