
PhalGo-ADM思想
PhalGo-ADM思想
关于ADM思想主要是指在API开发中使用API,Domain和Model三层结构,PhalGo从PhalApi中学习并且推崇这种设计模式,这种模式的好处在于分工明确,业务复用,数据复用可以减少复杂业务重复的代码量,很多框架关心性能,而不关心人文;很多项目关心技术,而不关注业务。ADM设计就是从业务的角度出发建立的开发规范.
ADM分工协作
Api
Api层可以理解为是请求开始结束以及组合业务的地方,主要负责以下几件事情:
- 获取请求参数并且验证请求参数的有效性
- 对Domain领域层的实现进行拼接来组成整个接口的业务
- 对于返回结果进行处理
我们可以看一个获取用户详情接口的例子:
func (this *User_Api)GetUserInfo() echo.HandlerFunc {
return func(c echo.Context) error {
Request := phalgo.Requser{Context:c}
Response := phalgo.Response{Context:c}
defer Request.ErrorLogRecover()
//获取请求参数
id := Request.GetParam("id").GetInt()
//拼接领域层业务
user, err := this.Domain.User.GetUserInfo(id)
if err != nil {
return Response.RetError(err, 400)
}
//返回结果
return Response.RetSuccess(user)
}
}(1)Api接口层应该做:
- 应该:对用户登录态进行必要的检测
- 应该:控制业务场景的主流程,创建领域业务实例,并进行调用
- 应该:进行必要的日志纪录
- 应该:返回接口结果
(2)Api接口层不应该做:
- 不应该:进行业务规则的处理或者计算
- 不应该:关心数据是否使用缓存,或进行缓存相关的直接操作
- 不应该:直接操作数据库
- 不应该:将多个接口合并在一起
Domain
Domain可以称之为领域层,是ADM(Api-Domain-Model)分层中的桥梁,主要负责处理业务规则。Domain层存在的目录是为了把复杂业务拆分成一个一个小模块然后组织起来实现复杂的业务,从而达到代码复用,拆分复杂业务的作用.
举个栗子
场景:我们在传统MVC开发的时候,使用控制器来处理业务,我们可能会写很多的重复代码来验证用户提交的信息是否ok,比如完善信息的时候验证邮箱,在修改用户信息的时候也要验证修改的邮箱,在管理的时候去编辑一个用户的时候也可能在去验证邮箱,这个时候我们的验证逻辑代码已经重复写在了3个地方,如果有一个需求加入了电话号码,那么你需要在3个地方加上对电话号码的验证逻辑
场景一并不难以遇到,而且在复杂的业务情况下重复使用的业务逻辑会更多,如果我们使用了Domain来处理用户修改前的验证那么我们只需要修改这个验证逻辑加上对电话号码的验证,那么所有需要验证用户信息的地方就会全部生效,而不用去做重复的工作并且避免遗漏的风险
下面是我们获取User详情的Domain层的实现,它不仅仅只是可以用在获取用户详情也可以用来验证用户ID是否有效,增加代码复用性减少修改代价
func (this *Domain_User)GetUserInfo(id int)(Model.User,error) {
user, err := this.Model.User.GetInfoById(id)
if err != nil {
return user, errors.New("UserInfo There is no")
}
return user,nil
}一个函数如果超过了一屏那将会影响到阅读者的理解,使用领域层拆分笨重的业务可以很好的解决这个问题
Model
Model层想必不用说了,就是和数据库通讯获取数据,Model层是单纯的不带任何业务只是简单的获取数据库数据,我们看一段Model层代码:
type User struct {
Id int `gorm:"column:aId"`
Name string `gorm:"column:name"`
Passwd string `gorm:"column:passwd"`
Email string `gorm:"column:email"`
}
func (User) TableName() string {
return "user"
}
func (this *User)GetInfoById(id int) (User, error) {
User := User{}
err := phalgo.GetORM().Where("id = ?", id).First(&User).Error
return User, err
}注意:Model层只应该获取数据然后结束关于没有获取到数据,获取出错等情况抛出到Domain层进行处理,这样可以增加灵活性,比如通过用户名是否重复和通过用户名称获取ID,一个返回存在才算异常,一个返回不存在才算异常,具体更具业务不同体现也不同,所以Model层处理并不合适
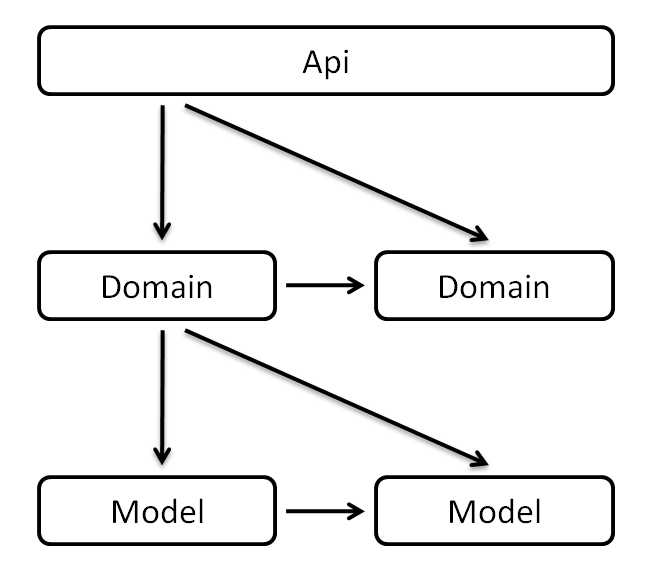
层级调用的顺序
整体上讲根据从Api接口层、Domain领域层再到Model数据源层的顺序进行开发。
在开发过程中,需要注意不能越层调用也不能逆向调用,即不能Api调用Model。而应该是上层调用下层,或者同层级调用,也就是说,我们应该:
- Api层调用Domain层
- Domain层调用Domain层
- Domain层调用Model层
- Model层调用Model层
为了更明确调用的关系,以下调用是 错误 的:
- 错误的做法1:Api层直接调用Model层
- 错误的做法2: Domain层调用Api层,也不应用将Api层对象传递给Domain层
- 错误的做法3: Model层调用Domain层
这样的约定,便于我们形成统一的开发规范,降低学习维护成本。
比如需要添加缓存,我们知道应该定位到Model层数据源进行扩展;若发现业务规则处理不当,则应该进入Domain层探其究竟;如果需要对接口的参数进行调整,即使是新手也知道应该找到对应的Api文件进行改动。