
了解HBase
HBase 概述
HBase是Hadoop的生态系统,是建立在Hadoop文件系统(HDFS)之上的分布式、面向列的数据库,通过利用Hadoop的文件系统提供容错能力。如果你需要进行实时读写或者随机访问大规模的数据集的时候,请考虑使用HBase!
HBase作为Google Bigtable的开源实现,Google Bigtable利用GFS作为其文件存储系统类似,则HBase利用Hadoop HDFS作为其文件存储系统;Google通过运行MapReduce来处理Bigtable中的海量数据,同样,HBase利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
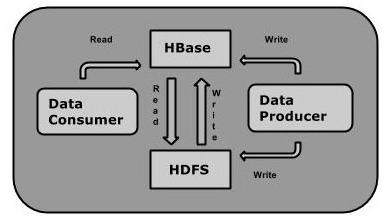
HBase处理数据
虽然Hadoop是一个高容错、高延时的分布式文件系统和高并发的批处理系统,但是它不适用于提供实时计算;HBase是可以提供实时计算的分布式数据库,数据被保存在HDFS分布式文件系统上,由HDFS保证期高容错性,但是再生产环境中,HBase是如何基于hadoop提供实时性呢? HBase上的数据是以StoreFile(HFile)二进制流的形式存储在HDFS上block块儿中;但是HDFS并不知道的HBase用于存储什么,它只把存储文件认为是二进制文件,也就是说,HBase的存储数据对于HDFS文件系统是透明的。
HBase与HDFS
在下面的表格中,我们对HDFS与HBase进行比较:
| HDFS | HBase |
|---|---|
| HDFS适于存储大容量文件的分布式文件系统。 | HBase是建立在HDFS之上的数据库。 |
| HDFS不支持快速单独记录查找。 | HBase提供在较大的表快速查找 |
| HDFS提供了高延迟批量处理;没有批处理概念。 | HBase提供了数十亿条记录低延迟访问单个行记录(随机存取)。 |
| HDFS提供的数据只能顺序访问。 | HBase内部使用哈希表和提供随机接入,并且其存储索引,可将在HDFS文件中的数据进行快速查找。 |
HBase 数据模型
HBase通过表格的模式存储数据,每个表格由列和行组成,其中,每个列又被划分为若干个列族(row family),请参考下面的图:
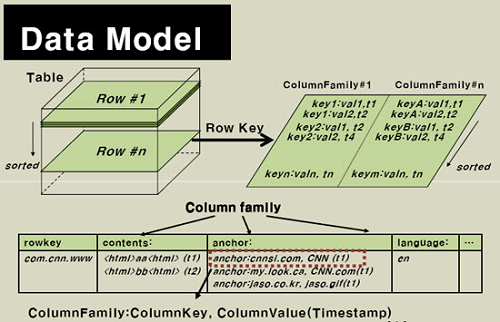
现在我们来看看HBase的逻辑数据模型与物理数据模型(实际存储的数据模型):
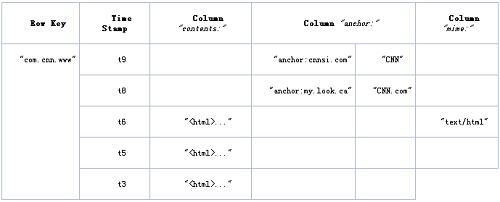
逻辑数据模型:
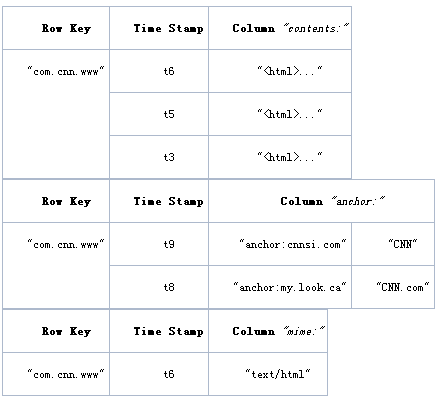
物理数据模型:
HBase 架构
下图显示了HBase的组成结构:
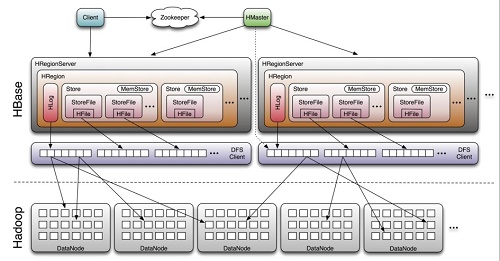
通过上图我们可以得出Hbase中的每张表都按照一定的范围被分割成多个子表(HRegion),默认一个HRegion超过 256M 就要被分割成两个,由 HRegionServer管理,管理哪些HRegion由HMaster分配。
现在我们来介绍一下HBase中的一些组成部件以及它们起到的作用:
Client:包含访问HBase的接口,并维护cache来加快对HBase的访问。
Zookeeper:HBase依赖Zookeeper,默认情况下HBase管理Zookeeper实例(启动或关闭Zookeeper),Master与RegionServers启动时会向Zookeeper注册。Zookeeper的作用如下:
- 保证任何时候,集群中只有一个master
- 存储所有Region的寻址入口
- 实时监控Region server的上线和下线信息。并实时通知给master
- 存储HBase的schema和table元数据
HRegionServer:用来维护master分配给他的region,处理对这些region的io请求;负责切分正在运行过程中变的过大的region。
HRegion:HBase表在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。Region按大小分隔,每个表一般是只有一个region,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。
Store:每一个Region由一个或多个Store组成,至少是一个Store,HBase会把一起访问的数据放在一个Store里面,即为每个ColumnFamily建一个Store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个memStore和0或者多个StoreFile组成。Store的大小被HBase用来判断是否需要切分Region。
StoreFile:memStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。
HLog:HLog记录数据的所有变更,可以用来恢复文件,一旦region server 宕机,就可以从log中进行恢复。
LogFlusher:一个LogFlusher的类是用来调用HLog.optionalSync()的。
HBase 的应用
- HBase是用来当有需要写重的应用程序。
- HBase可以帮助快速随机访问数据。
- HBase被许多公司所采纳,例如,Facebook、Twitter、Yahoo!、Adobe、OpenPlaces、WorldLingo等等。