
TensorFlow 机器学习的学习方式
作者:谭东
一般根据我们的数据类型的不同,对相应问题的建模也有不同的方式。在机器学习或者人工智能领域,人们首先会考虑算法的学习方式。在机器学习领域,有几种主要的学习方式。将算法按照学习方式分类是一个不错的想法,这样可以让人们在建模和算法选择的时候考虑能根据输入数据来选择最合适的算法来获得最好的结果。
主要分为:监督学习,非监督学习,半监督学习和强化学习。监督学习主要用于回归和分类;半监督学习主要用于分类,回归,半监督聚类;无监督学习主要用于聚类。
那我们先看下这几种学习方式的特点和差别:
1)监督学习(Supervised learning)
监督学习是指利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。是从标记的训练数据来推断一个功能的机器学习任务,也就是样本标签打好了。训练数据包括一套训练示例。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。监督学习算法是分析该训练数据,并产生一个推断的功能,其可以用于映射出新的实例。一个最佳的方案将允许该算法来正确地决定那些看不见的实例的类标签。这就要求学习算法是在一种“合理”的方式从一种从训练数据到看不见的情况下形成。
举个例子:监督学习就像我们在学习时候旁边有老师指点一样,老师知道你输入的数据是正确还是错误,他可以利用他所知道的数据帮你进行正确和错误分类和指导。监督学习就是人们常说的分类,我们根据已有的训练样本,也就是数据进行了标记,输入和输出是对应的。那么我们就可以根据这个已经训练好的模型去判断和映射其他输入的数据的对应的输出,也就实现了对未知数据的分类。类似仿生学,我们从小并不知道什么是手机、电视、鸟、猪,那么这些东西就是输入数据,而家长会根据他的经验指点告诉我们哪些是手机、电视、鸟、猪。这就是通过模型判断分类。当我们掌握了这些数据分类模型,我们就可以对这些数据进行自己的判断和分类了。
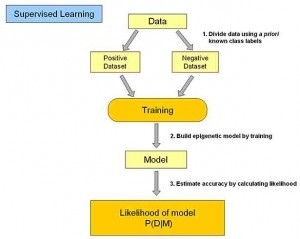
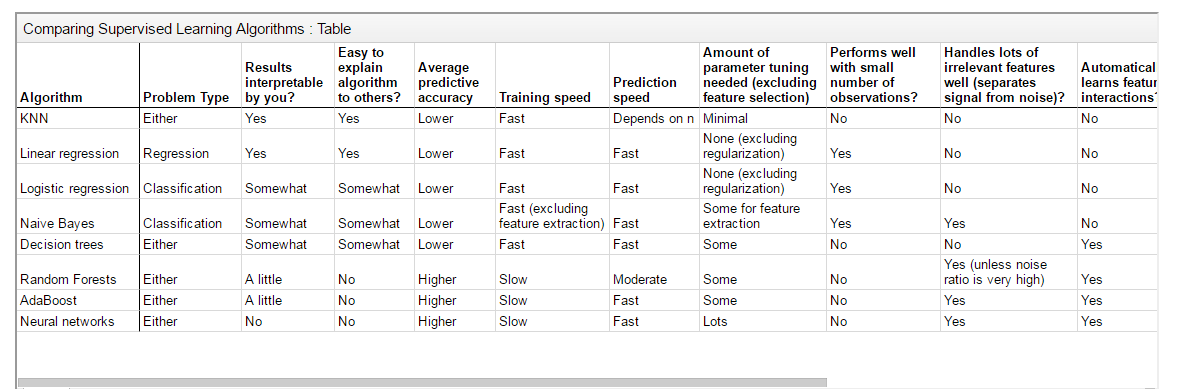
在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。监督式学习的常见应用场景如分类问题和回归问题。常见监督式学习算法有决策树(ID3,C4.5算法等),朴素贝叶斯分类器,最小二乘法,逻辑回归(Logistic Regression),支持向量机(SVM),K最近邻算法(KNN,K-NearestNeighbor),线性回归(LR,Linear Regreesion),人工神经网络(ANN,Artificial Neural Network),集成学习以及反向传递神经网络(Back Propagation Neural Network)等等。下图是几种监督式学习算法的比较:
2)非监督学习(Unsupervised learing)
非监督学习是另一种研究的比较多的学习方法,它与监督学习的不同之处,在于我们事先没有任何训练样本,而需要直接对数据进行建模。是否有监督(Supervised),就看输入数据是否有标签(Label)。输入数据有标签(即数据有标识分类),则为有监督学习,没标签则为无监督学习。这听起来似乎有点不可思议,但是在我们自身认识世界的过程中很多处都用到了无监督学习。比如我们去参观一个画展,我们完全对艺术一无所知,但是欣赏完多幅作品之后,我们也能把它们分成不同的派别(比如哪些更朦胧一点,哪些更写实一些,即使我们不知道什么叫做朦胧派,什么叫做写实派,但是至少我们能把他们分为两个类)。无监督学习里典型的例子就是聚类了。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了。 在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。
非监督学习在聚类上同监督学习分类效果相比无法做到同样的完美,那么我们为什么还要使用非监督学习聚类?因为在很多实际应用中,并没有大量的标识数据进行使用,并且标识数据需要大量的人工工作量,非常困难。那么我们就需要非监督学习根据数据的相似度,特征及相关联系进行模糊判断分类。
常见的应用场景包括关联规则的学习以及聚类等。常见非监督学习算法包括聚类算法、奇异值分解、主成分分析(PCA)、SVD矩阵分解、独立成分分析(ICA)、Apriori算法以及K-均值算法(K-Means)、稀疏自编码(sparse auto-encoder)等等。
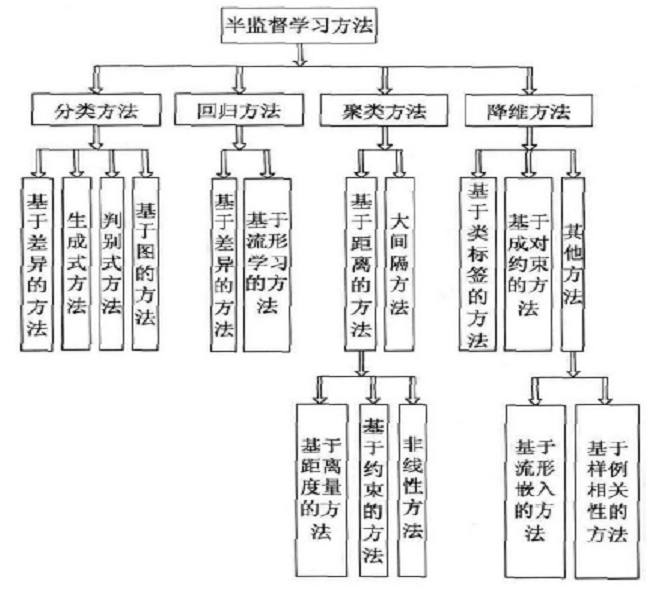
3)半监督学习(Semi-supervised Learning)
半监督学习(Semi-Supervised Learning,SSL)是模式识别和机器学习领域研究的重点问题,是监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。当使用半监督学习时,将会要求尽量少的人员来从事工作,同时,又能够带来比较高的准确性,因此,半监督学习目前正越来越受到人们的重视。
在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。
半监督学习有两个样本集,一个有标记,一个没有标记。分别记作Lable={(xi,yi)},Unlabled={(xi)},并且数量,L<<U。
1、单独使用有标记样本,我们能够生成有监督分类算法
2、单独使用无标记样本,我们能够生成无监督聚类算法
3、两者都使用,我们希望在1中加入无标记样本,增强有监督分类的效果;同样的,我们希望在2中加入有标记样本,增强无监督聚类的效果
一般而言,半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类,也就是在1中加入无标记样本,增强分类效果[1]。应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如自训练算法(self-training)、多视角算法(Multi-View)、生成模型(Enerative Models)、图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM)等。
(图片来自百度百科)
4)强化学习(Reinforcement learning)
又称再励学习、评价学习,是一种重要的机器学习方法,在智能控制机器人及分析预测等领域有许多应用。但在传统的机器学习分类中没有提到过强化学习,而在连接主义学习中,把学习算法分为三种类型,即非监督学习(unsupervised learning)、监督学习(supervised leaning)和强化学习。
在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整。常见的应用场景包括动态系统以及机器人控制等。常见算法包括Q-Learning以及时间差学习(Temporal difference learning)。在企业数据应用的场景下, 人们最常用的可能就是监督式学习和非监督式学习的模型。 在图像识别等领域,由于存在大量的非标识的数据和少量的可标识数据, 目前半监督式学习是一个很热的话题。 而强化学习更多的应用在机器人控制及其他需要进行系统控制的领域。
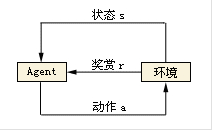
强化学习灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。这个方法具有普适性,因此在其他许多领域都有研究,例如博弈论、控制论、运筹学、信息论、模拟优化方法、多主体系统学习、群体智能、统计学以及遗传算法。 它的本质就是解决“决策(decision making)”问题,即学会自动进行决策。它在没有任何label告诉算法应该怎么做的情况下,通过先尝试做出一些行为——然后得到一个结果,通过判断这个结果是对还是错来对之前的行为进行反馈。由这个反馈来调整之前的行为,通过不断的调整算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。
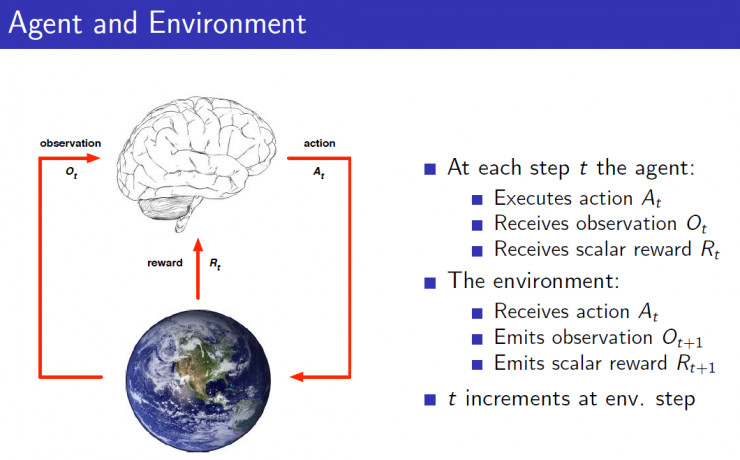
重点:强化学习其实就是自动进行决策,并且可以做连续决策。强化学习有很多应用,比如自动直升机,机器人控制,手机网络路由,市场决策,工业控制,高效网页索引,无人驾驶,AlphaGo,玩游戏,还在制造业、库存处理、电商、广告、推荐、金融、医疗等与我们生活息息相关的领域也有应用。像强化学习里的Q-Learning可以很好的处理动态定价问题。在电商中,也可以用强化学习算法来学习和分析顾客行为,定制产品和服务以满足客户的个性化需求。如双 11 推荐场景中,阿里巴巴使用了深度强化学习与自适应在线学习,通过持续机器学习和模型优化建立决策引擎,对海量用户行为以及百亿级商品特征进行实时分析,帮助每一个用户迅速发现宝贝,提高人和商品的配对效率。还有,利用强化学习将手机用户点击率提升了 10-20%。例如一家日本公司 Fanuc,工厂机器人在拿起一个物体时,会捕捉这个过程的视频,记住它每次操作的行动,操作成功还是失败了,积累经验,下一次可以更快更准地采取行动。
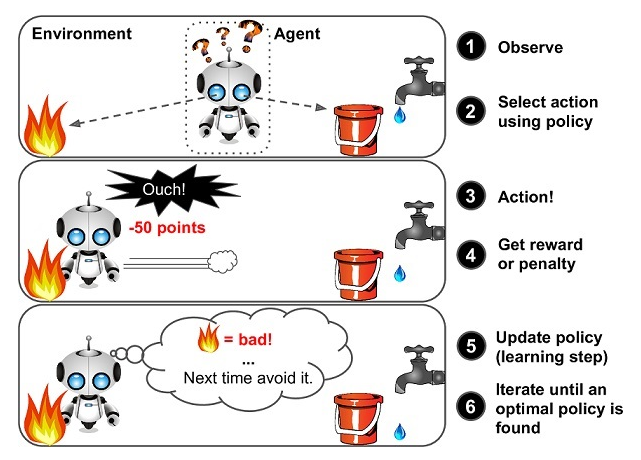
举个例子:以小孩学习走路为例,走路时候小孩需要知道先进行决定先迈那条腿,如果第一步作对了,那么就会得到奖励,错了,那么记录下来,再进行第二次走路时候进行学习更正。例如在向用户推荐新闻文章的任务中,非监督式会找到用户先前已经阅读过类似的文章并向他们推荐其一,而强化学习将通过向用户先推荐少量的新闻,并不断获得来自用户的反馈,最后构建用户可能会喜欢的文章的“知识图”。
强化学习常用算法:TD算法(时间差分学习,Temporal Difference)、SARSA算法、Q-Learning算法等。我们当然也需要了解马尔可夫决策过程(MDP,Markov Decision Processes),这样更利于我们对强化学习的理解。
后面讲给大家一一列举相关的常用算法。
参考文献:
[1]机器学习.Tom M.Mitchell
[2]http://www.asimovinstitute.org/neural-network-zoo/
