
Apache Pig 架构
用于使用Pig分析Hadoop中的数据的语言称为 Pig Latin ,是一种高级数据处理语言,它提供了一组丰富的数据类型和操作符来对数据执行各种操作。
要执行特定任务时,程序员使用Pig,需要用Pig Latin语言编写Pig脚本,并使用任何执行机制(Grunt Shell,UDFs,Embedded)执行它们。执行后,这些脚本将通过应用Pig框架的一系列转换来生成所需的输出。
在内部,Apache Pig将这些脚本转换为一系列MapReduce作业,因此,它使程序员的工作变得容易。Apache Pig的架构如下所示。
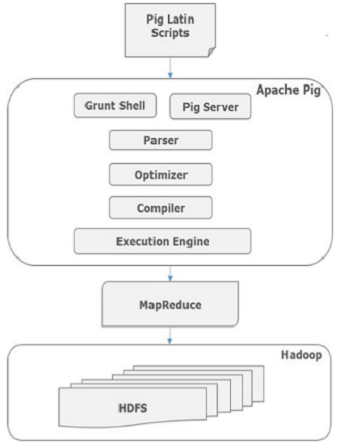
Apache Pig组件
如图所示,Apache Pig框架中有各种组件。让我们来看看主要的组件。
Parser(解析器)
最初,Pig脚本由解析器处理,它检查脚本的语法,类型检查和其他杂项检查。解析器的输出将是DAG(有向无环图),它表示Pig Latin语句和逻辑运算符。在DAG中,脚本的逻辑运算符表示为节点,数据流表示为边。
Optimizer(优化器)
逻辑计划(DAG)传递到逻辑优化器,逻辑优化器执行逻辑优化,例如投影和下推。
Compiler(编译器)
编译器将优化的逻辑计划编译为一系列MapReduce作业。
Execution engine(执行引擎)
最后,MapReduce作业以排序顺序提交到Hadoop。这些MapReduce作业在Hadoop上执行,产生所需的结果。
Pig Latin数据模型
Pig Latin的数据模型是完全嵌套的,它允许复杂的非原子数据类型,例如 map 和 tuple 。下面给出了Pig Latin数据模型的图形表示。
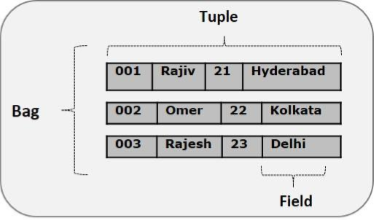
Atom(原子)
Pig Latin中的任何单个值,无论其数据类型,都称为 Atom 。它存储为字符串,可以用作字符串和数字。int,long,float,double,chararray和bytearray是Pig的原子值。一条数据或一个简单的原子值被称为字段。例:“raja“或“30"
Tuple(元组)
由有序字段集合形成的记录称为元组,字段可以是任何类型。元组与RDBMS表中的行类似。例:(Raja,30)
Bag(包)
一个包是一组无序的元组。换句话说,元组(非唯一)的集合被称为包。每个元组可以有任意数量的字段(灵活模式)。包由“{}"表示。它类似于RDBMS中的表,但是与RDBMS中的表不同,不需要每个元组包含相同数量的字段,或者相同位置(列)中的字段具有相同类型。
例:{(Raja,30),(Mohammad,45)}
包可以是关系中的字段;在这种情况下,它被称为内包(inner bag)。
例:{Raja,30, {9848022338,raja@gmail.com,} }
Map(映射)
映射(或数据映射)是一组key-value对。key需要是chararray类型,且应该是唯一的。value可以是任何类型,它由“[]"表示,
例:[name#Raja,age#30]
Relation(关系)
一个关系是一个元组的包。Pig Latin中的关系是无序的(不能保证按任何特定顺序处理元组)。