
Apache Pig 安装
本章将介绍如何在系统中下载,安装和设置 Apache Pig 。
先决条件
在你运行Apache Pig之前,必须在系统上安装好Hadoop和Java。因此,在安装Apache Pig之前,请按照以下链接中提供的步骤安装Hadoop和Java://www.w3cschool.cn/hadoop/hadoop_enviornment_setup.htm
下载Apache Pig
首先,从以下网站下载最新版本的Apache Pig:https://pig.apache.org/
步骤1
打开Apache Pig网站的主页。在News部分下,点击链接release page,如下面的快照所示。
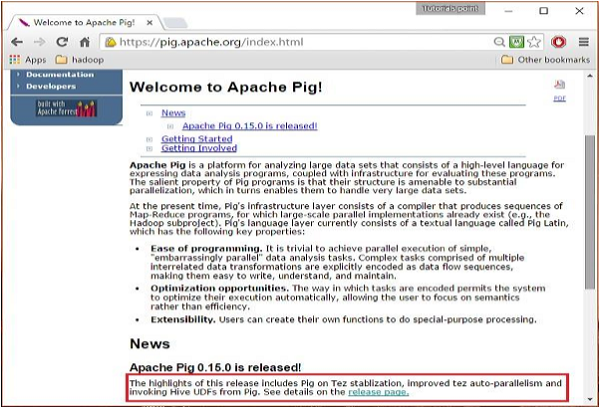
步骤2
点击指定的链接后,你将被重定向到 Apache Pig Releases 页面。在此页面的Download部分下,单击链接,然后你将被重定向到具有一组镜像的页面。
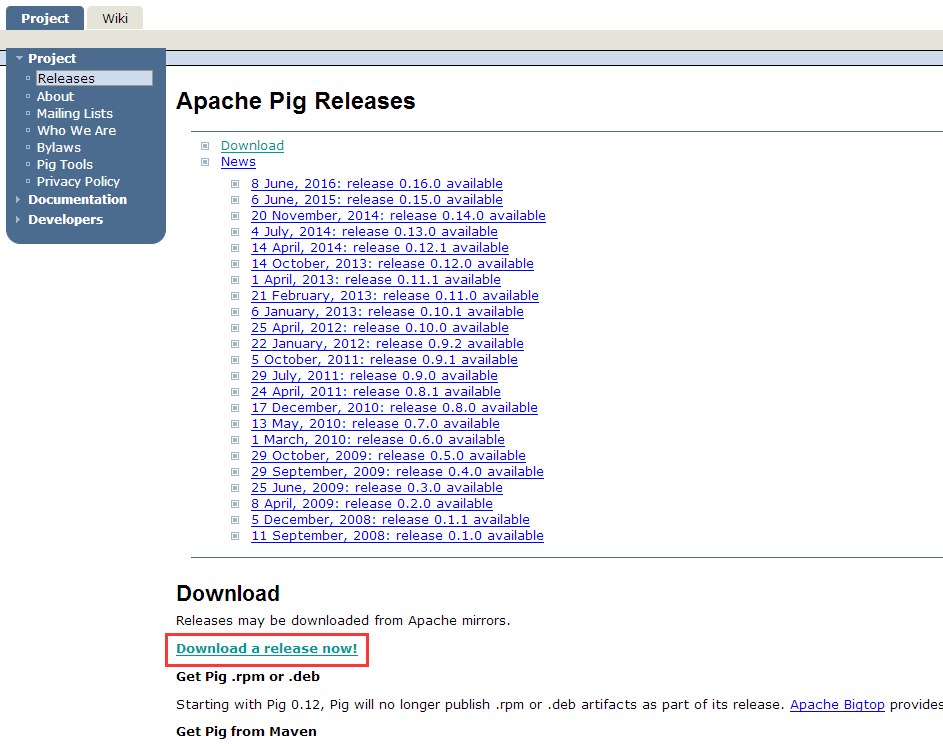
步骤3
选择并单击这些镜像中的任一个,如下所示。
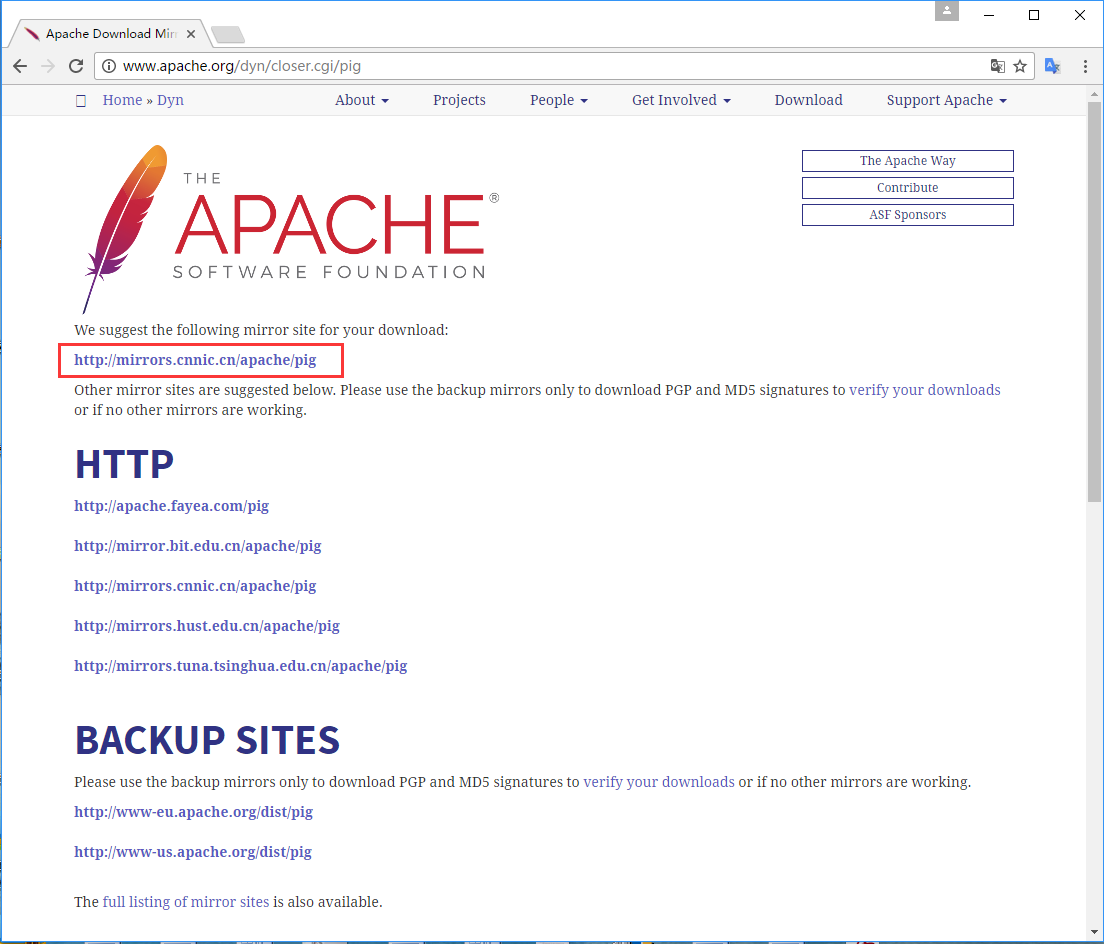
步骤4
这些镜像将带您进入 Pig Releases 页面。 此页面包含Apache Pig的各种版本。 单击其中的最新版本。
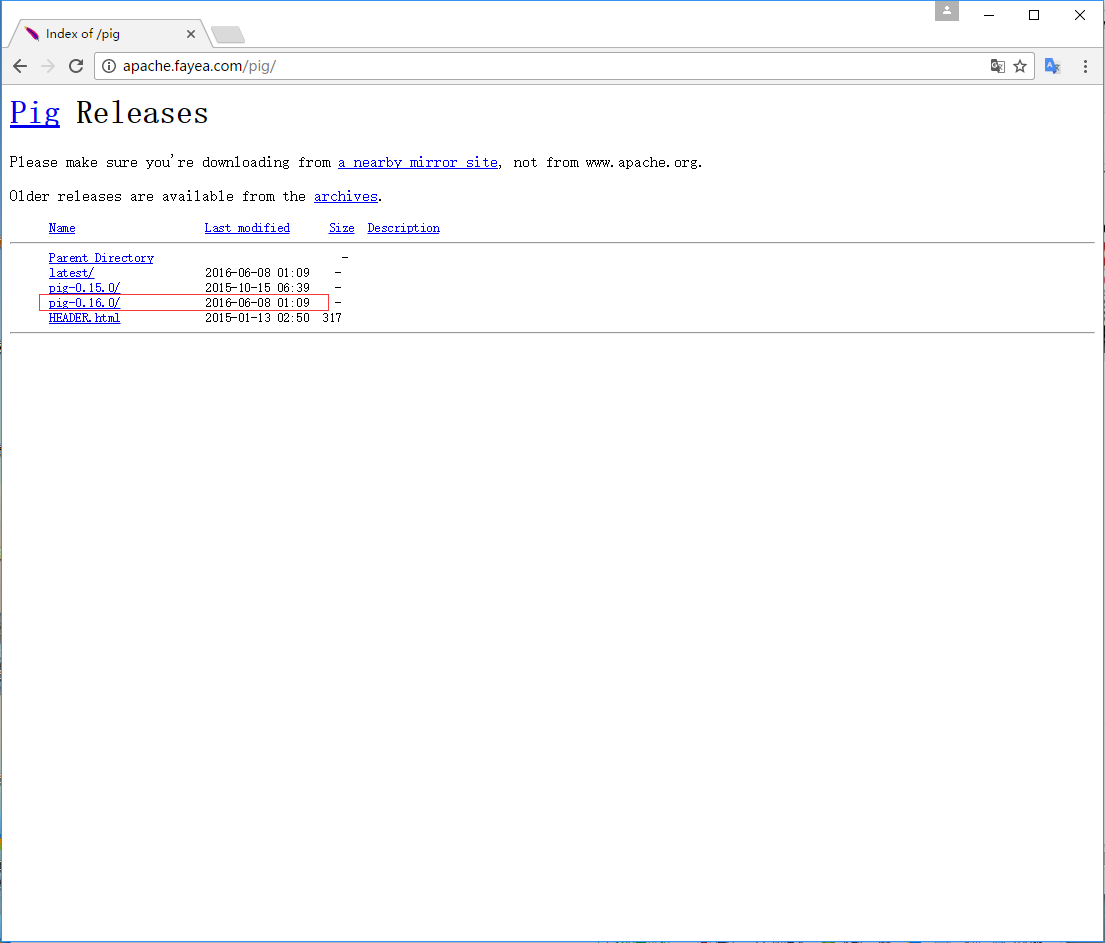
步骤5
在这些文件夹中,有发行版中的Apache Pig的源文件和二进制文件。下载Apache Pig 0.16, pig0.16.0-src.tar.gz 和 pig-0.16.0.tar.gz 的源和二进制文件的tar文件。
安装Apache Pig
下载Apache Pig软件后,按照以下步骤将其安装在Linux环境中。
步骤1
在安装了 Hadoop,Java和其他软件的安装目录的同一目录中创建一个名为Pig的目录。(在我们的教程中,我们在名为Hadoop的用户中创建了Pig目录)。
$ mkdir Pig
第2步
提取下载的tar文件,如下所示。
$ cd Downloads/ $ tar zxvf pig-0.15.0-src.tar.gz $ tar zxvf pig-0.15.0.tar.gz
步骤3
将 pig-0.16.0-src.tar.gz 文件的内容移动到之前创建的 Pig 目录,如下所示。
$ mv pig-0.16.0-src.tar.gz/* /home/Hadoop/Pig/
配置Apache Pig
安装Apache Pig后,我们必须配置它。要配置,我们需要编辑两个文件 - bashrc和pig.properties 。
.bashrc文件
在 .bashrc 文件中,设置以下变量
PIG_HOME 文件夹复制到Apache Pig的安装文件夹
PATH 环境变量复制到bin文件夹
PIG_CLASSPATH 环境变量复制到安装Hadoop的etc(配置)文件夹(包含core-site.xml,hdfs-site.xml和mapred-site.xml文件的目录)。
export PIG_HOME = /home/Hadoop/Pig export PATH = PATH:/home/Hadoop/pig/bin export PIG_CLASSPATH = $HADOOP_HOME/conf
pig.properties文件
在Pig的 conf 文件夹中,我们有一个名为 pig.properties 的文件。在pig.properties文件中,可以设置如下所示的各种参数。
pig -h properties
支持以下属性:
Logging: verbose = true|false; default is false. This property is the same as -v
switch brief=true|false; default is false. This property is the same
as -b switch debug=OFF|ERROR|WARN|INFO|DEBUG; default is INFO.
This property is the same as -d switch aggregate.warning = true|false; default is true.
If true, prints count of warnings of each type rather than logging each warning.
Performance tuning: pig.cachedbag.memusage=<mem fraction>; default is 0.2 (20% of all memory).
Note that this memory is shared across all large bags used by the application.
pig.skewedjoin.reduce.memusagea=<mem fraction>; default is 0.3 (30% of all memory).
Specifies the fraction of heap available for the reducer to perform the join.
pig.exec.nocombiner = true|false; default is false.
Only disable combiner as a temporary workaround for problems.
opt.multiquery = true|false; multiquery is on by default.
Only disable multiquery as a temporary workaround for problems.
opt.fetch=true|false; fetch is on by default.
Scripts containing Filter, Foreach, Limit, Stream, and Union can be dumped without MR jobs.
pig.tmpfilecompression = true|false; compression is off by default.
Determines whether output of intermediate jobs is compressed.
pig.tmpfilecompression.codec = lzo|gzip; default is gzip.
Used in conjunction with pig.tmpfilecompression. Defines compression type.
pig.noSplitCombination = true|false. Split combination is on by default.
Determines if multiple small files are combined into a single map.
pig.exec.mapPartAgg = true|false. Default is false.
Determines if partial aggregation is done within map phase, before records are sent to combiner.
pig.exec.mapPartAgg.minReduction=<min aggregation factor>. Default is 10.
If the in-map partial aggregation does not reduce the output num records by this factor, it gets disabled.
Miscellaneous: exectype = mapreduce|tez|local; default is mapreduce. This property is the same as -x switch
pig.additional.jars.uris=<comma seperated list of jars>. Used in place of register command.
udf.import.list=<comma seperated list of imports>. Used to avoid package names in UDF.
stop.on.failure = true|false; default is false. Set to true to terminate on the first error.
pig.datetime.default.tz=<UTC time offset>. e.g. +08:00. Default is the default timezone of the host.
Determines the timezone used to handle datetime datatype and UDFs.
Additionally, any Hadoop property can be specified.
验证安装
通过键入version命令验证Apache Pig的安装。如果安装成功,你将获得Apache Pig的正式版本,如下所示。
$ pig –version Apache Pig version 0.16.0 (r1682971) compiled Jun 01 2015, 11:44:35