
scrapy 2.3 网络工具
在抓取过程中,您可能会遇到动态网页,其中页面的某些部分是通过多个请求动态加载的。虽然这很棘手,但是 Network-tool in the Developer Tools greatly facilitates this task. To demonstrate the Network-tool, let's take a look at the page quotes.toscrape.com/scroll .
页面与基本页面非常相似 quotes.toscrape.com -第页,但不是上面提到的 Next 按钮,则当您滚动到底部时,页面会自动加载新的引号。我们可以直接尝试不同的xpath,但是我们将从Scrapy shell中检查另一个非常有用的命令:
$ scrapy shell "quotes.toscrape.com/scroll"
(...)
>>> view(response)
浏览器窗口应该和网页一起打开,但有一个关键的区别:我们看到的不是引用,而是一个带单词的绿色条。 Loading... .

这个 view(response) 命令让我们查看shell或稍后蜘蛛从服务器接收到的响应。这里我们看到加载了一些基本模板,其中包括标题、登录按钮和页脚,但是缺少引号。这告诉我们报价是从不同的请求加载的,而不是 quotes.toscrape/scroll .
如果你点击 Network 选项卡,您可能只能看到两个条目。我们要做的第一件事是通过单击 Persist Logs . 如果禁用此选项,则每次导航到不同的页面时,日志都会自动清除。启用这个选项是一个很好的默认设置,因为它可以让我们控制何时清除日志。
如果我们现在重新加载页面,您将看到日志中填充了六个新的请求。
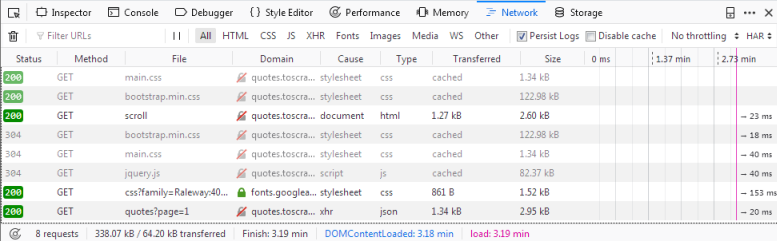
在这里,我们可以看到在重新加载页面时发出的每个请求,并且可以检查每个请求及其响应。因此,让我们找出我们的报价来自哪里:
首先单击带有名称的请求 scroll . 在右边,您现在可以检查请求。在 Headers 您将找到有关请求头的详细信息,例如URL、方法、IP地址等。我们将忽略其他选项卡并直接单击 Response .
你应该在里面看到什么 Preview 窗格是呈现的HTML代码,这正是我们调用 view(response) 在贝壳里。相应地 type 日志中的请求为 html . 其他请求的类型如下 css 或 js 但是我们感兴趣的是一个要求 quotes?page=1 与类型 json .
如果我们点击这个请求,我们会看到请求的URL是 http://quotes.toscrape.com/api/quotes?page=1 响应是一个包含我们的引号的JSON对象。我们也可以右键单击请求并打开 Open in new tab 以获得更好的概述。
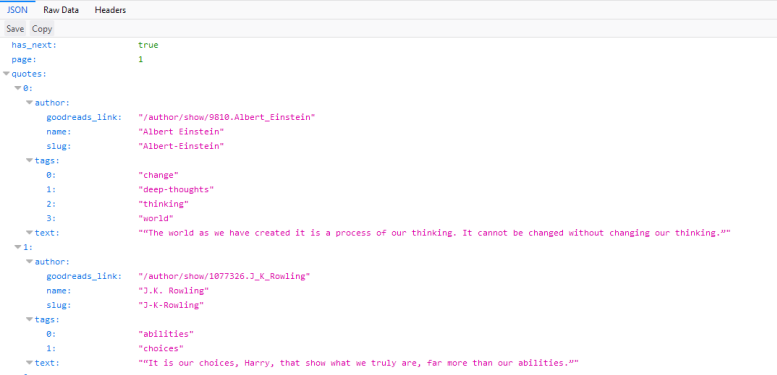
有了这个响应,我们现在可以轻松地解析JSON对象,并请求每个页面获取站点上的每个引用:
import scrapy
import json
class QuoteSpider(scrapy.Spider):
name = 'quote'
allowed_domains = ['quotes.toscrape.com']
page = 1
start_urls = ['http://quotes.toscrape.com/api/quotes?page=1']
def parse(self, response):
data = json.loads(response.text)
for quote in data["quotes"]:
yield {"quote": quote["text"]}
if data["has_next"]:
self.page += 1
url = f"http://quotes.toscrape.com/api/quotes?page={self.page}"
yield scrapy.Request(url=url, callback=self.parse)
这个蜘蛛程序从QuotesAPI的第一页开始。对于每个响应,我们分析 response.text 并分配给 data . 这让我们可以像在Python字典上一样对JSON对象进行操作。我们迭代 quotes 打印出 quote["text"] . 如果方便的话 has_next 元素是 true (尝试加载 quotes.toscrape.com/api/quotes?page=10 在您的浏览器或大于10的页码中,我们增加 page 属性与 yield 一个新的请求,将递增的页码插入到 url .
在更复杂的网站中,很难轻松地复制请求,因为我们需要添加 headers 或 cookies 让它发挥作用。在这些情况下,您可以在中导出请求 cURL 格式化,在网络工具中右键单击它们并使用 from_curl() 方法生成等效请求:
from scrapy import Request
request = Request.from_curl(
"curl 'http://quotes.toscrape.com/api/quotes?page=1' -H 'User-Agent: Mozil"
"la/5.0 (X11; Linux x86_64; rv:67.0) Gecko/20100101 Firefox/67.0' -H 'Acce"
"pt: */*' -H 'Accept-Language: ca,en-US;q=0.7,en;q=0.3' --compressed -H 'X"
"-Requested-With: XMLHttpRequest' -H 'Proxy-Authorization: Basic QFRLLTAzM"
"zEwZTAxLTk5MWUtNDFiNC1iZWRmLTJjNGI4M2ZiNDBmNDpAVEstMDMzMTBlMDEtOTkxZS00MW"
"I0LWJlZGYtMmM0YjgzZmI0MGY0' -H 'Connection: keep-alive' -H 'Referer: http"
"://quotes.toscrape.com/scroll' -H 'Cache-Control: max-age=0'")
或者,如果您想知道重新创建该请求所需的参数,可以使用 curl_to_request_kwargs() 函数获取具有等效参数的字典:
scrapy.utils.curl.curl_to_request_kwargs(curl_command, ignore_unknown_options=True)-
将cURL命令语法转换为请求kwargs。
- 参数
-
-
curl_command (str) -- 包含curl命令的字符串
-
ignore_unknown_options (bool) -- 如果为true,则当cURL选项未知时仅发出警告。否则将引发错误。(默认值:True)
-
- 返回
-
请求字典
注意,要将cURL命令转换为Scrapy请求,可以使用 curl2scrapy .
如你所见,在 Network -工具我们能够轻松地复制页面滚动功能的动态请求。对动态页面进行爬行可能非常困难,页面也可能非常复杂,但是(主要)归根结底就是识别正确的请求并在蜘蛛中复制它。