
scrapy 2.3 查看网站
到目前为止,开发人员工具最方便的特性是 Inspector feature, which allows you to inspect the underlying HTML code of any webpage. To demonstrate the Inspector, let's look at the quotes.toscrape.com 现场。
在这个网站上,我们总共有来自不同作者的十个引用,其中有特定的标签,还有前十个标签。假设我们想要提取这个页面上的所有引用,而不需要任何关于作者、标签等的元信息。
我们不必查看页面的整个源代码,只需右键单击一个报价并选择 Inspect Element (Q) 打开了 Inspector . 在里面你应该看到这样的东西:
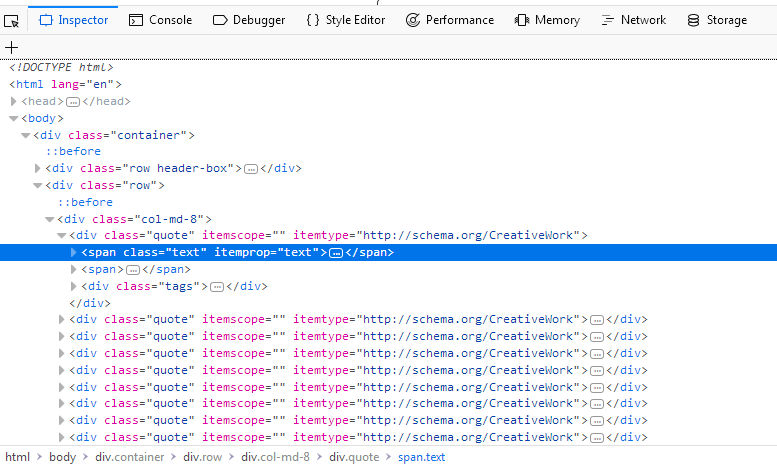
我们感兴趣的是:
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">(...)</span>
<span>(...)</span>
<div class="tags">(...)</div>
</div>
如果你在第一个上面徘徊 div 正上方 span 在屏幕截图中突出显示的标签,您将看到网页的相应部分也会突出显示。现在我们有了一个部分,但是我们在任何地方都找不到报价文本。
的优势 Inspector 它自动展开和折叠网页的部分和标签,大大提高了可读性。您可以通过单击标签前面的箭头或直接双击标签来展开和折叠标签。如果我们扩大 span 带标签 class= "text" 我们将看到我们单击的报价文本。这个 Inspector 允许您将xpath复制到选定的元素。让我们试试看。
首先在http://quotes.toscrape.com/在终端中:
$ scrapy shell "http://quotes.toscrape.com/"
然后,返回web浏览器,右键单击 span 选择标记 Copy > XPath 然后把它贴在这个破壳里:
>>> response.xpath('/html/body/div/div[2]/div[1]/div[1]/span[1]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”']
添加 text() 最后,我们可以用这个基本选择器提取第一个报价。但这个xpath并没有那么聪明。它所做的就是在源代码中沿着所需的路径从 html . 那么让我们看看我们是否可以改进一下xpath:
如果我们检查 Inspector 我们将再次看到,在我们的 div 标签我们有九个相同的 div 标签,每个标签都具有与第一个相同的属性。如果我们扩展其中任何一个,我们将看到与第一个报价相同的结构:两个 span 标签和一个 div 标签。我们可以扩大每个 span 带标签 class="text" 在我们内部 div 标记并查看每个引用:
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
</span>
<span>(...)</span>
<div class="tags">(...)</div>
</div>
有了这些知识,我们可以改进我们的xpath:我们只需选择 span 标签与 class="text" 通过使用 has-class-extension :
>>> response.xpath('//span[has-class("text")]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
'“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
'“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
...]
通过一个简单、更聪明的xpath,我们能够从页面中提取所有的引号。我们可以在第一个xpath上构建一个循环,以增加最后一个xpath的数量。 div ,但这将不必要地复杂,只需使用 has-class("text") 我们能够在一行中提取所有报价。
这个 Inspector 还有很多其他有用的功能,比如在源代码中搜索或者直接滚动到您选择的元素。让我们演示一个用例:
说你想找到 Next 页面上的按钮。类型 Next 在搜索栏的右上角 Inspector . 你应该得到两个结果。第一个是 li 带标签 class="next" ,第二个是 a 标签。右键单击 a 标记与选择 Scroll into View . 如果您将鼠标悬停在标签上,您将看到突出显示的按钮。从这里我们可以很容易地创建一个 Link Extractor 跟随分页。在这样一个简单的站点上,可能不需要从视觉上查找元素,而是 Scroll into View 函数在复杂的站点上非常有用。
请注意,搜索栏也可用于搜索和测试CSS选择器。例如,您可以搜索 span.text 查找所有报价文本。而不是全文搜索,这将搜索 span 带标签 class="text" 在页面中。