Tensorflow.js 图片训练
这篇文章中,我们将使用 CNN 构建一个 Tensorflow.js 模型来分辨手写的数字。首先,我们通过使之“查看”数以千计的数字图片以及他们对应的标识来训练分辨器。然后我们再通过此模型从未“见到”过的测试数据评估这个分辨器的精确度。
一、运行代码
这篇文章的全部代码可以在仓库 TensorFlow.js examples 中的 tfjs-examples/mnist 下找到,你可以通过下面的方式 clone 下来然后运行这个 demo:
$ git clone https://github.com/tensorflow/tfjs-examples $ cd tfjs-examples/mnist $ yarn $ yarn watch
上面的这个目录完全是独立的,所以完全可以 copy 下来然后创建你个人的项目。
二、数据相关
这里我们将会使用 MNIST 的手写数据,这些我们将要去分辨的手写数据如下所示:

为了预处理这些数据,我们已经写了 data.js, 这个文件包含了 Minsdata 类,而这个类可以帮助我们从 MNIST 的数据集中获取到任意的一些列的 MNIST。
而MnistData这个类将全部的数据分割成了训练数据和测试数据。我们训练模型的时候,分辨器就会只观察训练数据。而当我们评价模型时,我们就仅仅使用测试数据,而这些测试数据是模型还没有看见到的,这样就可以来观察模型预测全新的数据了。
这个 MnistData 有两个共有方法:
1、nextTrainBatch(batchSize): 从训练数据中返回一批任意的图片以及他们的标识。
2、nextTestBatch(batchSize): 从测试数据中返回一批图片以及他们的标识。
注意:当我们训练 MNIST 分辨器时,应当注意数据获取的任意性是非常重要的,这样模型预测才不会受到我们提供图片顺序的干扰。例如,如果我们每次给这个模型第一次都提供的是数字1,那么在训练期间,这个模型就会简单的预测第一个就是 1(因为这样可以减小损失函数)。 而如果我们每次训练时都提供的是 2,那么它也会简单切换为预测 2 并且永远不会预测 1(同样的,也是因为这样可以减少损失函数)。如果每次都提供这样典型的、有代表性的数字,那么这个模型将永远也学不会做出一个精确的预测。
三、创建模型
在这一部分,我们将会创建一个卷积图片识别模型。为了这样做,我们使用了 Sequential 模型(模型中最为简单的一个类型),在这个模型中,张量(tensors)可以连续的从一层传递到下一层中。
首先,我们需要使用 tf.sequential 先初始化一个 sequential 模型:
const model = tf.sequential();
既然我们已经创建了一个模型,那么我们就可以添加层了。
四、添加第一层
我们要添加的第一层是一个 2 维的卷积层。卷积将过滤窗口掠过图片来学习空间上来说不会转变的变量(即图片中不同位置的模式或者物体将会被平等对待)。
我们可以通过 tf.layers.conv2d 来创建一个2维的卷积层,这个卷积层可以接受一个配置对象来定义层的结构,如下所示:
model.add(tf.layers.conv2d({
inputShape: [28, 28, 1],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'VarianceScaling'
}));
让我们拆分对象中的每个参数吧:
inputShape。这个数据的形状将回流入模型的第一层。在这个示例中,我们的 MNIST 例子是 28 x 28 像素的黑白图片,这个关于图片的特定的格式即[row, column, depth],所以我们想要配置一个[28, 28, 1] 的形状,其中28行和28列是这个数字在每个维度上的像素数,且其深度为 1,这是因为我们的图片只有1个颜色:kernelSize。划过卷积层过滤窗口的数量将会被应用到输入数据中去。这里,我们设置了kernalSize的值为5,也就是指定了一个5 x 5的卷积窗口。filters。这个kernelSize的过滤窗口的数量将会被应用到输入数据中,我们这里将8个过滤器应用到数据中。strides。 即滑动窗口每一步的步长。比如每当过滤器移动过图片时将会由多少像素的变化。这里,我们指定其步长为1,这意味着每一步都是1像素的移动。activation。这个activation函数将会在卷积完成之后被应用到数据上。在这个例子中,我们应用了relu函数,这个函数在机器学习中是一个非常常见的激活函数。kernelInitializer。这个方法对于训练动态的模型是非常重要的,他被用于任意地初始化模型的weights。我们这里将不会深入细节来讲,但是VarianceScaling(即这里用的)真的是一个初始化非常好的选择。
五、添加第二层
让我们为这个模型添加第二层:一个最大的池化层(pooling layer),这个层中我们将通过 tf.layers.maxPooling2d 来创建。这一层将会通过在每个滑动窗口中计算最大值来降频取样得到结果。
model.add(tf.layers.maxPooling2d({
poolSize: [2, 2],
strides: [2, 2]
}));
poolSize。这个滑动池窗口的数量将会被应用到输入的数据中。这里我们设置poolSize为[2, 2],所以这就意味着池化层将会对输入数据应用2x2的窗口。strides。 这个池化层的步长大小。比如,当每次挪开输入数据时窗口需要移动多少像素。这里我们指定strides为[2, 2],这就意味着过滤器将会以在水平方向和竖直方向上同时移动2个像素的方式来划过图片。
注意:因为 poolSize 和 strides 都是2x2,所以池化层空口将会完全不会重叠。这也就意味着池化层将会把激活的大小从上一层减少一半。
六、添加剩下的层
重复使用层结构是神经网络中的常见模式。我们添加第二个卷积层到模型,并在其后添加池化层。请注意,在我们的第二个卷积层中,我们将滤波器数量从8增加到16。还要注意,我们没有指定 inputShape,因为它可以从前一层的输出形状中推断出来:
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'VarianceScaling'
}));
model.add(tf.layers.maxPooling2d({
poolSize: [2, 2],
strides: [2, 2]
}));
接下来,我们添加一个 flatten 层,将前一层的输出平铺到一个向量中:
model.add(tf.layers.flatten());
最后,让我们添加一个 dense 层(也称为全连接层),它将执行最终的分类。 在 dense 层前先对卷积+池化层的输出执行 flatten 也是神经网络中的另一种常见模式:
model.add(tf.layers.dense({
units: 10,
kernelInitializer: 'VarianceScaling',
activation: 'softmax'
}));
我们来分析传递给 dense 层的参数。
- /
units.激活输出的数量。由于这是最后一层,我们正在做10个类别的分类任务(数字0-9),因此我们在这里使用10个units。 (有时 units 被称为神经元的数量,但我们会避免使用该术语。)
kernelInitializer.我们将对dense层使用与卷积层相同的VarianceScaling初始化策略。
activation.分类任务的最后一层的激活函数通常是softmax。Softmax将我们的10维输出向量归一化为概率分布,使得我们10个类中的每个都有一个概率值。
定义优化器
对于我们的卷积神经网络模型,我们将使用学习率为0.15的随机梯度下降(SGD)优化器:
const LEARNING_RATE = 0.15;
const optimizer = tf.train.sgd(LEARNING_RATE);
定义损失函数
对于损失函数,我们将使用通常用于优化分类任务的交叉熵( categoricalCrossentropy)。 categoricalCrossentropy 度量模型的最后一层产生的概率分布与标签给出的概率分布之间的误差,这个分布在正确的类标签中为1(100%)。 例如,下面是数字7的标签和预测值:
|class | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |----------|---|---|---|---|---|---|---|---|---|---| |label | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |prediction|.1 |.01|.01|.01|.20|.01|.01|.60|.03|.02|
如果预测的结果是数字7的概率很高,那么 categoricalCrossentropy 会给出一个较低的损失值,而如果7的概率很低,那么 categoricalCrossentropy 的损失就会更高。在训练过程中,模型会更新它的内部参数以最小化在整个数据集上的 categoricalCrossentropy。
定义评估指标
对于我们的评估指标,我们将使用准确度,该准确度衡量所有预测中正确预测的百分比。
编译模型
为了编译模型,我们传入一个由优化器,损失函数和一系列评估指标(这里只是'精度')组成的配置对象:
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
配置批量大小
在开始训练之前,我们需要定义一些与 batch size 相关的参数:
const BATCH_SIZE = 64;
const TRAIN_BATCHES = 100;
const TEST_BATCH_SIZE = 1000;
const TEST_ITERATION_FREQUENCY = 5;
进一步了解分批量和批量大小
为了充分利用 GPU 并行化计算的能力,我们希望将多个输入批量处理,并使用单个前馈网络调用将他们馈送到网络。
我们批量计算的另一个原因是,在优化过程中,我们只能在对多个样本中的梯度进行平均后更新内部参数(迈出一步)。这有助于我们避免因错误的样本(例如错误标记的数字)而朝错误的方向迈出了一步。
当批量输入数据时,我们引入秩 D + 1 的张量,其中D是单个输入的维数。
如前所述,我们 MNIST 数据集中单个图像的维度为[28,28,1]。当我们将 BATCH_SIZE 设置为64时,我们每次批量处理64个图像,这意味着我们的数据的实际形状是[64,28,28,1](批量始终是最外层的维度)。
注意:*回想一下在我们的第一个 conv2d 配置中的 inputShape 没有指定批量大小(64)。 Config 被写成批量大小不可知的,以便他们能够接受任意大小的批次。
编写训练循环
以下是训练循环的代码:
for (let i = 0; i < TRAIN_BATCHES; i++) {
const batch = data.nextTrainBatch(BATCH_SIZE);
let testBatch;
let validationData;
if (i % TEST_ITERATION_FREQUENCY === 0) {
testBatch = data.nextTestBatch(TEST_BATCH_SIZE);
validationData = [
testBatch.xs.reshape([TEST_BATCH_SIZE, 28, 28, 1]), testBatch.labels
];
}
const history = await model.fit(
batch.xs.reshape([BATCH_SIZE, 28, 28, 1]),
batch.labels,
{
batchSize: BATCH_SIZE,
validationData,
epochs: 1
});
const loss = history.history.loss[0];
const accuracy = history.history.acc[0];
}
让我们分析代码。 首先,我们获取一批训练样本。 回想一下上面说的,我们利用GPU并行化批量处理样本,在对大量样本进行平均后才更新参数:
const batch = data.nextTrainBatch(BATCH_SIZE);
- 每5个
step(TEST_ITERATION_FREQUENCY),我们构造一次validationData,这是一个包含一批来自MNIST测试集的图像及其相应标签这两个元素的数组,我们将使用这些数据来评估模型的准确性:
if (i % TEST_ITERATION_FREQUENCY === 0) {
testBatch = data.nextTestBatch(TEST_BATCH_SIZE);
validationData = [
testBatch.xs.reshape([TEST_BATCH_SIZE, 28, 28, 1]),
testBatch.labels
];
}
model.fit 是模型训练和参数实际更新的地方。
注意:在整个数据集上执行一次 model.fit 会导致将整个数据集上传到 GPU,这可能会使应用程序死机。 为避免向GPU上传太多数据,我们建议在 for 循环中调用 model.fit(),一次传递一批数据,如下所示:
const history = await model.fit(
batch.xs.reshape([BATCH_SIZE, 28, 28, 1]), batch.labels,
{batchSize: BATCH_SIZE, validationData: validationData, epochs: 1});
我们再来分析一下这些参数:
X.输入图像数据。请记住,我们分批量提供样本,因此我们必须告诉fit函数batch有多大。MnistData.nextTrainBatch返回形状为[BATCH_SIZE,784]的图像 —— 所有的图像数据是长度为784(28 * 28)的一维向量。但是,我们的模型预期图像数据的形状为[BATCH_SIZE,28,28,1],因此我们需要使用reshape函数。
y.我们的标签;每个图像的正确数字分类。
BATCHSIZE.每个训练batch中包含多少个图像。之前我们在这里设置的BATCH_SIZE是 64。
validationData.每隔TEST_ITERATION_FREQUENCY(这里是5)个Batch,我们构建的验证集。该数据的形状为[TEST_BATCH_SIZE,28,28,1]。之前,我们设置了1000的TEST_BATCH_SIZE。我们的评估度量(准确度)将在此数据集上计算。
epochs.批量执行的训练次数。由于我们分批把数据馈送到fit函数,所以我们希望它每次仅从这个batch上进行训练。
每次调用 fit 的时候,它会返回一个包含指标日志的对象,我们把它存储在 history。我们提取每次训练迭代的损失和准确度,以便将它们绘制在图上:
const loss = history.history.loss[0];
const accuracy = history.history.acc[0];
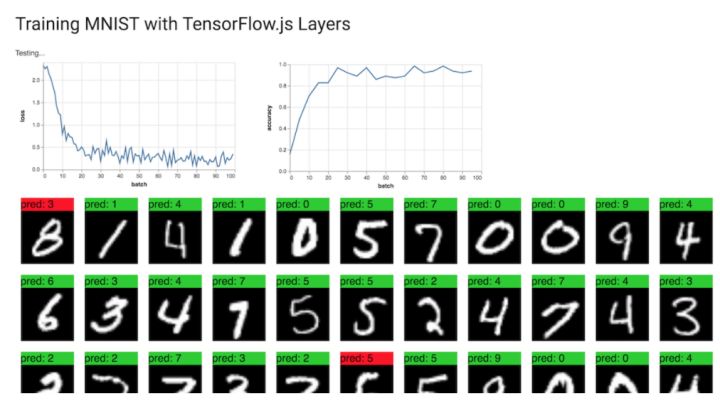
查看结果!
如果你运行完整的代码,你应该看到这样的输出: