
Linux 使用Haproxy搭建Web群集
防伪码:不必向我解释色彩,我的眼里自有一片湛蓝
第七章 使用Haproxy搭建Web集群
前言:Haproxy是目前比较流行的一种集群调度工具,同类集群调度工具很多,如LVS和Nginx。相比较而言,LVS性能最好,但是搭建相对复杂,Nginx的upstream模块支持集群功能,但是对集群节点的检查功能不强,性能没有Haproxy好,其官网是http://haproxy.1wt.eu/。本章我们将使用Haproxy搭建一套Web集群,并增加一台Haproxy做双机热备,达到高可用的效果。
一、前置知识点:
1、HTTP请求
请求方式(GET方式和POST方式)
返回状态码:
正常的状态码为2××、3××
异常的状态码为4××、5××
2、负载均衡常用调度算法:
RR(Round Robin):轮询调度
LC(Least Connections):最小连接数
SH(Source Hashing):基于来源访问调度
3、常见的web集群调度器
软件:LVS、Haproxy、Nginx
硬件:F5、梭子鱼、绿盟等
二、综合实验:使用Haproxy搭建web集群
1、实验拓扑图:
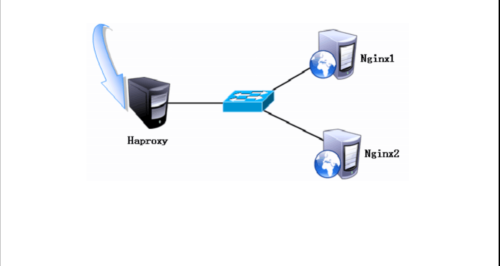
2、案例环境表:
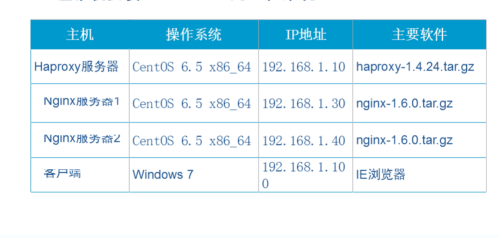
3、 实验步骤
1) 编译安装haproxy
首先安装两个支持包

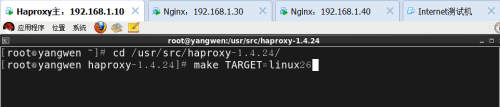

2) haproxy服务器的配置
首先建立haproxy的配置文件

拷贝配置文件的样本复制到/etc/haproxy目录下
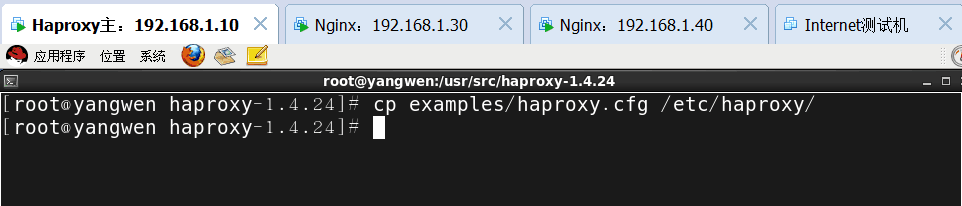
修改haproxy.cfg配置文件(分为三部分,global为全局,defaults为默认,listen为应用组件)

详解配置参数:
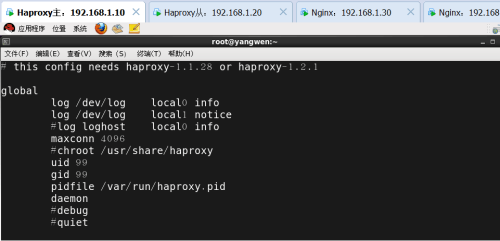
# this config needs haproxy-1.1.28 or haproxy-1.2.1
global
log /dev/log local0 info //日志记录,local0为日志设备,默认存放到系统日志
log /dev/log local1 notice //notice为日志级别,通常有24个级别
#log loghost local0 info
maxconn 4096
#chroot /usr/share/haproxy
uid 99 //用户uid
gid 99 //用户gid
pidfile /var/run/haproxy.pid //pid文件的路径以及文件名
daemon //后台运行
#debug
#quiet
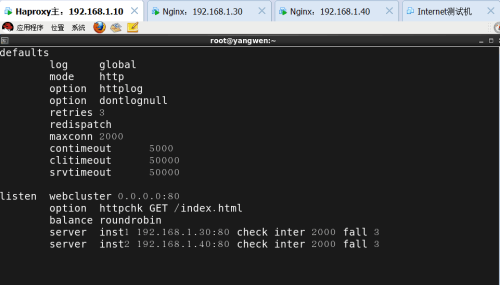
defaults
log global //定义日志为global配置中的日志定义
mode http //模式为http协议
option httplog //采用http日志格式记录日志
option dontlognull
retries 3 //检查节点服务器的失败次数,连续达到三次则认为节点不可用
maxconn 2000 //最大连接次数
contimeout 5000 //连接超时时间
clitimeout 50000 //客户端超时时间
srvtimeout 50000 //服务器超时时间
listen webcluster 0.0.0.0:80
option httpchk GET /index.html //检查服务器的index.html文件
balance roundrobin //负载均衡调度算法为轮询
server inst1 192.168.1.30:80 check inter 2000 fall 3 //定义节点地址和端口,健康检查三次
server inst2 192.168.1.40:80 check inter 2000 fall 3
3)创建自启动脚本



4) 安装nginx(以第一台nginx为例)
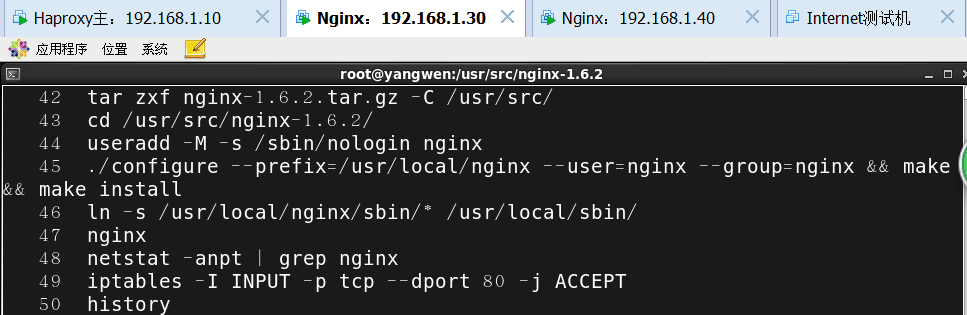
剩下的节点配置一样,为了测试时看出效果,建议将测试页的内容不要保持一致
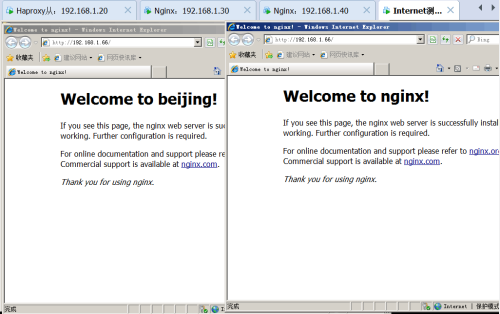
第一台如图所示:
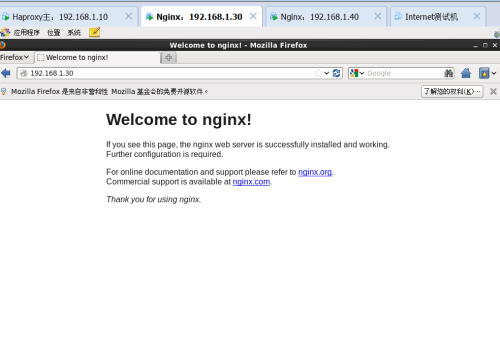
第二台如图所示:
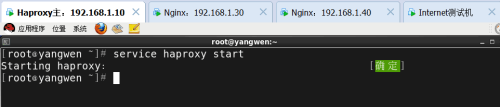
5) 开启haproxy服务(防火墙开启tcp80端口)
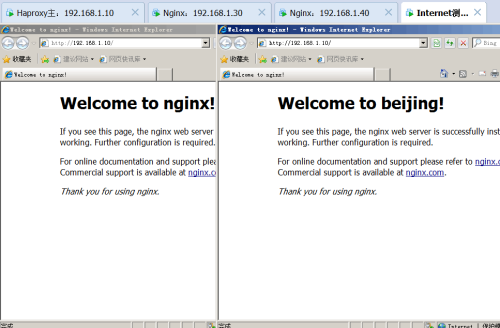
6) 测试web群集
首先测试负载均衡,在客户端上打开http://192.168.1.10
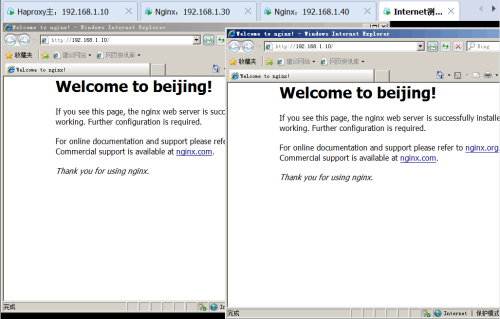
下面再测试一下高可用,我们把第一台服务器的网卡断掉,模拟服务器出现故障,如果网页依然可以访问,说明群集的高可用没有问题。
7) 配置haproxy日志
Haproxy的日志默认是保存到系统的syslog中,查看起来不方便,所以我们在生产环境中可以将日志单独存储到不同的文件中,配置如下
首先修改配置文件,主要改下面的部分(这两行的作用是将info和notice的日志分别记录到不同的文件中)
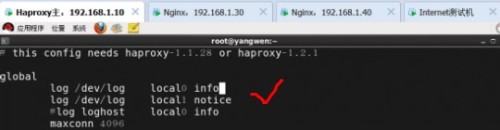
然后修改rsyslog配置,将haproxy相关的配置独立定义到haproxy.conf,并放到/etc/rsyslog.d下,rsyslog启动时会自动加载此目录下所有的配置文件。
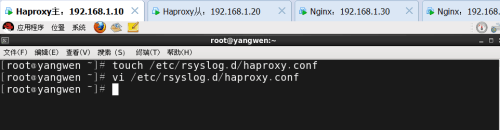
加入以下内容
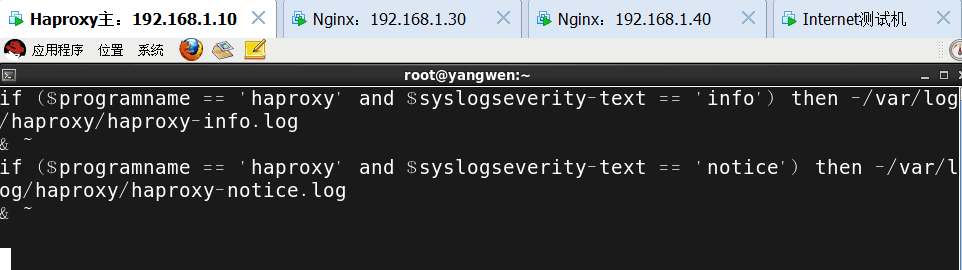
然后重新启动rsyslog服务
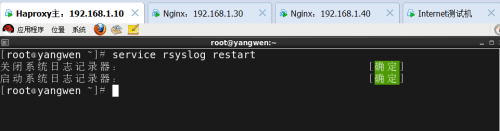
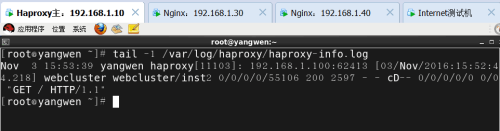
测试日志信息:
在客户机访问网站之后,可以使用tail -f /var/log/haproxy/haproxy-info.log即时查看日志
8)生产环境中需要对Haproxy进行参数优化,以满足实际生产的要求
| 参数 | 参数说明 | 优化建议 |
| maxconn | 最大连接数 | 推荐使用10240 |
| daemon | 守护进程模式 | Haproxy可以使用非进程守护模式启动,生产环境建议使用守护进程模式启动 |
| nbproc | 负载均衡的并发进程数 | 建议与服务器CPU核数相等或成为其2倍 |
| retries | 重试次数 | 发量大,设置为2或3次;服务器节点不多,可以设置为5或6次 |
| option http-server-close | 主动关闭http请求选项 | 建议在生产环境中使用此选项,避免由于timeout时间设置过长导致http连接堆积 |
| timeout http-keep-alive | 长连接超时时间 | 可以设置为10s |
| timeout http-request | http请求超时时间 | 建议设置5-10s,增加http连接释放速度 |
| timeout client | 客户端超时时间 | 如果访问量大,节点相应慢,可以将此时间设置短一些,意见设置为1min左右即可 |
9)为了实现haproxy的高可用,我们可以配置keepalived。
思路:在以上实验原有的基础上增加一台Haproxy服务器,两台调度服务器做双机热备,
配置好了之后断掉第一台Haproxy网站依然可以访问对了。
为两台Haproxy配置虚拟IP地址作为访问地址:
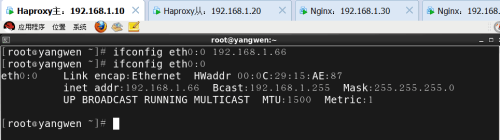
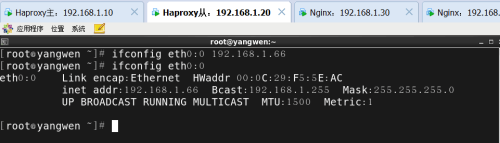
访问:
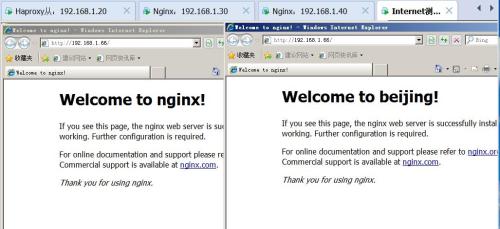
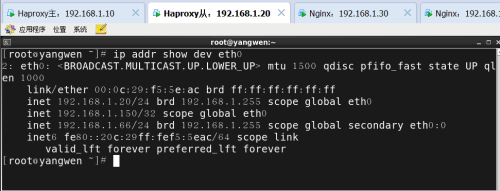
断开一台,发现仍然可以访问
使用ip addr show dev eth0命令,发现从Haproxy调度器已成为主调度器
谢谢观看,真心的希望能帮到您。
本文出自 “一盏烛光” 博客,谢绝转载!