
好架构是进化来的,不是设计来的(58架构演进)
核心内容:58同城流量从小到大过程中,架构是如何演进的?遇到了哪些问题?以及如何解决这些问题?
核心观点:好的架构不是设计出来的,而是进化而来的。
如何演进:站点流量在不同阶段,会遇到不同的问题,找到对应阶段站点架构所面临的主要问题,在不断解决这些问题的过程中,整个系统的架构就不断的演进了。
如何演进,简言之:找到主要矛盾,并解决主要矛盾。
第一章:建站之初
建站之初,站点流量非常小,可能低于十万级别。这意味着,平均每秒钟也就几次访问。请求量比较低,数据量比较小,代码量也比较小,几个工程师,很短的时间搭起这样的系统,甚至没有考虑“架构”的问题。
和许多创业公司初期一样,最初58同城的站点架构特点是“ALL-IN-ONE”:

这是一个单机系统,所有的站点、数据库、文件都部署在一台服务器上。工程师每天的核心工作是CURD,浏览器端传过来一些数据,解析GET/POST/COOKIE中传过来的数据,拼装成一些CURD的sql语句访问数据库,数据库返回数据,拼装成页面,返回浏览器。相信很多创业团队的工程师,初期做的也是类似的工作。
58同城最初选择的是微软技术体系这条路:Windows、iis、SQL-Sever、C#
如果重新再来,我们可能会选择LAMP体系。
为什么选择LAMP?
LAMP无须编译,发布快速,功能强大,社区活跃,从前端+后端+数据库访问+业务逻辑处理全部可以搞定,并且开源免费,公司做大了也不会有人上门收钱(不少公司吃过亏)。现在大家如果再创业,强烈建议使用LAMP。
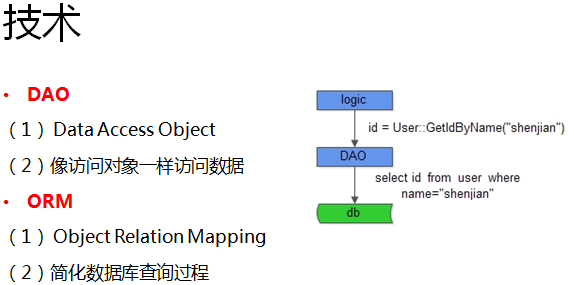
初创阶段,工程师面临的主要问题:写CURD的sql语句很容易出错。
我们在这个阶段引进DAO和ORM,让工程师们不再直接面对CURD的sql语句,而是面对他们比较擅长的面向对象开发,极大的提高了编码效率,降低了出错率。
第二章:流量增加,数据库成为瓶颈
随着流量越来越大,老板不只要求“有一个可以看见的站点”,他希望网站能够正常访问,当然速度快点就更好了。
而此时系统面临问题是:流量的高峰期容易宕机,大量的请求会压到数据库上,数据库成为新的瓶颈,人多并行访问时站点非常卡。这时,我们的机器数量也从一台变成了多台,我们的系统成了所谓的(伪)“分布式架构”:
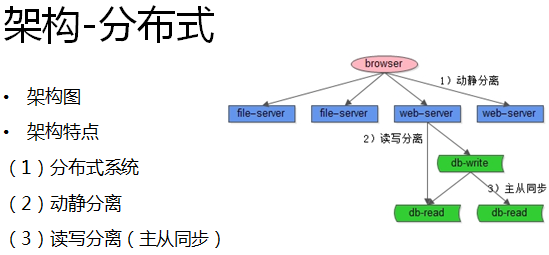
我们使用了一些常见优化手段:
(1)动静分离,动态的页面通过Web-Server访问,静态的文件例如图片就放到单独的文件服务器上;
(2)读写分离,将落到数据库上的读写请求分派到不同的数据库服务器上;
互联网绝大部分的业务场景,都是读多写少。对58同城来说,绝大部分用户的需求是访问信息,搜索信息,只有少数的用户发贴。此时读取性能容易成为瓶颈,那么如何扩展整个站点架构的读性能呢?常用的方法是主从同步,增加从库。我们原来只有一个读数据库,现在有多个读数据库,就提高了读性能。
在这个阶段,系统的主要矛盾为“站点耦合+读写延时”,58同城是如何解决这两个问题的呢?
第一个问题是站点耦合。对58同城而言,典型业务场景是:类别聚合的主页,发布信息的发布页,信息聚合的列表页,帖子内容的详细页,原来这些系统都耦合在一个站点中,出现问题的时候,整个系统都会受到影响。
第二个问题是读写延时。数据库做了主从同步和读写分离之后,读写库之间数据的同步有一个延时,数据库数据量越大,从库越多时,延时越明显。对应到业务,有用户发帖子,马上去搜索可能搜索不到(着急的用户会再次发布相同的帖子)。
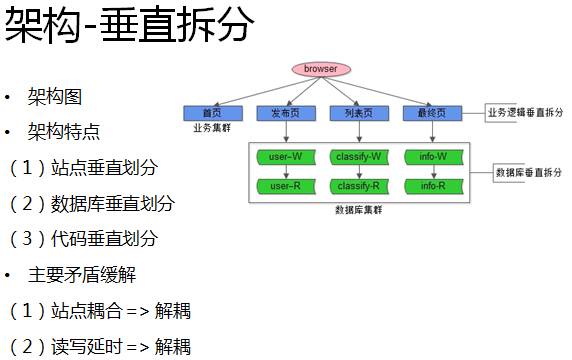
要解决耦合的问题,最先想到的是针对核心业务做切分,工程师根据业务切分对系统也进行切分:我们将业务垂直拆分成了首页、发布页、列表页和详情页。
另外,我们在数据库层面也进行了垂直拆分,将单库数据量降下来,让读写延时得到缓解。
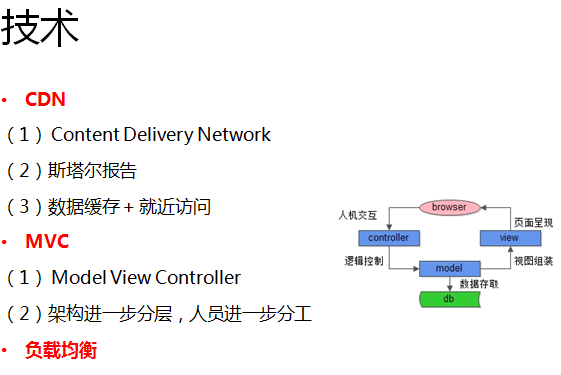
同时,还使用了这些技术来优化系统和提高研发效率:
(1)对动态资源和静态资源进行拆分。对静态资源我们使用了CDN服务,用户就近访问,静态资源的访问速度得到很明显的提升;
(2)除此之外,我们还使用了MVC模式,擅长前端的工程师去做展示层,擅长业务逻辑的工程师就做控制层,擅长数据的工程师就做数据层,专人专用,研发效率和质量又进一步提高。
第三章:全面转型开源技术体系
流量越来越大,当流量达到百万甚至千万时,站点面临一个很大的问题就是性能和成本的折衷。上文提到58同城最初的技术选型是Windows,我们在这个阶段做了一次脱胎换骨的技术转型,全面转向开源技术:
(1)操作系统转型Linux
(2)数据库转型Mysql
(3)web服务器转型Tomcat
(4)开发语言转向了Java
其实,很多互联网公司在流量从小到大的过程中都经历过类似的转型,例如京东和淘宝。
随着用户量的增加,对站点可用性要求也越来越高,机器数也从最开始的几台上升到几百台。那么如何提供保证整个系统的可用性呢?首先,我们在业务层做了进一步的垂直拆分,同时引入了Cache,如下图所示:
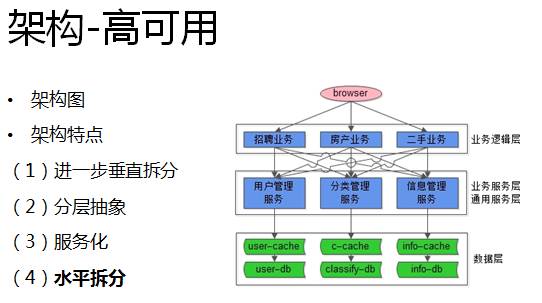
在架构上,我们抽象了一个相对独立的服务层,所有数据的访问都通过这个服务层统一来管理,上游业务线就像调用本地函数一样,通过RPC的框架来调用这个服务获取数据,服务层对上游屏蔽底层数据库与缓存的复杂性。
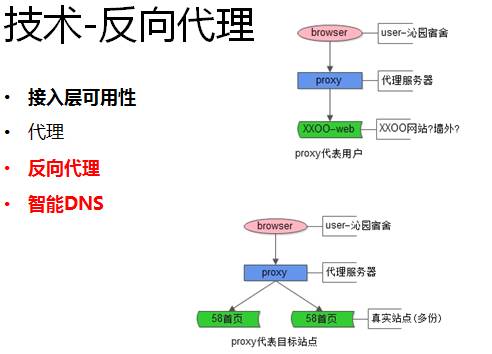
除此之外,为了保证站点的高可用,我们使用了反向代理。
什么是代理?代理就是代表用户访问xxoo站点。
什么是反向代理?反向代理代表的是58网站,用户不用关注访问是58同城的哪台服务器,由反向代理来代表58同城。58同城通过反向代理,DNS轮询, LVS等技术,来保证接入层的高可用性。
另外,为了保证服务层和数据层的高可用,我们采用了冗余的方法,单点服务不可用,我们就冗余服务,单点数据不可用,我们就冗余数据。
这个阶段58同城进入了一个业务高速爆发期,短期内衍生出非常多的业务站点和服务。新增站点、新增服务每次都会做一些重复的事情,例如线程模型,消息队列,参数解析等等,于是,58同城就研发了自己的站点框架和服务框架,现在这两个框架也都已经开源:
(1)站点框架Argo:https://github.com/58code/Argo
(2)服务框架Gaea:https://github.com/58code/Gaea
这个阶段,为了进一步解耦系统,我们引入了配置中心、柔性服务和消息总线。
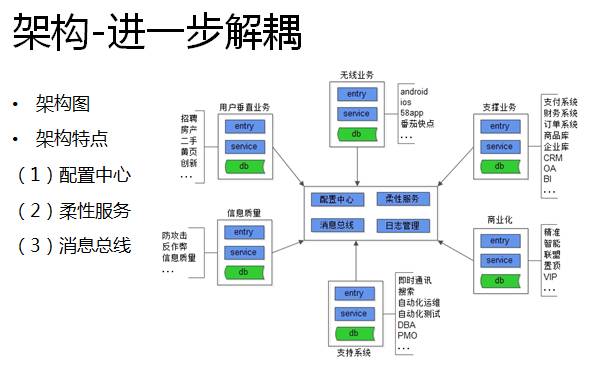
引入配置中心,业务要访问任何一个服务,不需要在本地的配置文件中配置服务的ip list,而只需要访问配置中心。这种方式的扩展性非常好,如果有机器要下线,配置中心会反向通知上游订阅方,而不需要更新本地配置文件。
柔性服务是指当流量增加的时候,自动的扩展服务和站点。
消息总线也是一种解耦上下游“调用”关系常见的技术手段。
机器越来越多,此时很多系统层面的问题,靠“人肉”已经很难搞定,于是自动化变得越来越重要:自动化回归、自动化测试、自动化运维、自动化监控等等等等。
最后补充一点,这个阶段我们引入了不少智能化产品,比如智能推荐,主动推荐一些相关的数据,以增加58同城的PV;智能广告,通过一些智能的策略,让用户对广告的点击更多,增加同城的收入;智能搜索,在搜索的过程中加入一些智能的策略,提高用户的点击率,以增加58同城的PV。这些智能化产品的背后都由技术驱动。
第四章:进一步的挑战
现在,58同城的流量已经达到10亿的量级,架构上我们规划做一些什么样的事情呢,几个方向:
(1)业务服务化
(2)多架构模式
(3)平台化
(4)...

第五章:小结
最后做一个简单的总结,网站在不同的阶段遇到的问题不一样,而解决这些问题使用的技术也不一样:
(1)流量小的时候,我们要提高开发效率,可以在早期要引入ORM,DAO;
(2)流量变大,可以使用动静分离、读写分离、主从同步、垂直拆分、CDN、MVC等方式不断提升网站的性能和研发效率;
(3)面对更大的流量时,通过垂直拆分、服务化、反向代理、开发框架(站点/服务)等等手段,可以不断提升高可用(研发效率);
(4)在面对上亿级的流量时,通过配置中心、柔性服务、消息总线、自动化(回归,测试,运维,监控)来迎接新的挑战;