
“id串行化”到底是怎么实现的?
一、需求缘起
在上一篇文章《消息“时序”与“一致性”为何这么难?》中,介绍了一种为了保证“所有群友展示的群消息时序都是一致的”所使用的“id串行化”的方法:让同一个群gid的所有消息落在同一台服务器上处理。
有朋友就要问了,如何保证一个群gid的消息落到同一个服务器处理呢,“id串行化”具体是怎么实现的呢,这个问题在年初的一篇文章中描述过,这里再给有疑问的同学解答一下。
二、互联网高可用常见分层架构
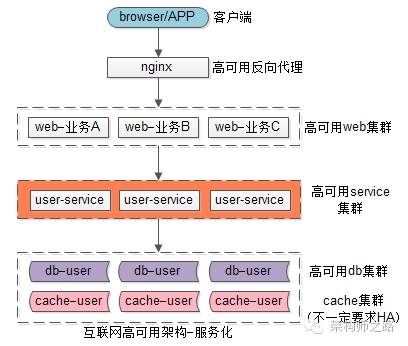
客户端,反向代理层,接入层(此图是http短链接接入,群聊消息的话是tcp长连接接入),服务层(处理群消息业务逻辑),存储层(缓存cache存储,固化db存储),这是互联网常见的高可用分层架构。
服务层的引入至关重要,群消息的投递不能保证落在同一个接入层,但可以保证落在同一个服务层。
三、服务层上下游细节
服务化的service一般由RPC-server框架实现,上游应用是多线程程序(站点层http接入应用,或者长连接tcp接入应用)一般通过RPC-client访问service,而RPC-client内部又通过连接池connection-pool访问下游的service(为了保证高可用,是一个service集群)。
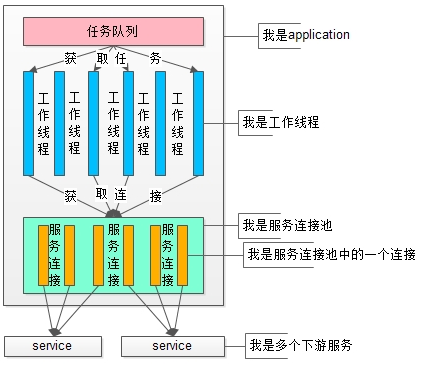
如上图:
(1)上游是业务应用(站点层http接入应用,或者长连接tcp接入应用)
(2)下游是service集群
(3)业务应用,它又分为了这么几个部分
(3.1)最上层是任务队列【或许web-server例如tomcat帮你干了这个事情了】
(3.2)中间是工作线程【或许web-server的工作线程或者cgi工作线程帮你干了线程分派这个事情了】,每个工作线程完成实际的业务任务,典型的工作任务是通过服务连接池进行RPC调用
(3.3)最下层是服务连接池,所有的RPC调用都是通过服务连接池往下游服务去发包执行的
工作线程的典型工作流伪代码是这样的:
void work_thread_routine(){
Task t = TaskQueue.pop(); // 获取任务
// 任务逻辑处理,组成一个网络包packet,调用下游RPC接口
ServiceConnection c = CPool.GetServiceConnection();
// 从Service连接池获取一个Service连接
c.Send(packet); // 通过Service连接发送报文执行RPC请求
CPool.PutServiceConnection(c); // 将Service连接放回Service连接池
}
如何保证同一个群gid的消息落在同一个service上呢?
只要对服务连接池进行少量改动:
获取Service连接的CPool.GetServiceConnection()【返回任何一个可用Service连接】改为
CPool.GetServiceConnection(long id)【返回id取模相关联的Service连接】
只要传入群gid,就能够保证同一个群的请求获取到同一个连接,从而使请求落到同一个服务Service上。
需要注意的是,连接池不关心传入的long id是什么业务含义:
(1)传入群gid,同gid的请求落在同一个service上
(2)传入用户uid,同uid的请求落在同一个service上
(3)传入任何业务xid,同业务xid的请求落在同一个service上
四、其他问题
提问:id串行化访问service,同一个id访问同一个service,当service挂掉时,是否会影响service的可用性?
答:不会,当有下游service挂掉的时候,service连接池能够检测到连接的可用性,取模时要把不可用的服务连接排除掉。
提问:取模访问service,是否会影响各连接上请求的负载均衡?
答:不会,只要数据访问id是均衡的,从全局来看,由id取模获取各连接的概率也是均等的,即负载是均衡的。
五、总结
升级RPC-client内部的连接池,在service连接选取上做微小改动,就能够实现“id串行化”,实现不同类型的业务gid/uid等的串行化、序列号需求(这下查找日志就方便了,一个群gid/用户uid的日志只需去一台机器grep啦)。