
Assembly Big和Little Endian表示法
在前面的章节本教程介绍了多字节数据的big和little endian表示法的概念。这一节将详细介绍这一主题。读者可能会回忆起endian表示法指的是一个多字节数据的单个字节元素储存在内存中的顺序。Big endian是最直接的方法。它首先储存的是最高有效字节,然后是第二个有效字节,以些类推。换句话说就是,大的位被首先储存。Little endian以一个相反的顺序来储存字节(最小的有效字节最先被储存)。x86家族的处理器使用的就是little endian表示法。
制AX的值到内存中,首先复制AL的值,接着是AH。CPU做这件事一点也没有比先储存AH难。

bswap edx ; 交换edx中的字节
这条指令不可以使用在16位的寄存器上。但是XCHG 指令可以用来交换可以分解成8位寄存器的16寄存器中的字节。例如:
xchg ah,al ; 交换ax中的字节
看一个例子:考虑双字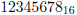 的表示。如果是big endian表示法,这些字节将像这样储存:12 34 56 78。如果是little endian表示法,这些字节就像这样储存:78 56 34 12。
的表示。如果是big endian表示法,这些字节将像这样储存:12 34 56 78。如果是little endian表示法,这些字节就像这样储存:78 56 34 12。
现在读者可能会这样问自己:一个理智的芯片设计者怎么会使用little endian表示法?在Intel公司里的工程师是不是虐待狂?因为他们使广大的程序员承受了这种混乱的表示法。像这样,CPU看起来会因为在内存中向后储存字节而做额外的工作(而且从内存中读出时又要颠倒它们)。答案是CPU使用little endian格式读写内存是不需要做额外的工作的。你必须认识到CPU是由许多电子电路组成,简单地工作在位值上。位(和字节)在CPU中不需要有任何的顺序的。
制AX的值到内存中,首先复制AL的值,接着是AH。CPU做这件事一点也没有比先储存AH难。
同样的讨论还可以用到一个字节的单个比特位上。它们在CPU电路(或就此而言,内存)里并不真的有一定顺序。但是,因为在CPU或内存中单个的比特位并没有编址,所以没有办法知道(或关心)CPU在内部对它们是如
何排序的。在图3.4中的C代码展示了如何确定CPU的Endian格式。p指针把word变量当作两个元素的字符数组来看待。因此,word在内存里的第一个字节赋值给了p[0],而这取决于CPU的Endian格式。

什么时候需要在乎Little和Big Endian
对于典型的编程,CPU的Endian格式并不是很重要。它很重要的大多数时刻是在不同的计算机系统间传输二进制数据时。此时使用的要么是某种类型的物理数据媒介(例如一块硬盘)要么是网络。因为ASCII数据是单个字节的,Endian格式对它来说是没有问题的。
所有的内部的TCP/IP消息头都以big endian的格式来储存整形。(称为网络字节续). TCP/IP 库提供了可移植处理Endian格式问题的方法的C函数。例如:htonl () 函数把一个双字(或长整形)从主机格式转换成了网络格式。ntohl ()函数执行一个相反的交换。对于一个big endian系统,这两个函数仅仅是无修改地返回它们的输入。这就允许你写出的网络程序可以在任何的Endian格式系统上成功编译和运行。
图3.5展示了一个转换双字Endian格式的C函数。486处理器提供了一个名为BSWAP的新的指令来交换任意32位寄存器中的字节。例如:
bswap edx ; 交换edx中的字节
这条指令不可以使用在16位的寄存器上。但是XCHG 指令可以用来交换可以分解成8位寄存器的16寄存器中的字节。例如:
xchg ah,al ; 交换ax中的字节