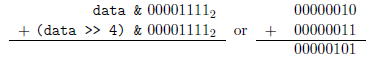Assembly 计算位数的3种方法
前面介绍了一个简单的技术来计算一个双字中“on”的位数有多少。这一节来看看其它不是很直接来做这件事的方法,就当作使用在这一章中讨论的位操作的练习。
方法一
第一个方法很简单,但不是很明显。图3.6展示了代码。
第6行表示data中的一个比特位被关闭了。这个是如何起作用的?考虑data二进制表示法最普遍的格式和在这种表示法中最右边的1。根据上面的定义,在这个1后面的所有位都为0。现在,data -1的二进制表示是什么样的?最右边的1的所有左边的位与data是一样的,但是在最右边的1这一点的位将会是data原始位的反码。例如:
data = xxxxx10000
data - 1 = xxxxx01111
x表示对于在这个位上这两个数的值是相等的。当data和data - 1进行AND运算后,在data中的最右边的1这一位的结果就会为0,而其它比特位没有被改变。
方法二
查找表同样可以用来计算出任意双字的位数。这个直接方法首先要算出每个双字的位数,还要把位数储存到一个数组中。但是,有两个与这个方法相关的问题。双字的值大约有40亿。这就意味着数组将会非常大而且会浪费很多时间在初始化这个数组上。(事实上,除非你确实打算使用一个超过40亿的数组,否则花在初始化这个数组的时间将远远大于用第一种方法计算位数的时间。
一个更现实的方法是提前算出所有可能的字节的位数,并把它们储存到一个数组中。然后,双字就可以分成四个字节来求。这四个字节的位数通过查找数组得到,然后将它们相加就得到原始双字的位数。图3.7展示了如何用代码实现这个方法。

initialize_count bits函数必须在第一次调用count bits函数之前被调用。这个函数初始化了byte_bit_count全局数组。count_bits函数并不是以一个双字来看对待data变量,而是以把它看成四个字节的数组。byte指针作为一个指向这个四个字节数组的指针。因此,byte[0]是data中的一个字节(是最低有效字节还是最高有效字节取决于硬件是使用little还是big endian。)。当然,你可以像这样使用一条指令:
(data >> 24) & 0x000000FF
来得到最高有效字节值,可以用同样的方法得到其它字节;但是这些指令会比引用一个数组要慢。
最后一点,使用for循环来计算在22和23行的总数是简单的。但是,for循环就会包含初始化一个循环变量,在每一次重复后比较这个变量和增加这个变量的时间开支。通过清楚的四个值来计算总数会快一些。事实上,一个好的编译器会将for循环形式转换成清楚的求和。这个简化和消除循环重复的处理是一个称为循环展开的编译器优化技术。
方法三
这个做了些什么?十六进制常量0x55的二进制表示为01010101。在这个加法的第一个操作数中,data与这个常量进行了AND运算,奇数的位就被拿出来了。第二操作数((data >> 1) & 0x55),首先移动所有的偶数位到奇
数位上,然后使用相同的掩码得到这些相同的位。现在,第一个操作数含有data的奇数位而第二个操作数含有偶数位。把这两个操作数相加就相当于把data的奇数位和偶数位相加。例如,如果data等于
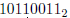 ,那么:
,那么: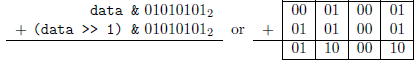

data = (data & 0x0F) + ((data >> 4) & 0x0F);
使用上面的例子(data等于
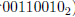 ):
):