
Assembly 指示符
指示符是由汇编程序产生的而不是由CPU产生。它们通常用来要么指示汇编程序做什么要么提示汇编程序什么。它们并不翻译成机器代码。指示符普遍的应用有:
1、定义常量
2、定义用来储存数据的内存
3、将内存组合成段
4、有条件地包含源代码
5、包含其它文件
NASM代码像C一样要通过一个预处理程序。它拥有许多和C一样的预处理程序。但是,NASM 的预处理的指示符以%开头而不是像C一样以#开头。
equ 指示符
equ指示符可以用来定义一个符号。符号被命名为可以在汇编程序里使用的常量。格式是:
symbol equ value
符号的值以后不可以再定义。
%define 指示符
这个指示符和C中的#define非常相似。它通常用来定义一个宏常量,像在C里面一样。%define SIZE 100
mov eax, SIZE
mov eax, SIZE
上面的代码定义了一个称为SIZE的宏通过使用一个MOV指令。宏在两个方面比符号要灵活。宏可以被再次定义而且可以定义比简单的常量数值更大的值。
数据指示符
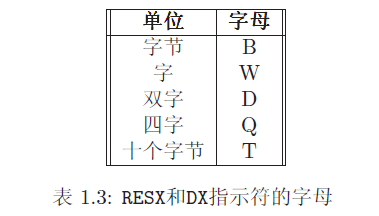
数据指示符使用在数据段中用来定义内存空间。保留内存有两种方法。第一种方法仅仅为数据定义空间;第二种方法在定义数据空间的同时给与一个初始值。第一种方法使用RESX指示符中的一个。X可由字母替代,字母由需要储存的对象的大小来决定。表1.3给出了可能的值。
第二种方法(同时定义一个初始值)使用DX指示符中的一个。X可以由字母替代,字母的值与RESX里的值一样。使用变量来标记内存位置是非常普遍的。变量使得在代码中指向内存位置变得容易。下面是几个例子:

双引号和单引号被同等对待。连续定义的数据储存在连续的内存中。也就是说,字L2就储存在L1的后面。内存的顺序可以同样被定义。

指示符DD可以用来定义整形和单精度的浮点数常量6。但是,DQ指示符仅仅可以用来定义双精度的数常量。
对于大的序列,NASM 的TIMES 指示符常常非常有用。这个指示符每次都重复它的操作对象一个指定的次数。例如:

记住变量可以用来表示代码中的数据。变量的使用方法有两种。如果一个平常的变量被使用了,它被解释为数据的地址(或偏移)。如果变量被放置在方括号([])中,它就被解释为在这个地址中的数据。换句话说,你必须把变量当作一个指向数据的指针而方括号引用这个指针就像*号在C中一样。(MASM/TASM使用的是另外一个惯例。)在32位模式下,地址是32位。这儿有几个例子:

例子的第7行展示了NASM 一个重要性能。汇编程序并不保持跟踪变量的数据类型。它由程序员来决定来保证他(或她)正确使用了一个变量。随后它一般将数据的地址储存到寄存器中,然后像在C中一样把寄存器当一个指针变量来使用。同样,没有检查使得指针能正确使用。以这种方式,汇编程序跟C相比有更易出错的倾向。
考虑下面的指令:
mov [L6], 1 ; 储存1到L6中
这条语句产生一个operation size not specified(操作大小没有指定)的错误。为什么?因为汇编程序不知道是把1当作一个字节,还是字,或是双字来储存。为了修正这个,加一个大小指定:
mov dword [L6], 1 ; 储存1到L6中
这个告诉汇编程序把1储存在从L6开始的双字中。另一些大小指定为:BYTE(字节),WORD(字),QWORD(四字)和TWORD(十字节)。