
Assembly 多维数组
多维数组和已经讨论的普遍的一维数组相比,差异并不是很大。事实上,在内存中,它们的描述方法和普遍的一维数组是一样的。
二维数组
不要感到意外,最简单的多维数组就是二维数组。一个二维数组通常以网格的形式来表示元素。每个元素通过两个下标来确定。按照惯例,第一个下标用来确定元素的行值,而第二下标用来确定元素的列值。
考虑一个三行二列的数组,像这样定义:
int a [3][2];
C编译器将为这个数组保留6(= 2 X 3)个整形数的空间,而且像下面一样来映射元素:

这张表试图展示的是a[0][0]引用的元素储存在6个元素的一维数组的开始。元素a[0][1]储存在下一个位置(下标1),以此类推。在内存中,二维数组的各个行都是连续储存的。一行的最后一个元素后面紧跟着下一行的第一个元素。这就是所谓的数组依行表示法,这也是C/C++编译器表示数组的表示方法。
在依行表示法中,编译器如何确定a[i][j]出现在哪?一个简单的公式将通过i和j来计算下标。在这个例子中,公式为2i + j。并不难看出如何得到这个公式。每一行有两个元素大小;所以行i的第一个元素的位置为2i。然后该行的j列的位置可以通过j和2i相加得到。这个分析同样展示了如何产生N列数组的公式:N X i + j。注意,这个公式并不依赖于行的总数。作为一个例子,我们来看看gcc如何编译下面的代码(使用上面定义的数组a):
x = a[i ][ j ];
![x = a[i ][ j ]](https://atts.w3cschool.cn/attachments/day_161029/201610291441484036.png)
图5.6展示了这条语句翻译成的汇编语言。因此编译器实质上将代码转换成:
x = *(&a[0][0] + 2*i + j );
而且事实上,程序员可以以这种方法来书写,也可以得到同样的结果。
选择依行的数组表示法并没有什么魔力。依列的表示法同样可以工作:

在依列表示法中,各列被连续储存。元素[i][j]储存在i + 3j位置中。其它语言(例如:FORTRAN)使用依列表示法。当与多种语言进行代码接口时,这是非常重要的。
大于二维
对于大于二维的数组,应用了同样原理的想法。考虑一个三维数组:
int b [4][3][2];
在内存中,这个数组将被当作四个大小为[3][2]的二维数组被连续储存。
下面的表展示了它如何运作:

计算b[i][j][k]的位置的公式是6i + 2j + k。其中6由[3][2]数组的大小决定。一般来说,对于维数为a[L][M][N]的数组,元素a[i][j][k]的位置将是M £ N £ i + N £ j + k。再次需要注意的是,第一个维的元素个数(L)并没有出现在公式中。
对于更高维的数组,可以通过推广来做同样的处理。对于一个从D1到Dn的n数组,下标为i1到in的元素的位置可以由下面这个公式得到:

或者对于超级的数学技客,它可以用更简洁地书写为:
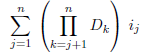
第一维D1,并没有出现在公式中。
对于依列表示法,普遍的公式将是:
对于依列表示法,普遍的公式将是:
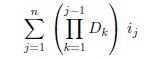
在这种情况下,是最后一维Dn,不出现在公式中。
在C语言中,传递多维数组参数
多维数组的依列表示法在C编程有一个直接的效果。对于一维的数组,当任何具体的元素被放置到内存中时,数组的大小并不需要计算出来。但这对于多维数组是不正确的。为了访问这些数组的元素,除了第一维的元素个数,编译器必须知道其它所有维数的元素个数。当一个函数的原型带有一个多维数组参数时,这就变得很明显了。下面的代码将不会被编译:
void f ( int a[ ][ ] ); /* 没有维数信息 */
但是,下面的代码就会被编译:
void f ( int a[ ][2] );
任何有两列的二维数组可以传递给这个函数。第一维的元素个数是不需要的。
不要被这类函数的原型搞混了:
void f ( int * a[ ] );
它定义了一个一维的整形指针数组。(它可以附带用来创建一个像二维数组一样运作的数组。)
对于更高维的数组,除了第一维的元素个数,数组参数的其它维数的必须指定。例如,一个四维的数组参数可以像这样被传递:
void f ( int a[ ][4][3][2] );