
Solr练习1:索引Techproducts示例数据
本练习将介绍如何将 Solr 作为双节点群集 (同一计算机上的两个节点) 启动,并在启动过程中创建一个集合。然后,您将索引一些 Solr 附带的一些示例数据并进行一些基本搜索。
在 SolrCloud 模式下启动 Solr
要启动 Solr,请在 Unix 或 MacOS 上运行:bin/solr start -e cloud;在 Windows 上运行:bin\solr.cmd start -e cloud。
这将启动一个交互式会话,在您的计算机上启动两个 Solr 服务器。这个命令有一个选项可以在不提示输入(-noprompt)的情况下运行,但是我们要修改两个默认值,所以我们现在不会使用这个选项。
solr-7.0.0:$ ./bin/solr start -e cloud
Welcome to the SolrCloud example!
This interactive session will help you launch a SolrCloud cluster on your local workstation.
To begin, how many Solr nodes would you like to run in your local cluster? (specify 1-4 nodes) [2]:其中第一个提示问我们要运行的节点数。注意最后一行末尾的 [2];这是默认的节点数量。两个是我们想要的这个例子,所以你可以简单地按下 enter。
Ok, let's start up 2 Solr nodes for your example SolrCloud cluster.
Please enter the port for node1 [8983]:这将是第一个节点运行的端口。除非您知道机器上的端口8983上还有其他东西在运行,否则请通过按 enter 来接受此默认选项。如果有东西已经在使用该端口,则会要求您选择另一个端口。
Please enter the port for node2 [7574]:这是第二个节点将运行的端口。同样,除非您知道您的计算机上的端口7574上还有其他东西在运行,否则请通过按 enter 来接受此默认选项。如果有东西已经在使用该端口,则会要求您选择另一个端口。
Solr 现在将自行初始化,并开始在这两个节点上运行。该脚本将打印它用来供您参考的命令。
Starting up 2 Solr nodes for your example SolrCloud cluster.
Creating Solr home directory /solr-7.0.0/example/cloud/node1/solr
Cloning /solr-7.0.0/example/cloud/node1 into
/solr-7.0.0/example/cloud/node2
Starting up Solr on port 8983 using command:
"bin/solr" start -cloud -p 8983 -s "example/cloud/node1/solr"
Waiting up to 180 seconds to see Solr running on port 8983 []
Started Solr server on port 8983 (pid=34942). Happy searching!
Starting up Solr on port 7574 using command:
"bin/solr" start -cloud -p 7574 -s "example/cloud/node2/solr" -z localhost:9983
Waiting up to 180 seconds to see Solr running on port 7574 []
Started Solr server on port 7574 (pid=35036). Happy searching!
INFO - 2017-07-27 12:28:02.835; org.apache.solr.client.solrj.impl.ZkClientClusterStateProvider; Cluster at localhost:9983 ready请注意,Solr 的两个实例已经在两个节点上启动。因为我们从 SolrCloud 模式开始,并且没有定义任何有关外部 ZooKeeper 集群的细节,所以 Solr 启动它自己的ZooKeeper 并将两个节点连接到它。
启动完成后,系统会提示您创建一个用于索引数据的集合。
Now let's create a new collection for indexing documents in your 2-node cluster.
Please provide a name for your new collection: [gettingstarted]这里的第一个地方,我们将偏离默认选项。本教程将要求您对 Solr 中包含的一些示例数据进行索引,称为 “techproducts” 数据。让我们将我们的收藏命名为“techproducts”,这样就很容易区分我们稍后创建的其他收藏。在 "提示" 和 "命中" 中输入 techproducts 并点击 enter。
How many shards would you like to split techproducts into? [2]这是询问您想要将索引拆分到两个节点中的碎片数。选择“2”(默认值)意味着我们将在两个节点上相对均匀地拆分索引,这是一个很好的开始。通过点击 enter 接受默认值。
How many replicas per shard would you like to create? [2]副本是用于故障转移的索引的副本(另请参阅 Solr 词汇表定义)。同样,默认的“2”也可以从这里开始,所以通过点击 enter 来接受默认值。
Please choose a configuration for the techproducts collection, available options are:
_default or sample_techproducts_configs [_default]我们已经达到了另一个我们将偏离默认选项的点。Solr 有两套可用的配置文件(称为 configSet)。
一个集合必须有一个 configSet,它至少包含 Solr 的两个主要配置文件:模式文件(命名为 managed-schemaor 或 schema.xml)和 solrconfig.xml。这里的问题是你想从哪个 configSet 开始。_default 是一个简单的选择,但请注意,有一个名称中包含“techproducts”,就像我们命名我们的收藏一样。这个 configSet 是专门为支持我们想要使用的示例数据而设计的,所以在提示符下输入 sample_techproducts_configs 并点击 enter。
此时,Solr 将创建集合,并再次将其发出的命令输出到屏幕。
Uploading /solr-7.0.0/server/solr/configsets/_default/conf for config techproducts to ZooKeeper at localhost:9983
Connecting to ZooKeeper at localhost:9983 ...
INFO - 2017-07-27 12:48:59.289; org.apache.solr.client.solrj.impl.ZkClientClusterStateProvider; Cluster at localhost:9983 ready
Uploading /solr-7.0.0/server/solr/configsets/sample_techproducts_configs/conf for config techproducts to ZooKeeper at localhost:9983
Creating new collection 'techproducts' using command:
http://localhost:8983/solr/admin/collections?action=CREATE&name=techproducts&numShards=2&replicationFactor=2&maxShardsPerNode=2&collection.configName=techproducts
{
"responseHeader":{
"status":0,
"QTime":5460},
"success":{
"192.168.0.110:7574_solr":{
"responseHeader":{
"status":0,
"QTime":4056},
"core":"techproducts_shard1_replica_n1"},
"192.168.0.110:8983_solr":{
"responseHeader":{
"status":0,
"QTime":4056},
"core":"techproducts_shard2_replica_n2"}}}
Enabling auto soft-commits with maxTime 3 secs using the Config API
POSTing request to Config API: http://localhost:8983/solr/techproducts/config
{"set-property":{"updateHandler.autoSoftCommit.maxTime":"3000"}}
Successfully set-property updateHandler.autoSoftCommit.maxTime to 3000
SolrCloud example running, please visit: http://localhost:8983/solr完成上述过程后,Solr 就准备好了数据!
您可以通过在 Web 浏览器中启动 Solr Admin UI (http:// localhost:8983 / solr /)来看到 Solr 正在运行。这是管理 Solr 的主要起点。
Solr 现在将运行两个“节点”,一个在端口7574上,一个在端口8983上。它将自动创建一个集合 techproducts,一个两个分片集合,每个集合有两个副本。
管理用户界面中的 Cloud 选项卡很好地显示了收集:

索引 Techproducts 数据
您的 Solr 服务器已启动并正在运行,但尚未包含任何数据,因此我们无法进行任何查询。
Solr 包含 bin/post 工具以便于索引各种类型的文档。我们将在下面的索引示例中使用这个工具。
您将需要一个 shell 命令来运行以下的一些示例,这些示例源于 Solr 安装目录;从你推出的 Solr 的 shell 工作得很好。
Tip:目前该bin/post工具没有可比较的 Windows 脚本,但所调用的底层 Java 程序是可用的。我们将在下面显示 Windows 示例,但是您也可以看到 Post Tool 文档的 Windows 部分以获取更多详细信息我们将索引的数据在 example/exampledocs 目录中。这些文档混合使用了文档格式(JSON,CSV 等),幸运的是,我们可以同时对它们进行索引:
对于 Linux/Mac 系统:
solr-7.0.0:$ bin/post -c techproducts example/exampledocs/对于 Windows 系统:
C:\solr-7.0.0> java -jar -Dc=techproducts -Dauto example\exampledocs\post.jar example\exampledocs\您应该看到类似于以下内容的输出:
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/techproducts/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file books.csv (text/csv) to [base]
POSTing file books.json (application/json) to [base]/json/docs
POSTing file gb18030-example.xml (application/xml) to [base]
POSTing file hd.xml (application/xml) to [base]
POSTing file ipod_other.xml (application/xml) to [base]
POSTing file ipod_video.xml (application/xml) to [base]
POSTing file manufacturers.xml (application/xml) to [base]
POSTing file mem.xml (application/xml) to [base]
POSTing file money.xml (application/xml) to [base]
POSTing file monitor.xml (application/xml) to [base]
POSTing file monitor2.xml (application/xml) to [base]
POSTing file more_books.jsonl (application/json) to [base]/json/docs
POSTing file mp500.xml (application/xml) to [base]
POSTing file post.jar (application/octet-stream) to [base]/extract
POSTing file sample.html (text/html) to [base]/extract
POSTing file sd500.xml (application/xml) to [base]
POSTing file solr-word.pdf (application/pdf) to [base]/extract
POSTing file solr.xml (application/xml) to [base]
POSTing file test_utf8.sh (application/octet-stream) to [base]/extract
POSTing file utf8-example.xml (application/xml) to [base]
POSTing file vidcard.xml (application/xml) to [base]
21 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/techproducts/update...
Time spent: 0:00:00.822执行完上述过程,您的 Solr 中现在有数据了!
现在我们准备开始搜索。
基本搜索
可以通过 REST 客户端、curl、wget、Chrome POSTMAN 等,以及通过许多编程语言提供的本机客户端来查询Solr。
Solr Admin UI 通过 techproducts 集合的查询选项卡 (在 http://localhost:8983/solr/#/techproducts/query) 中包含一个查询生成器接口。如果单击“执行查询”按钮而不更改表单中的任何内容,则会以 JSON 格式获得10个文档:
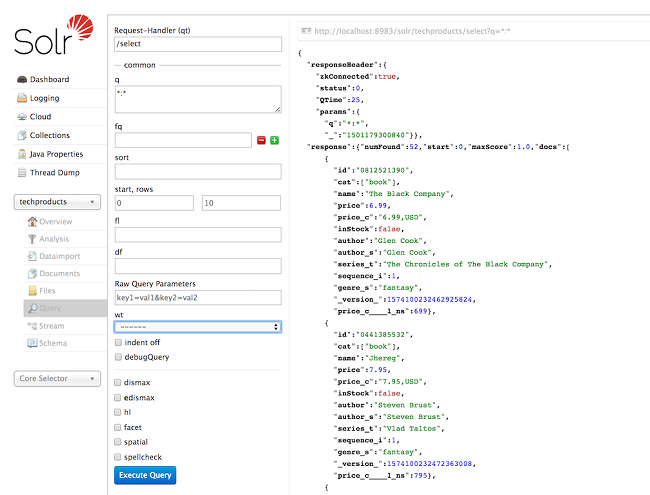
由 Admin UI 发送到 Solr 的 URL 在上面的屏幕截图的右上方以浅灰色显示。如果你点击它,你的浏览器会显示你的原始响应。
要使用 curl,请使用命令行中的引号在浏览器中显示相同的 URL:
curl "http://localhost:8983/solr/techproducts/select?indent=on&q=:"这里发生的事情是,我们正在使用 Solr 的查询参数(q)以特殊的语法来请求索引(:)中的所有文档。所有的文件都不会返回给我们,因为被称为行的参数是默认的,您可以在表单中看到10。如果您愿意,可以在 UI 或默认值中更改参数。
Solr 有非常强大的搜索选项,本教程将无法涵盖所有这些选项。但是我们可以涵盖一些最常见的查询类型。
搜索单个词条
要搜索一个术语,请在 Solr Admin UI 查询屏幕中将其作为 q 参数值输入,使用:替换为要查找的术语。
输入“foundation”,然后再次执行查询。
如果你喜欢 curl,请输入这样的内容:
curl "http://localhost:8983/solr/techproducts/select?q=foundation"你会看到这样的东西:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":8,
"params":{
"q":"foundation"}},
"response":{"numFound":4,"start":0,"maxScore":2.7879646,"docs":[
{
"id":"0553293354",
"cat":["book"],
"name":"Foundation",
"price":7.99,
"price_c":"7.99,USD",
"inStock":true,
"author":"Isaac Asimov",
"author_s":"Isaac Asimov",
"series_t":"Foundation Novels",
"sequence_i":1,
"genre_s":"scifi",
"version":1574100232473411586,
"price_cl_ns":799}]
}}响应表明有4个命中("numFound":4)。我们在上面的示例输出中只包含了一个文档,但是由于4个命中次数低于 rows 要返回的参数默认值10,所以应该看到它们全部4个。
请注意文档前的 responseHeader。此标题将包含您为搜索设置的参数。默认情况下,它仅显示您为此查询设置的参数,在本例中仅为查询术语。
我们得到的文件包括每个索引的文件的所有字段。这也是默认行为。如果要限制响应中的字段,可以使用 fl 参数,它使用逗号分隔的字段名称列表。这是管理界面中查询表单上的可用字段之一。
在 “fl” 框中输入“id”(不含引号),然后再次执行查询。或者,用 curl 指定它:
curl "http://localhost:8983/solr/techproducts/select?q=foundation&fl=id"您应该只能看到返回的匹配记录的 ID。
字段搜索
所有 Solr 查询都使用某个字段查找文档。通常,您希望同时在多个字段中进行查询,而这就是我们在 "基础" 查询中所做的工作。这可以通过使用已经在这组配置中设置的复制字段来实现。我们将在练习2中更详细地介绍复制字段。
但是,有时候,您想要将查询限制在单个字段中。这可以使您的查询效率更高,结果更符合用户的需求。
我们的小样本数据集中的大部分数据都与产品有关。假设我们想要找到索引中的所有“电子”产品。在查询屏幕中,在 q 框中输入“electronics”(不带引号),然后点击执行查询。你应该得到14个结果,例如:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":6,
"params":{
"q":"electronics"}},
"response":{"numFound":14,"start":0,"maxScore":1.5579545,"docs":[
{
"id":"IW-02",
"name":"iPod & iPod Mini USB 2.0 Cable",
"manu":"Belkin",
"manu_id_s":"belkin",
"cat":["electronics",
"connector"],
"features":["car power adapter for iPod, white"],
"weight":2.0,
"price":11.5,
"price_c":"11.50,USD",
"popularity":1,
"inStock":false,
"store":"37.7752,-122.4232",
"manufacturedate_dt":"2006-02-14T23:55:59Z",
"version":1574100232554151936,
"price_cl_ns":1150}]
}}此搜索查找在索引字段中任何位置包含术语“电子”的所有文档。但从上面我们可以看到有一个 cat 领域(“范畴”)。如果我们限制只搜索具有“电子”类别的文档,结果将会更精确。
在管理界面的 q 字段中更新您的查询 cat:electronics。现在你得到12个结果:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":6,
"params":{
"q":"cat:electronics"}},
"response":{"numFound":12,"start":0,"maxScore":0.9614112,"docs":[
{
"id":"SP2514N",
"name":"Samsung SpinPoint P120 SP2514N - hard drive - 250 GB - ATA-133",
"manu":"Samsung Electronics Co. Ltd.",
"manu_id_s":"samsung",
"cat":["electronics",
"hard drive"],
"features":["7200RPM, 8MB cache, IDE Ultra ATA-133",
"NoiseGuard, SilentSeek technology, Fluid Dynamic Bearing (FDB) motor"],
"price":92.0,
"price_c":"92.0,USD",
"popularity":6,
"inStock":true,
"manufacturedate_dt":"2006-02-13T15:26:37Z",
"store":"35.0752,-97.032",
"version":1574100232511160320,
"price_cl_ns":9200}]
}}使用 curl,这个查询看起来像这样:
curl "http://localhost:8983/solr/techproducts/select?q=cat:electronics"短语搜索
要搜索 multi-term 短语,请用双引号将其括起来:q="multiple terms here(这里的多个术语)"。例如,通过在管理用户界面的 "q" 框中输入引号来搜索 "CAS 滞后时间"。
如果你跟随 curl,请注意,术语之间的空间必须在 URL 中转换为“+”,如下所示:
curl "http://localhost:8983/solr/techproducts/select?q=\"CAS+latency\""我们得到2个结果:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":7,
"params":{
"q":"\"CAS latency\""}},
"response":{"numFound":2,"start":0,"maxScore":5.937691,"docs":[
{
"id":"VDBDB1A16",
"name":"A-DATA V-Series 1GB 184-Pin DDR SDRAM Unbuffered DDR 400 (PC 3200) System Memory - OEM",
"manu":"A-DATA Technology Inc.",
"manu_id_s":"corsair",
"cat":["electronics",
"memory"],
"features":["CAS latency 3, 2.7v"],
"popularity":0,
"inStock":true,
"store":"45.18414,-93.88141",
"manufacturedate_dt":"2006-02-13T15:26:37Z",
"payloads":"electronics|0.9 memory|0.1",
"version":1574100232590852096},
{
"id":"TWINX2048-3200PRO",
"name":"CORSAIR XMS 2GB (2 x 1GB) 184-Pin DDR SDRAM Unbuffered DDR 400 (PC 3200) Dual Channel Kit System Memory - Retail",
"manu":"Corsair Microsystems Inc.",
"manu_id_s":"corsair",
"cat":["electronics",
"memory"],
"features":["CAS latency 2, 2-3-3-6 timing, 2.75v, unbuffered, heat-spreader"],
"price":185.0,
"price_c":"185.00,USD",
"popularity":5,
"inStock":true,
"store":"37.7752,-122.4232",
"manufacturedate_dt":"2006-02-13T15:26:37Z",
"payloads":"electronics|6.0 memory|3.0",
"version":1574100232584560640,
"price_cl_ns":18500}]
}}结合搜索
默认情况下,当您在单个查询中搜索多个术语和短语时,Solr 只会要求其中一个存在以便文档匹配。包含更多词汇的文档将在结果列表中排序更高。
你可以要求用一个 + 来表示一个词或短语;相反,为了不允许出现一个词或短语,用一个前缀 -。
要查找包含“电子”和“音乐”两个术语的文档,请在管理界面查询选项卡的 q 框中输入:+electronics +music。
如果使用 curl,则必须对 + 字符进行编码,因为它在 URL 中具有保留的用途(对空格字符进行编码)。对于编码 + 是 %2B 如下所示:
curl "http://localhost:8983/solr/techproducts/select?q=%2Belectronics%20%2Bmusic"你只应得到一个结果。
要搜索包含术语“电子”但不包含“音乐” 一词的文档,请在管理界面的 q 框中输入:+electronics -music。对于 curl,再一次,对 URL 编码 + 是 %2B 如下所示:
curl "http://localhost:8983/solr/techproducts/select?q=%2Belectronics+-music"这一次你得到13个结果。
有关搜索的更多信息
我们只是提供了 Solr 中搜索选项的表面。有关更多 Solr 搜索选项,请参阅搜索部分。
本节练习总结
现在,您已经看到了 Solr 如何索引数据并做了一些基本的查询。您现在可以选择继续执行下一个示例,它将引入更多的 Solr 概念,例如分割结果和管理您的模式,或者您可以自行完成。
如果您决定不继续本教程,那么到目前为止我们索引的数据对您来说可能没什么价值。您可以删除您的安装并重新开始,也可以使用我们开始的 bin/solr 脚本删除此集合:
bin/solr delete -c techproducts然后创建一个新的集合:
bin/solr create -c -s 2 -rf 2要停止我们启动的两个 Solr 节点,发出命令:
bin/solr stop -all有关使用 bin/solr 的开始/停止和收集选项的详细信息,请参阅 Solr 控制脚本参考。