
Solr练习2:修改架构和索引影片数据
本练习将在最后一个基础上构建,向您介绍索引架构和 Solr 强大的 faceting 功能。
重新启动 Solr
如果在上一节的练习中您没有停止 Solr,则继续进行本节内容。
但是,如果您确实需要重新启动 Solr,请发出以下命令:
./bin/solr start -c -p 8983 -s example/cloud/node1/solr这将启动第一个节点。当它完成后,启动第二个节点,并告诉它如何连接到 ZooKeeper:
./bin/solr start -c -p 7574 -s example/cloud/node2/solr -z localhost:9983创建一个新的集合
我们将在这个练习中使用一个全新的数据集,所以最好有一个新的集合,而不是试图重复使用之前的集合。
其中一个原因是我们将在 Solr 中使用一个名为“字段猜测”的特性,在这个特性中,Solr 试图猜测索引它时字段中的数据是什么类型的。它还会自动在架构中为出现在传入文档中的新字段创建新字段。这种模式被称为 “无架构”。我们将看到这种方法的优点和局限性,以帮助您决定在实际应用中如何以及如何使用它。
什么是“架构”,为什么我需要一个?
Solr 的架构是一个单独的文件(以 XML 格式),它存储了有关 Solr 应该理解的字段和字段类型的详细信息。架构不仅定义字段或字段类型名称,而且定义字段在索引之前应该发生的任何修改。例如,如果要确保输入“abc” 的用户和输入“ABC” 的用户都能找到包含 “ABC” 的文档,则需要进行标准化(在这种情况下为小写) )当它被索引的时候 “ABC”,并且规范化用户查询以确保匹配。这些规则在您的架构中定义。
在前面的教程中,我们提到了复制字段,这些字段是由来自其他字段的数据组成的字段。您还可以定义动态字段,这些字段使用通配符(如 _t 或 _s)来动态创建特定字段类型的字段。这些类型的规则也在架构中定义。
在第一个练习中最初启动 Solr 时,我们可以选择一个 configSet 来使用。我们选择的一个架构是为我们稍后索引的数据预先定义的。这一次,我们将使用具有非常小的模式的 configSet,并让 Solr 从数据中找出要添加的字段。
您要索引的数据与电影相关,因此首先创建一个名为 “films” 的集合,该集合使用 _defaultconfigSet:
bin/solr create -c films -s 2 -rf 2哇,等等。我们没有指定一个 configSet!没关系,这 _default 是适当的命名,因为它是默认的,如果你没有指定一个,就使用它。
我们没有,但是,设置两个参数 -s 和 -rf。这些是分割集合的分割的数量(2)以及要创建的副本数量(2)。这相当于我们在第一个练习的互动示例中所做的选择。
你应该看到如下输出:
WARNING: Using _default configset. Data driven schema functionality is enabled by default, which is
NOT RECOMMENDED for production use.
To turn it off:
curl http://localhost:7574/solr/films/config -d '{"set-user-property": {"update.autoCreateFields":"false"}}'
Connecting to ZooKeeper at localhost:9983 ...
INFO - 2017-07-27 15:07:46.191; org.apache.solr.client.solrj.impl.ZkClientClusterStateProvider; Cluster at localhost:9983 ready
Uploading /7.0.0/server/solr/configsets/_default/conf for config films to ZooKeeper at localhost:9983
Creating new collection 'films' using command:
http://localhost:7574/solr/admin/collections?action=CREATE&name=films&numShards=2&replicationFactor=2&maxShardsPerNode=2&collection.configName=films
{
"responseHeader":{
"status":0,
"QTime":3830},
"success":{
"192.168.0.110:8983_solr":{
"responseHeader":{
"status":0,
"QTime":2076},
"core":"films_shard2_replica_n1"},
"192.168.0.110:7574_solr":{
"responseHeader":{
"status":0,
"QTime":2494},
"core":"films_shard1_replica_n2"}}}命令打印的第一件事是关于在生产中不使用这个 configSet 的警告。这是由于我们稍后会涉及的一些限制。
否则,应该创建集合。如果我们转到:http:// localhost:8983 / solr /#/ films / collection-overview上的管理界面,我们应该看到总览屏幕。
为电影数据准备无架构
_defaultconfigSet 附带的架构有两个并行的事情发生。
首先,我们使用一个“托管模式”,它被配置为只能被 Solr 的 Schema API 修改。这意味着我们不应该手工编辑它,所以不会对从哪个来源进行编辑造成混淆。Solr 的Schema API 允许我们对字段、字段类型和其他类型的模式规则进行更改。
其次,我们使用 solrconfig.xml 文件中配置的“字段猜测” (并包括 Solr 的各种配置设置)。字段猜测的目的是让我们开始使用 Solr,而不必在尝试为索引建立索引之前定义我们认为将在我们的文档中的所有字段。这就是为什么我们称之为“无架构”的原因,因为您可以快速启动,让 Solr 在您遇到文档时为您创建字段。
听起来不错!但是有限制。如果它猜错了,您不能改变很多关于一个字段的数据已经索引后,而不必重新索引。如果我们只有几千个可能并不坏的文档,但是如果您拥有数百万甚至数百万个文档,或者更糟糕的是无法再访问原始数据,这可能是一个真正的问题。
出于这些原因,Solr 社区不建议在没有您自己定义的架构的情况下进行生产。通过这个,我们的意思是无架构功能可以从头开始,但是您仍然应该始终确保您的架构符合您希望数据索引的方式以及用户将如何查询它的期望。
可以将无架构功能与定义的架构混合使用。使用 Schema API,您可以定义一些您想要控制的字段,然后让 Solr 猜测其他不太重要的字段,或者通过测试确信自己的信心会被猜测到您满意。这就是我们要在这里做的。
创建“name”字段
我们要索引的电影资料,每部电影都有少量的字段:一个 ID、导演姓名、电影名称、发行日期和类型。
如果您查看其中一个文件 example/films,您将看到 2006 年发行的第一部影片名为 .45。作为数据集中的第一个文档,Solr 将根据记录中的数据猜测字段类型。如果我们继续索引这些数据,那么第一个影片名称将会告诉 Solr 该字段类型是一个 “float” 数字字段,并且将会创建一个 “name” 的字段,类型为 FloatPointField。此记录之后的所有数据将被预期为浮动的。
那么,这是行不通的。我们有一个名字,像一个强大的风和鸡运行,这是字符串 - 决不是数字,而不是浮动。如果我们让 Solr 猜测 “name” 字段是一个浮点数,那么稍后的标题会导致一个错误,索引将失败。
在索引数据之前,我们可以做的是在 Solr 中设置 “name” 字段,以确保 Solr 始终将其解释为一个字符串。在命令行输入这个 curl 命令:
curl -X POST -H 'Content-type:application/json' --data-binary '{"add-field": {"name":"name", "type":"text_general", "multiValued":false, "stored":true}}' http://localhost:8983/solr/films/schema该命令使用 Schema API 来显式定义一个名为 “name” 的字段,该字段的字段类型为 “text_general”(一个文本字段)。它不会被允许有多个值,但它将被存储(这意味着它可以通过查询来检索)。
您也可以使用管理界面来创建字段,但对字段属性的控制较少。但是,它将为我们的案件工作:
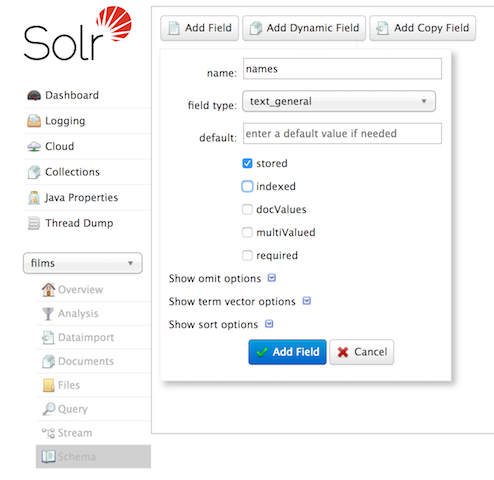
创建一个“catchall”复制字段
在我们开始索引之前还有一个更改要做。
在第一个练习中,当我们查询已经建立索引的文档时,我们不需要指定一个字段进行搜索,因为我们使用的配置被设置为将字段复制到一个 text 字段中,并且在查询中没有定义其他字段时,该字段是默认值。
我们现在使用的配置没有这个规则。我们需要定义一个字段来搜索每个查询。然而,我们可以通过定义一个复制字段来设置一个“catchall 字段”,该字段将从所有字段获取所有数据并将其索引到一个名为 text 的字段中。
您可以使用管理用户界面或架构 API。
在命令行中,再次使用 Schema API 来定义一个复制字段:
curl -X POST -H 'Content-type:application/json' --data-binary '{"add-copy-field" : {"source":"","dest":"text"}}' http://localhost:8983/solr/films/schema在管理界面中,选择添加复制字段,然后填写您的字段的来源和目的地,如此屏幕截图所示。
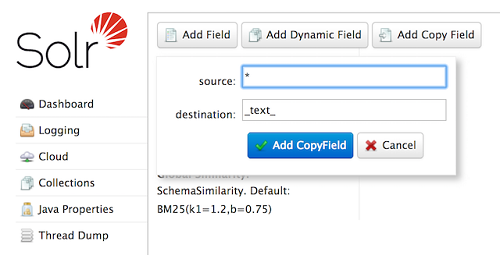
这是做所有字段的副本,并将数据放入 “text” 字段。
Tip:使用您的生产数据进行此工作可能非常昂贵,因为它会告诉 Solr 有效地将所有内容索引两次。它将使索引更慢,并使索引更大。使用您的生产数据,您将希望确保只复制真正为您的应用程序保证的字段。好的,现在我们已经准备好索引数据并开始了。
索引样本电影数据
我们将索引的电影数据位于您的安装目录 example/films 中。它有三种格式:JSON、XML 和 CSV。选择其中的一种格式,并将其索引到 “电影” 集合中(在每个示例中,一个命令用于 Unix / MacOS,另一个用于 Windows):
索引 JSON 格式:
bin/post -c films example/films/films.json
C:\solr-7.0.0> java -jar -Dc=films -Dauto example\exampledocs\post.jar example\films.json索引 XML 格式:
bin/post -c films example/films/films.xml
C:\solr-7.0.0> java -jar -Dc=films -Dauto example\exampledocs\post.jar example\films.xml索引 CSV 格式:
bin/post -c films example/films/films.csv -params "f.genre.split=true&f.directed_by.split=true&f.genre.separator=|&f.directed_by.separator=|"
C:\solr-7.0.0> java -jar -Dc=films -Dparams=f.genre.split=true&f.directed_by.split=true&f.genre.separator=|&f.directed_by.separator=| -Dauto example\exampledocs\post.jar example\films\*.csv每个命令都包含这些主要参数:
- -c films:这是 Solr 收集索引数据。
- example/films/films.json(或 films.xml 或 films.csv):这是数据文件索引的路径。您可以简单地提供该文件所在的目录,但由于您知道要编制索引的格式,因此指定该格式的确切文件效率更高。
请注意,CSV 命令包含额外的参数。这是为了确保 “genre” 和 “directed_by” 列中的多值条目被 pipe(|)字符分隔,在此文件中用作分隔符。告诉 Solr 这样分割这些列将确保正确的数据索引。
每个命令将产生类似于索引 JSON 时看到的下面的输出:
$ ./bin/post -c films example/films/films.json
/bin/java -classpath /solr-{solr-docs-version}.0/dist/solr-core-{solr-docs-version}.0.jar -Dauto=yes -Dc=films -Ddata=files org.apache.solr.util.SimplePostTool example/films/films.json
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/films/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file films.json (application/json) to [base]/json/docs
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/films/update...
Time spent: 0:00:00.878如果您进入影片管理界面(http:// localhost:8983 / solr /#/ films / query)中的查询屏幕并点击执行查询,您应该会看到 1100 个结果,前10个返回到屏幕。
让我们做一个查询,看看 “catchall” 字段是否正常工作。在 q 框中输入“喜剧”,然后再次点击“ 执行查询”。你应该看到得到417个结果。
Faceting
Solr 最受欢迎的功能之一就是 faceting。faceting 允许将搜索结果排列成子集(或 buckets 或 categories),为每个子集提供计数。有几种类型的 faceting:字段值、数字和日期范围、枢轴(决策树)和任意查询 faceting。
字段 Facets
除了提供搜索结果之外,Solr 查询还可以返回包含整个结果集中每个唯一值的文档的数量。
在“管理用户界面查询”选项卡上,如果选中该 facet 复选框,则会看到几个与方面相关的选项:

要查看所有文档(q=:)中的 facet 计数:打开 faceting(facet=true),并通过 facet.fieldparam 指定要打开的字段。如果您只想要 facet,并且没有文档内容,请指定 rows=0。下面的 curl 命令将返回 genre_str 字段的 facet 计数:
curl "http://localhost:8983/solr/films/select?q=:&rows=0&facet=true&facet.field=genre_str"在您的终端中,您会看到如下所示的内容:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":11,
"params":{
"q":"*:*",
"facet.field":"genre_str",
"rows":"0",
"facet":"true"}},
"response":{"numFound":1100,"start":0,"maxScore":1.0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{
"genre_str":[
"Drama",552,
"Comedy",389,
"Romance Film",270,
"Thriller",259,
"Action Film",196,
"Crime Fiction",170,
"World cinema",167]},
"facet_ranges":{},
"facet_intervals":{},
"facet_heatmaps":{}}}我们已经在这里截断了一些输出,但是在本 facet_counts 节中,默认情况下,您会看到索引中每个类型的文档使用的数量。Solr 有一个参数 facet.mincount,可以用来限制只有那些包含一定数量的文档的 facets(这个参数在 UI 中没有显示)。或者,您也许需要所有的方面,并且让您的应用程序的前端控制如何显示给用户。
如果你想控制一个 bucket 中的物品数量,你可以做这样的事情:
curl "http://localhost:8983/solr/films/select?=&q=:&facet.field=genre_str&facet.mincount=200&facet=on&rows=0"你只能看到4个方面返回。
还有很多其他参数可以帮助您控制 Solr 如何构建 facets 和 facet 列表。我们将在本练习中介绍其中的一部分,但你也可以在 Faceting 部分了解更多的细节。
范围 Facets
对于数字或日期,通常希望将 facet 计数划分为范围而不是离散值。数字范围 faceting 的一个主要例子是,使用我们以前的练习中的例子 techproducts 数据:price。在 /browseUI 中,它看起来像这样:

电影数据包括电影的发行日期,我们可以使用它来创建日期范围方面,这是范围方面的另一个常见用途。
Solr 管理用户界面还不支持范围方面的选项,因此您将需要使用 curl 或类似的命令行工具以下示例。
如果我们构造一个如下所示的查询:
curl 'http://localhost:8983/solr/films/select?q=:&rows=0'\
'&facet=true'\
'&facet.range=initial_release_date'\
'&facet.range.start=NOW-20YEAR'\
'&facet.range.end=NOW'\
'&facet.range.gap=%2B1YEAR'这将要求所有的电影,并要求他们从20年前(我们最早的发布日期在2000年)开始到今天结束的年份。请注意,此查询再次将 URL 编码 + 为 %2B。
在终端你会看到:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":8,
"params":{
"facet.range":"initial_release_date",
"facet.limit":"300",
"q":"*:*",
"facet.range.gap":"+1YEAR",
"rows":"0",
"facet":"on",
"facet.range.start":"NOW-20YEAR",
"facet.range.end":"NOW"}},
"response":{"numFound":1100,"start":0,"maxScore":1.0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_ranges":{
"initial_release_date":{
"counts":[
"1997-07-28T17:12:06.919Z",0,
"1998-07-28T17:12:06.919Z",0,
"1999-07-28T17:12:06.919Z",48,
"2000-07-28T17:12:06.919Z",82,
"2001-07-28T17:12:06.919Z",103,
"2002-07-28T17:12:06.919Z",131,
"2003-07-28T17:12:06.919Z",137,
"2004-07-28T17:12:06.919Z",163,
"2005-07-28T17:12:06.919Z",189,
"2006-07-28T17:12:06.919Z",92,
"2007-07-28T17:12:06.919Z",26,
"2008-07-28T17:12:06.919Z",7,
"2009-07-28T17:12:06.919Z",3,
"2010-07-28T17:12:06.919Z",0,
"2011-07-28T17:12:06.919Z",0,
"2012-07-28T17:12:06.919Z",1,
"2013-07-28T17:12:06.919Z",1,
"2014-07-28T17:12:06.919Z",1,
"2015-07-28T17:12:06.919Z",0,
"2016-07-28T17:12:06.919Z",0],
"gap":"+1YEAR",
"start":"1997-07-28T17:12:06.919Z",
"end":"2017-07-28T17:12:06.919Z"}},
"facet_intervals":{},
"facet_heatmaps":{}}}枢轴 Facets
另一个 faceting 类型是数据透视 facets,也称为“决策树”,允许两个或多个字段为所有各种可能的组合嵌套。使用电影数据,可以使用数据透视面来查看 “Drama” 类别(genre_str 字段)中有多少电影由导演指导。以下是如何获取此方案的原始数据:
curl "http://localhost:8983/solr/films/select?q=:&rows=0&facet=on&facet.pivot=genre_str,directed_by_str"这导致了以下回应,其中显示了每个类别和导演组合的一个方面:
{"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":1147,
"params":{
"q":"*:*",
"facet.pivot":"genre_str,directed_by_str",
"rows":"0",
"facet":"on"}},
"response":{"numFound":1100,"start":0,"maxScore":1.0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_ranges":{},
"facet_intervals":{},
"facet_heatmaps":{},
"facet_pivot":{
"genre_str,directed_by_str":[{
"field":"genre_str",
"value":"Drama",
"count":552,
"pivot":[{
"field":"directed_by_str",
"value":"Ridley Scott",
"count":5},
{
"field":"directed_by_str",
"value":"Steven Soderbergh",
"count":5},
{
"field":"directed_by_str",
"value":"Michael Winterbottom",
"count":4}}]}]}}}我们也截断了这个输出 - 你会在屏幕上看到很多流派和导演。
Solr 练习2总结
在这个练习中,我们进一步了解了 Solr 如何在索引中组织数据,以及如何使用 Schema API 来操作架构文件的知识。我们还了解了 Solr 的一些 facets,包括范围 facets和数据透视 facets。在这两方面,我们只是抓住了可用选项的表面。如果你能做到这一点,这是可能的!
像我们以前的练习一样,这些数据可能与您的需求无关。我们可以通过删除集合来清理我们的工作。为此,请在命令行中发出以下命令:
bin/solr delete -c films