
CDCR概述
跨数据中心复制(CDCR)允许您创建多个SolrCloud数据中心并使它们保持同步。
该SolrCloud架构设计支持在一个数据中心的多个节点(NRT)上的 Solr 集合附近的实时搜索。“CDCR”通过将更新从一个数据中心的Solr集合转发到另一个网络延迟大于SolrCloud模型的数据中心的并行Solr集合来增强此模型。
什么是CDCR?
CDCR支持将数据从一个数据中心复制到多个数据中心。该解决方案的初始版本支持单向方案,即将数据更新从源数据中心复制到一个或多个目标数据中心。
目标数据中心不会将更新 (如添加、更新或删除) 传播到源数据中心,并且不应将更新发送到任何目标数据中心。
在CDCR运行时,源数据中心和目标数据中心可以提供搜索查询。由于传播延迟,目标数据中心将滞后于源集群。
只有将源数据中心上的数据更改保存到磁盘后,才会将其复制到目标数据中心。数据更改可以近实时地(稍微延迟)被复制,或者可以安排在更长的时间间隔内发送到目标数据中心。CDCR可以将集合“引导”到目标数据中心。由于这是整个索引的完整副本,所以应该考虑网络带宽。当然,源和目标集合可能是空的开始。
源数据中心中的每个分片负责人将负责将其更新复制到目标数据中心的相应负责人。当从源数据中心接收到更新时,目标数据中心中的分片领导将按照正常的SolrCloud更新将更改复制到自己的副本。
此复制模型旨在容忍某些连接性下降,容纳有限的带宽,并支持批量更新以优化通信。
复制同时支持新的空索引和预建索引。在源集群中的预构建索引上设置复制并且目标集群上没有任何内容的情况下,CDCR将把整个索引从源复制到目标。这个功能被添加到Solr 6.2中。
初始实现的单向性意味着从Source集合到Target集合的“push”模型。因此,Source配置必须能够“查看”目标集群中的ZooKeeper集合。ZooKeeper集合在源solrconfig.xml文件中提供。
CDCR配置为按照逐个集合的方式从源集群中的集合复制到目标集群中的集合。由于CDCR配置在solrconfig.xml(在源和目标群集上),所以可以根据每个集合的需要量身定制设置。
可以将CDCR配置为从同一集群中的一个集合复制到第二个集合。这是本文档中没有涉及的一种特殊情况。
CDCR术语表
本文中使用的术语包括:
- Node
运行Solr的JVM实例;一台服务器。
- Cluster
由一个ZooKeeper集合管理一个或多个集合的一组Solr节点。
- Data Center
托管Solr集群的一组网络服务器。在本文档中,“Cluster”和“Data Center”这两个术语是可以互换的,因为我们假设每个Solr群集都驻留在不同的联网服务器组中。
- Shard
单个逻辑集合的子索引。这可能分布在群集的多个节点上。每个分片可以有1-N个副本。
- Leader
每个碎片都有一个副本被确定为其leader。所有属于分片的文档的写入都通过leader传送。
- Replica
用于故障转移或负载平衡的碎片副本。包含碎片的副本可以是leader也可以是非leader。
- Follower
对于不是分片leader的副本的便利术语。
- Collection
逻辑索引,由一个或多个碎片组成。一个集群可以有多个集合。
- Update
以任何方式更改集合索引的操作。这可能是添加新文档,删除文档或更改文档。
- Update Log(s)
由每个节点维护的写入操作的追加日志。
CDCR架构
这里是CDCR数据流的图片。
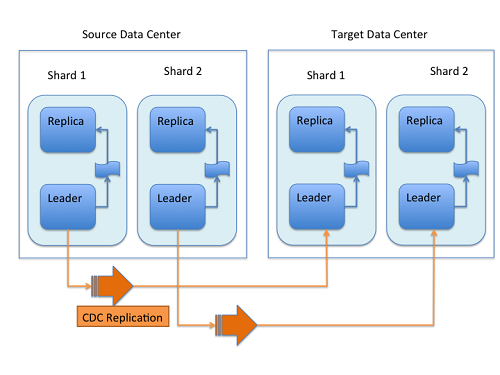
首先将更新和删除写入到源群集,然后转发到目标群集。数据流的顺序是:
- 碎片组长接收由其更新处理器链处理的新更新。
- 数据更新首先应用于本地索引。
- 在本地索引上成功应用数据更新后,数据更新将被添加到“更新日志”队列中。
- 数据更新持久化到磁盘后,数据更新将发送到数据中心内的副本。
- 步骤4成功后,CDCR从更新日志读取数据更新并将其推送到目标数据中心中的相应集合。为了确保源数据中心和目标数据中心之间的一致性,这是必要的。
- 目标数据中心的负责人在本地写入数据并将其转发给所有追随者。
步骤1、2、3和4由SolrCloud同步执行;步骤5由后台线程异步执行。考虑到CDCR复制是异步执行的,因此可以推送批量更新以最小化网络通信开销。此外,如果CDCR无法在给定时间推送更新(例如,由于连接性降低),则以后可以重试,而不会对Source数据中心产生任何影响。
这个架构的一个含义是,源集群中的leader必须能够“看到”目标集群中的leader。由于leader可能在源和目标集合中都发生变化,这意味着源集群中的所有节点都必须能够“查看”目标集群中的所有Solr节点,因此必须配置防火墙,ACL规则等以允许这样做。
如果源簇和目标簇具有相同数量的碎片,则当前设计最有效。没有要求源和目标集合中的分片具有相同数量的副本。
在源和目标集群上有不同数量的碎片是可能的,但也是“专业”配置,因为该选项会强加某些约束,并且通常不建议这样做。通过在每个Solr实例上托管多个碎片,可以更好地完成大多数具有不同碎片数量的情况。