
合并Distribution和Replication
合并Distribution和Replication
如果您的索引对于单台计算机来说太大,并且您的查询量无法与单个分片保持同步,那么是时候在分布式搜索设置中复制每个分片。
这个想法是将分布式搜索与复制相结合。如下图所示,组合的分布式复制配置使用每个分片的master服务器,然后从master服务器复制1到n个slave服务器。在标准复制配置中,master服务器处理更新和优化,而不会不利地影响查询处理性能。
查询请求应在每个分片奴隶之间进行负载平衡。如果服务器出现故障,这可以增加查询处理能力和故障切换备份。
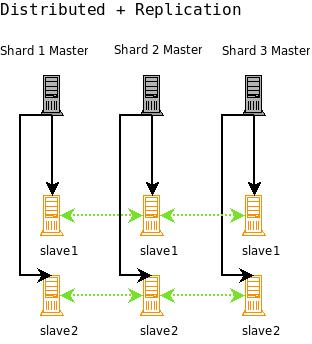
上图表示的是:组合了复制和master-slave分布的Solr配置
这个配置中的master分片都不知道彼此。您可以索引到每个master,将索引复制到每个slave,然后然后在整个slave服务器上分布搜索,使用每个master/slave分片中的一个slave。
为了实现高可用性,您可以使用负载均衡器为每个分片的slave设置一个虚拟IP。如果您不熟悉负载平衡,HAProxy(http://haproxy.1wt.eu/)是一个很好的开源软件负载平衡器。如果从属服务器发生故障,一个好的负载均衡器将使用某种技术(通常是心跳系统)检测到故障,并将所有请求转发给与故障slave在一起的剩余活动slave。然后应设置单个虚拟IP,以便请求可以访问单个IP,并为搜索slave服务器的每个虚拟IP获得负载平衡。
通过这种配置,您将拥有完全负载均衡的搜索方容错系统(Solr尚不支持容错索引)。传入的搜索将被移交给其中一个正在运行的slave,然后slave将为您的配置中的每个碎片分配搜索请求。slave将向每个分片的每个虚拟IP发出请求,负载均衡器将选择其中一个可用的slave。最后,结果将被合并成一个结果集并返回。如果任何一个slave不能用,他们将被取消旋转,其余的奴隶将被使用。如果一个分片master失败了,那么仍然可以从这个slave提供搜索,直到你纠正了这个问题并把这个master重新投入生产。