
如何运行Solr分析器
一旦在 Solr 架构中定义了一个字段类型,并指定了要应用于它的分析步骤,则应该对其进行测试,以确保它的行为按照预期的方式进行。
幸运的是,Solr 管理界面中有一个非常方便的页面,可以让您做到这一点。您可以调用分析器的任何文本字段,提供示例输入,并显示结果的令牌流。
例如,让我们看一下 bin/solr -e techproducts 示例配置中可用的一些 “文本” 字段类型,并使用分析屏幕(http://localhost:8983/solr/#/techproducts/analysis)来比较在索引时为 “运行分析器” 的语句生成的令牌如何匹配查询 “运行我的分析仪” 文本
我们可以从 “ text_ws” 开始 - 可用的最简化的文本字段类型之一:
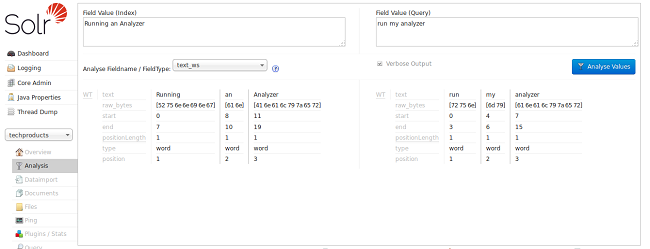
通过查看每个术语的开始和结束位置,我们可以看到这个字段类型所做的唯一的事情是在空白处标记文本。注意在这个图像中,术语 “Running” 具有0的起始位置和7的结束位置,而 “an” 具有8的起始位置和10的结束位置,并且“分析器”从11开始并结束于19。如果条款之间的空白也包括在内,则数字为21;因为它是19,我们知道空白已经从这个查询中删除。
还要注意,索引术语和查询术语仍然非常不同。“Running” 不匹配 “run”,“Analyzer” 不匹配 “analyzer”(对电脑),显然 “an” 和 “my” 是完全不同的话。如果我们的目标是允许诸如 “运行我的分析器” 这样的查询与 “运行分析器” 等索引文本相匹配,那么我们显然需要选择一个与索引和查询时间文本分析不同的字段类型,这样可以对输入进行更多处理。
我们特别希望:
- 不区分大小写,所以 “Analyzer” 和 “analyzer” 相匹配。
- 词干,所以像 “Run” 和 “Running” 这样的词被认为是等同的词语。
- 停止单词修剪,所以 “an” 和 “my” 这样的小单词不会影响查询。
对于我们的下一个尝试,让我们尝试 “ text_general” 字段类型:
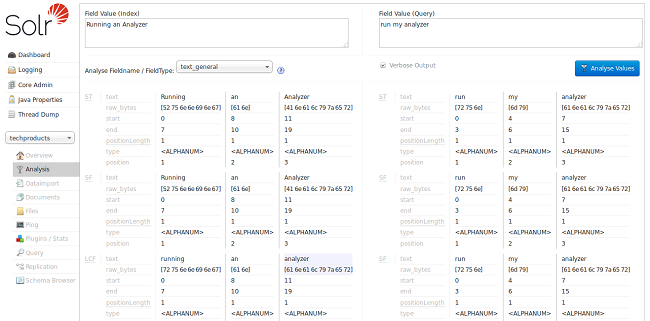
通过启用详细输出,我们可以看到新分析器的每个阶段在将它们传递到下一个阶段之前如何修改它们所接收到的令牌。当我们向下滚动到最后的输出时,我们可以看到,从 “LCF” 阶段开始,我们开始从每个输入字符串获得 “analyzer” 的匹配,如果你用鼠标悬停,你会看到是 “ LowerCaseFilter”:
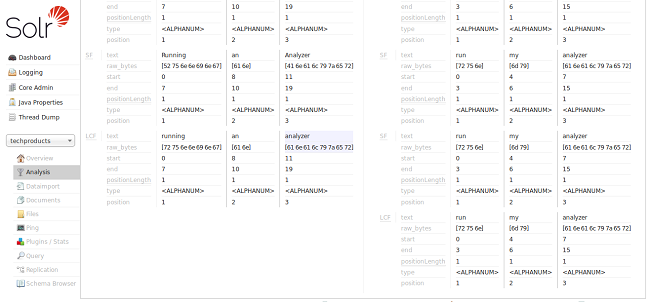
“text_general” 字段类型被设计为通常对任何语言都有用,而且它肯定使我们更接近我们的目标,而不是从我们第一个例子中的 "text_ws" 来解决区分大小写的问题。这还不是我们正在寻找的东西,因为我们没有看到正在应用的词干或停用词规则。所以现在让我们试试 “text_en” 字段类型:
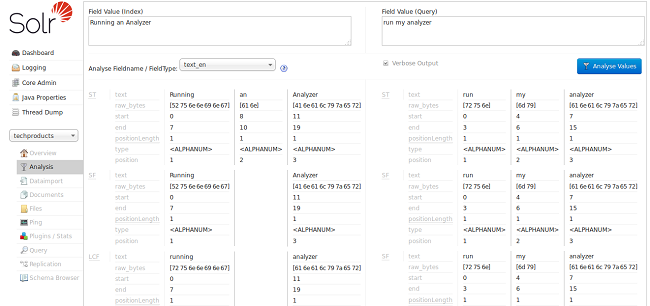
现在我们可以看到分析器的 "SF" (StopFilter) 阶段解决了消除停止单词 ("an") 的问题,当我们向下滚动时,我们也看到 “PSF”(PorterStemFilter)阶段应用适合我们英语的词干规则语言输入,这样我们的“索引分析器”产生的术语和我们的“查询分析器”产生的术语就与我们期望的方式相匹配。
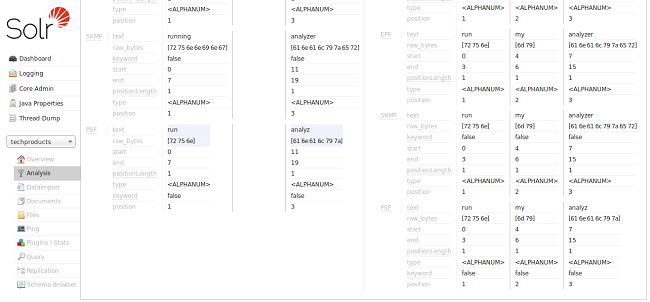
在这一点上,我们可以继续尝试更多的输入,验证我们的分析器在我们期望它们匹配时产生匹配的令牌,当我们不期望它们匹配时验证不同的令牌,因为我们重复和调整了我们的字段类型配置。