
Solr如何使用并行SQL接口
Solr的并行SQL接口将SQL的强大功能带入了SolrCloud。
SQL接口将SQL与Solr的全文搜索功能无缝地结合在一起。支持MapReduce风格和JSON Facet API聚合,这意味着SQL接口可以用来支持高查询量和高基数用例。
SQL体系结构
SQL接口允许发送一个SQL查询到Solr,并使文档在响应时得到回流。在该覆盖范围内,Solr的SQL接口使用Apache Calcite SQL引擎将SQL查询转换为以Streaming Expressions实现的物理查询计划。
Solr集合和数据库表
在标准SELECT语句中,例如:SELECT <expressions> FROM <table>,表名对应于Solr集合名称。表名不区分大小写。
SQL查询中的列名直接映射到正在查询的集合的Solr索引中的字段。这些标识符区分大小写。支持别名,可以在ORDER BY子句中引用。
在有限或无限制的查询中不支持用于指示所有字段的 * 语法。该score字段只能用于包含LIMIT子句的查询。
例如,我们可以索引Solr的示例文档,然后构造一个类似如下的 SQL 查询:
SELECT manu as mfr, price as retail FROM techproducts我们正在使用的Solr的集合是“techproducts”,我们已经要求将“manu”和“price”字段返回,并使用新名称进行别名。虽然这个例子不使用这些别名,但我们可以在此基础上根据其中一个或多个字段进行ORDER BY。
有关如何为Solr构建SQL查询的更多信息,请参见下面的“Solr SQL语法”部分。
聚合模式
Solr的SQL功能可以通过两种方式与聚合(结果分组)结合使用:
- facet:这是默认的聚合模式,它使用JSON Facet API或StatsComponent进行聚合。在这种情况下,聚合逻辑被推入搜索引擎,只有聚合通过网络发送。这是Solr的正常操作模式。当GROUP BY字段的基数低到中等时,这是很快的。但是,当GROUP BY字段中有高基数字段时,它会中断。
- map_reduce:这个实现将元组拖到到工作节点,并在工作节点上执行聚合。它涉及对整个结果集进行排序和分区并将其发送给工作节点。在这种方法中,元组到达由GROUP BY字段排序的工作节点。然后,工作节点可以一次汇总一个组的汇总。这样可以实现无限的基数聚合,但是您需要付出通过网络将整个结果集发送给工作节点的代价。
当将请求发送到Solr时,这些模式被定义为aggregationMode。
如上所述,聚合模式之间的选择取决于您正在使用的字段的基数。如果您在分组的字段中具有低到中等的基数,那么“facet”聚合模式将为您提供更高的性能,因为只返回最终的组,因此与今天的facet工作方式非常相似。但是,如果在字段中的基数很高,那么带有工作节点的“map_reduce”聚合模式将提供更高性能的选项。
配置
用于SQL接口的请求处理程序被配置为隐式加载,这意味着开始使用此功能几乎没有什么要做。
/sql请求处理程序
/sql处理程序是并行SQL接口的前端。所有SQL查询都发送到/sql处理程序进行处理。该处理程序还在map_reduce模式中运行GROUP BY和SELECT DISTINCT查询时协调分布式MapReduce作业。默认情况下,/sql处理程序将从其自己的集合中选择工作节点来处理分布式操作。在此默认场景中,/sql处理程序所在的集合充当MapReduce查询的默认工作者集合。
默认情况下,/sql请求处理程序被配置为隐式处理程序,这意味着它在每个Solr安装中始终处于启用状态,不需要进一步的配置。
注意:正如在“最佳实践”小节中所述,您可能希望为并行SQL查询设置一个单独的集合。如果您拥有高基数字段和大量数据,请务必查看该部分,并考虑使用单独的集合。
/stream和/export请求处理程序
Streaming API是SolrCloud的可扩展并行计算框架。流表达式为Streaming API提供查询语言和序列化格式。
Streaming API提供对快速MapReduce的支持,允许它在极大的数据集上执行并行关系代数。在覆盖范围内,SQL接口使用Apache Calcite SQL解析器解析SQL查询。然后将查询转换为并行查询计划。并行查询计划使用Streaming API和Streaming Expressions表示。
像/sql请求处理程序中,/stream和/export请求处理程序被配置为隐式的处理程序,并且不需要进一步的配置。
字段
在某些情况下,SQL查询中使用的字段必须配置为DocValue字段。如果查询是无限的,则所有的字段必须是DocValue字段。如果查询是有限的(使用该limit子句),则字段不需要启用DocValues。
发送查询
SQL接口提供了一个基本的JDBC驱动程序和一个HTTP接口来执行查询。
JDBC驱动程序
使用SolrJ的JDBC驱动程序。以下是创建连接并使用JDBC驱动程序执行查询的示例代码:
Connection con = null;
try {
con = DriverManager.getConnection("jdbc:solr://" + zkHost + "?collection=collection1&aggregationMode=map_reduce&numWorkers=2");
stmt = con.createStatement();
rs = stmt.executeQuery("SELECT a_s, sum(a_f) as sum FROM collection1 GROUP BY a_s ORDER BY sum desc");
while(rs.next()) {
String a_s = rs.getString("a_s");
double s = rs.getDouble("sum");
}
} finally {
rs.close();
stmt.close();
con.close();
}连接URL必须包含zkHost和collection参数。该集合必须是指定ZooKeeper主机上的有效SolrCloud集合。该集合还必须使用/sql处理程序进行配置。aggregationMode和numWorkers参数都是可选的。
HTTP接口
Solr通过/sql处理程序接受并行SQL查询。
下面是在facet模式下执行SQL聚合查询的curl命令示例:
curl --data-urlencode 'stmt=SELECT to, count(*) FROM collection4 GROUP BY to ORDER BY count(*) desc LIMIT 10' http://localhost:8983/solr/collection4/sql?aggregationMode=facet以下是样本结果集:
{"result-set":{"docs":[
{"count(*)":9158,"to":"pete.davis@enron.com"},
{"count(*)":6244,"to":"tana.jones@enron.com"},
{"count(*)":5874,"to":"jeff.dasovich@enron.com"},
{"count(*)":5867,"to":"sara.shackleton@enron.com"},
{"count(*)":5595,"to":"steven.kean@enron.com"},
{"count(*)":4904,"to":"vkaminski@aol.com"},
{"count(*)":4622,"to":"mark.taylor@enron.com"},
{"count(*)":3819,"to":"kay.mann@enron.com"},
{"count(*)":3678,"to":"richard.shapiro@enron.com"},
{"count(*)":3653,"to":"kate.symes@enron.com"},
{"EOF":"true","RESPONSE_TIME":10}]}
}请注意,结果集是具有与SQL列列表匹配的键/值对的元组数组。最后的元组包含EOF标志,表示流的结束。
Solr SQL语法
Solr支持广泛的SQL语法。
SQL解析器对大小写不敏感:Solr使用SQL解析器来转换SQL语句是不区分大小写的。但是,为了便于阅读,本页面上的所有示例均使用大写的关键字。
转义保留字
如果在SQL查询中使用保留字,则SQL解析器将返回一个错误。保留字可以被转义并且包含在查询中。例如:
select `from` from emailsSELECT语句
Solr支持有限和无限的选择查询。除了SQL语句中的LIMIT子句之外,这两种查询之间的语法是相同的。但是,它们对数据的存储方式有非常不同的执行计划和不同的要求。下面的部分探讨了这两种类型的查询。
带有LIMIT的基本SELECT语句
有限的选择查询遵循以下基本语法:
SELECT fieldA as fa, fieldB as fb, fieldC as fc FROM tableA WHERE fieldC = 'term1 term2' ORDER BY fa desc LIMIT 100我们在这个示例中已经介绍了许多语法选项,因此让我们来看看下面可能出现的情况。
WHERE子句和布尔谓词
WHERE子句必须在谓词的一侧有一个字段。两个常量(5 < 10)或两个字段(fielda > fieldb)不被支持。子查询也不受支持。
该WHERE子句允许将Solr的搜索语法注入到SQL查询中。在这个例子中:
WHERE fieldC = 'term1 term2'上面的谓词将对 fieldC 中的短语“term1 term2”执行全文搜索。
要执行非短语查询,只需在单引号内添加括号。例如:
WHERE fieldC = '(term1 term2)'上面的谓词在 fieldC 中搜索 term1 或 term2。
Solr 范围查询语法可按如下方式使用:
WHERE fieldC = '[0 TO 100]'复杂的布尔查询可以如下指定:
WHERE ((fieldC = 'term1' AND fieldA = 'term2') OR (fieldB = 'term3'))要指定NOT查询,请使用以下AND NOT语法:
WHERE (fieldA = 'term1') AND NOT (fieldB = 'term2')支持的WHERE运算符
并行SQL接口支持并推送大多数常见的SQL操作符,具体为:
| 操作符 | 描述 | 示例 | Solr查询 |
|---|---|---|---|
|
= |
等于 |
|
|
|
<> |
不相等 |
|
|
|
!= |
不相等 |
|
|
|
> |
大于 |
|
|
|
> = |
大于或等于 |
|
|
|
< |
小于 |
|
|
|
<= |
小于或等于 |
|
|
一些不支持的运算符是:BETWEEN、LIKE 和 IN。但是,有BETWEEN和LIKE的解决方法。
- BETWEEN可以用范围查询来支持,比如:field = [50 TO 100]。
- 一个简单的LIKE可以和通配符一起使用,比如:field = 'sam*'。
ORDER BY子句
该ORDER BY子句直接映射到Solr字段。支持多个ORDER BY字段和方向。
在指定了限制的查询中,score 字段在ORDER BY子句中被接受。
如果ORDER BY子句包含GROUP BY子句中的确切字段,则对返回的结果没有限制。如果ORDER BY子句包含与GROUP BY子句不同的字段,则会自动应用100的限制。要增加此限制,您必须在LIMIT子句中指定一个值。
按字段排序区分大小写。
LIMIT子句
将结果集限制为指定的大小。在上面的例子中,该LIMIT 100子句将结果集限制为100条记录。
有限和无限查询之间有一些区别需要注意:
- 有限的查询支持字段列表和ORDER BY中的score。无限制的查询不支持。
- 有限的查询允许在字段列表中存储任何字段。无限的查询需要将这些字段存储为DocValues字段。
- 有限的查询允许ORDER BY列表中的任何索引字段。无限的查询需要将这些字段存储为DocValues字段。
SELECT DISTINCT查询
SQL接口支持SELECT DISTINCT查询的MapReduce和Facet实现。
MapReduce实现将元组混合到执行Distinct操作的工作节点。这个实现可以在极高的基数字段上执行不同的操作。
Facet实现使用JSON Facet API将Distinct操作下推到搜索引擎中。此实现旨在针对低到中等基数字段的高性能、高QPS情况。
该aggregationMode参数在JDBC驱动程序和HTTP接口中均可用于选择底层实现(map_reduce 或 facet)。这两个实现的SQL语法是相同的:
SELECT distinct fieldA as fa, fieldB as fb FROM tableA ORDER BY fa desc, fb desc统计
SQL接口支持在数字字段上计算简单的统计信息。支持的函数是:count(*),min,max,sum和avg。
由于这些函数从不需要对数据进行混洗,所以聚合被下推到搜索引擎中,并由StatsComponent生成。
SELECT count(*) as count, sum(fieldB) as sum FROM tableA WHERE fieldC = 'Hello'GROUP BY聚合
SQL接口也支持GROUP BY聚合查询。
与SELECT DISTINCT查询一样,SQL接口同时支持MapReduce实现和Facet实现。MapReduce实现可以在极高的基数域上构建聚合。Facet实现提供了在基数适中的字段上的高性能聚合。
基本GROUP BY与聚合
以下是请求聚合的GROUP BY查询的基本示例:
SELECT fieldA as fa, fieldB as fb, count(*) as count, sum(fieldC) as sum, avg(fieldY) as avg FROM tableA WHERE fieldC = 'term1 term2'
GROUP BY fa, fb HAVING sum > 1000 ORDER BY sum asc LIMIT 100让我们把它分解成下面的几个部分:
列标识符和别名
列标识符可以包含Solr索引和聚合函数中的两个字段。受支持的聚合函数是:
- count(*):统计一组 buckets 中的记录数。
- sum(field):对一组 buckets 上的数值字段求和。
- avg(field):在一组 buckets 的数值字段进行平均值。
- min(field):通过一组 buckets 返回数值字段的最小值。
- max:(field):返回一个数字在一组 buckets 上的最大数值。
字段列表中的非函数字段决定了计算聚合的字段。
GROUP BY子句最多可以包含Solr索引中的4字段。这些字段应该与字段列表中的非函数字段相对应。
HAVING子句
HAVING子句可能包含在字段列表中列出的任何函数。这样的复杂HAVING子句被支持:
SELECT fieldA, fieldB, count(*), sum(fieldC), avg(fieldY)
FROM tableA
WHERE fieldC = 'term1 term2'
GROUP BY fieldA, fieldB
HAVING ((sum(fieldC) > 1000) AND (avg(fieldY) <= 10))
ORDER BY sum(fieldC) asc
LIMIT 100最佳实践
单独的集合
为/sql处理程序创建一个单独的SolrCloud集合是有意义的。这个集合可以使用SolrCloud的标准集合API创建。
由于此集合仅用于处理/sql请求并提供工作节点池,因此此集合不需要保存任何数据。Worker 节点是从/sql处理程序集合中的整个可用节点池中随机选择的。所以为了增加这个集合动态副本可以被添加到现有的分片。新副本将在添加完成后自动启用。
并行SQL查询
前面的部分描述了SQL接口如何将SQL语句转换为流表达式。请求的参数之一是:aggregationMode,它定义查询是否应该使用类似 MapReduce 的混洗技术或将操作向下推入搜索引擎。
并行SQL查询组成
并行SQL体系结构由三个逻辑层组成:一个SQL层,一个工作层和一个数据表层。默认情况下,SQL和工作层将折叠到相同的物理SolrCloud集合中。
SQL层
SQL层是/sql处理程序所在的位置。该/sql处理程序采用SQL查询,然后将其转换为并行查询计划。然后选择要执行计划的工作节点,并将查询计划发送到要并行运行的每个工作节点。
一旦工作节点执行了查询计划,/sql处理程序就会执行工作节点返回的元组的最终合并。
工作层
工作层中的工作从/sql处理程序接收查询计划并执行并行查询计划。并行执行计划包括需要在数据表层上进行的查询和满足查询所需的关系代数。分配给查询的每个工作节点都从数据表中从元组的 1/N 中被打乱。工作节点将查询计划和流元组执行回工作节点。
数据表层
数据表层是表所在的位置。每个表都是自己的SolrCloud集合。数据表层接收来自工作节点的查询并发出元组(搜索结果)。数据表层也处理发送给工作层的元组的初始排序和分区。这意味着元组总是在攻击网络之前进行排序和分区。分区的元组以正确的排序顺序直接发送到正确的工作节点,随时可以减少。
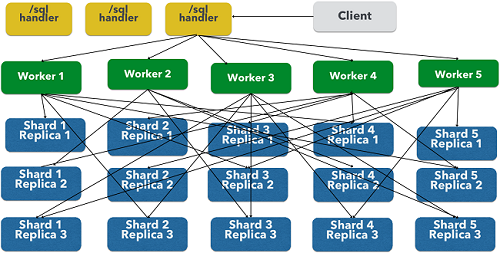
上面的图显示了三个层次,它们被分成不同的SolrCloud集合的三个层。实际上,/sql处理程序和工作者集合默认共享相同的集合。
注意:该图显示了单个并行SQL查询(基于MapReduce的SQL)的网络流。此map_reduce聚合模式用于GROUP BY聚合或SELECT DISTINCT查询时使用此网络流。当使用facet聚合模式时,使用传统的SolrCloud网络流(不含工作)。
以下是流程的描述:
- 客户端将SQL查询发送到/sql处理程序。请求由单个/sql处理程序实例处理。
- 该/sql处理器解析SQL查询,并创建并行查询计划。
- 查询计划发送到工作节点(绿色)。
- 工作节点并行执行计划。该图显示了每个联系数据表层(蓝色)中的集合的工作节点。
- 数据表层中的集合是SQL查询中的表。请注意,该集合有五个分别具有3个副本的分片。
- 请注意,每个worker联系每个分片的一个副本。因为有5个worker,每个worker从每个碎片返回1/5的搜索结果。分区是在数据表层中完成的,因此网络中没有数据的重复。
- 另外请注意,在这个设计中,数据层中的所有副本都在同时对数据进行混洗(排序和分区)。随着碎片,副本和worker数量的增长,这种设计可以将大量计算能力应用于单个查询。
- 工作节点并行处理从数据表层返回的元组。工作节点执行满足查询计划所需的关系代数。
- 工作节点将元组流回到最终合并完成的/sql处理程序中,最后将元组流回到客户端。
SQL客户端和数据库可视化工具
SQL接口支持从SQL客户端和数据库可视化工具(如DbVisualizer和Apache Zeppelin)发送的查询。
通用客户端
对于大多数基于Java的客户端,需要将以下jar包放在客户端类路径中:
- 所有.jars在 $SOLR_HOME/dist/solrj-libs 中找到
- SolrJ .jar 在 $SOLR_HOME/dist/solr-solrj-<version>.jar 被发现
如果您使用的是Maven,那么这个org.apache.solr.solr-solrj工件包含所需的jar。
一旦jarpath在类路径中可用,Solr JDBC驱动程序名称就是:org.apache.solr.client.solrj.io.sql.DriverImpl,并且可以使用以下连接字符串格式进行连接:
jdbc:solr://SOLR_ZK_CONNECTION_STRING?collection=COLLECTION_NAME还有其他的参数可以选择性地添加到连接字符串中,例如aggregationMode和numWorkers。
DBVisualizer
在Solr JDBC - DbVisualizer部分提供了设置DbVisualizer的分步指南。
SQuirreL SQL
有关设置SQuirreL SQL的分步指南,请参见Solr JDBC - SQuirreL SQL。
Apache Zeppelin
有关设置Apache Zeppelin的分步指南,请参见Solr JDBC - Apache Zeppelin。
Python/Jython
Solr JDBC - Python / Jython部分提供了使用Python和Jython连接Solr和Solr JDBC驱动程序的示例。
R
Solr JDBC-R部分提供了使用R连接到Solr和Solr JDBC驱动程序的示例。