CodeGeeX4-ALL-9B评测结果:性能卓越的代码生成模型
评测结果
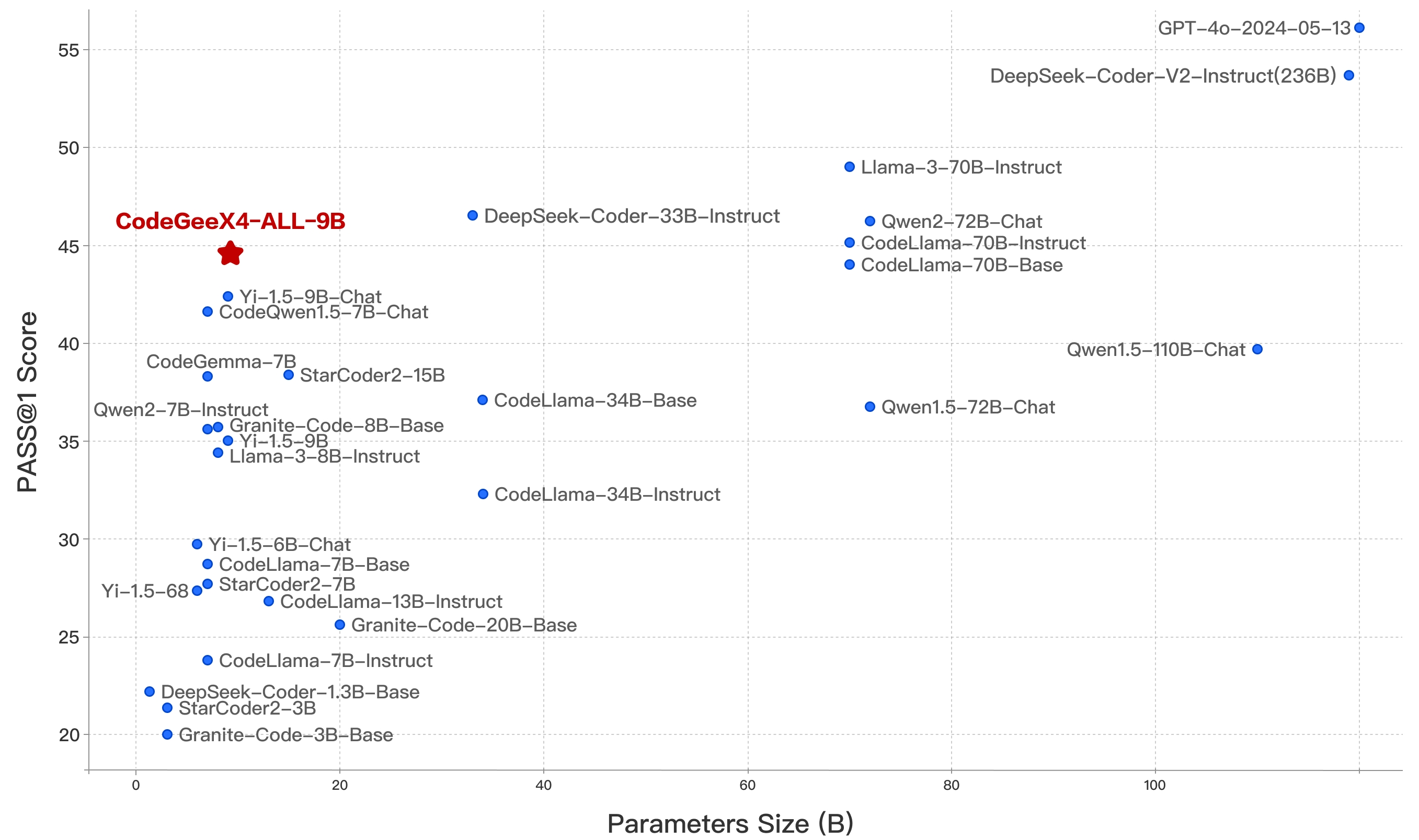
CodeGeeX4-ALL-9B 被评为参数量100 亿内的最强模型,甚至超越了参数量大几倍的通用模型,在推理性能和模型能力之间达到了最佳效果。
点击图片可查看完整电子表格
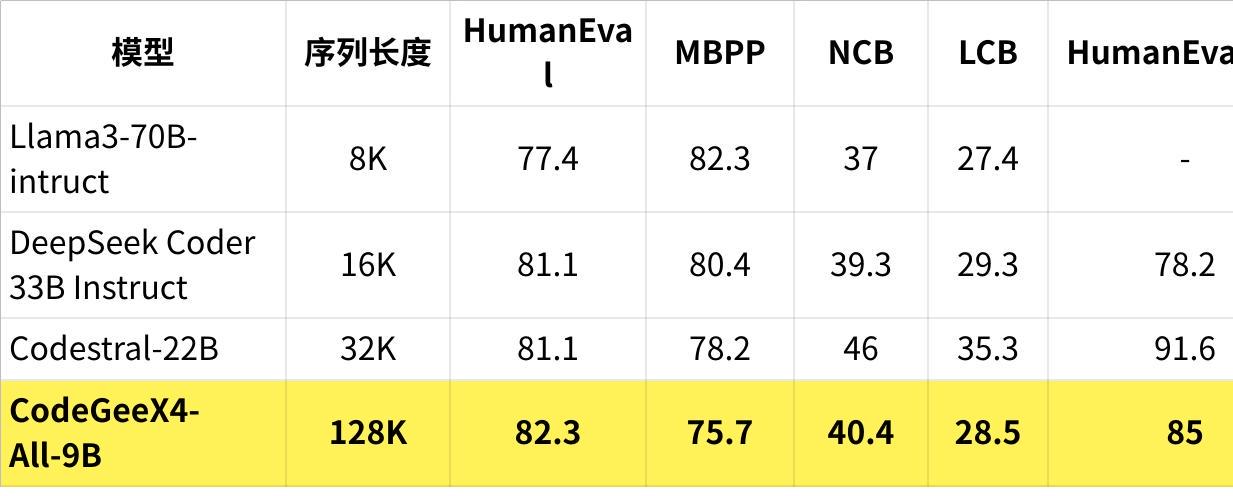
在 BigCodeBench 的 complete 和 instruct 任务中,CodeGeeX4-ALL-9B 分别取得了 48.9 和 40.4 的高分,这在参数量 200 亿内的模型中是最高的分数。
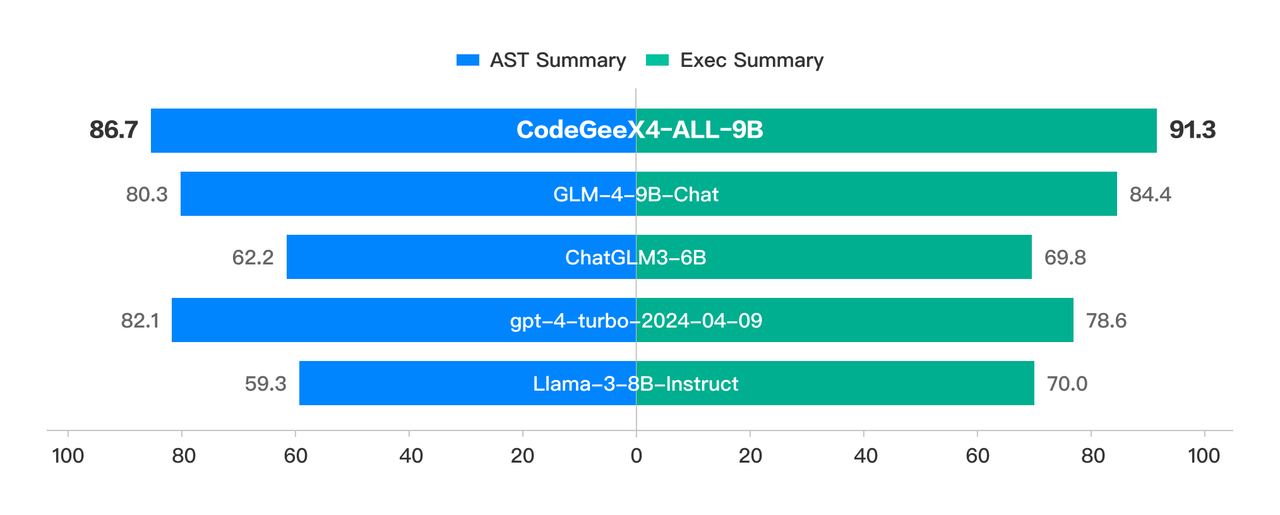
NaturalCodeBench测试结果显示,CodeGeeX4-ALL-9B在代码补全、代码解释器、代码问答、代码翻译、代码修复等任务上均取得了最佳效果:

Crux-Eval 是测试代码推理、理解和执行能力的基准测试,借助于其强大的 COT 能力,CodeGeeX4-ALL-9B 展现出色的表现。在 HumanEval、MBPP 和 NaturalCodeBench 等代码生成任务中,CodeGeeX4-ALL-9B 也取得了出色的成绩。目前,它是唯一支持 Function Call 功能的代码模型,甚至取得了比 GPT-4 更高的分数。
CodeGeeX4-ALL-9B上下文处理能力达到了128K
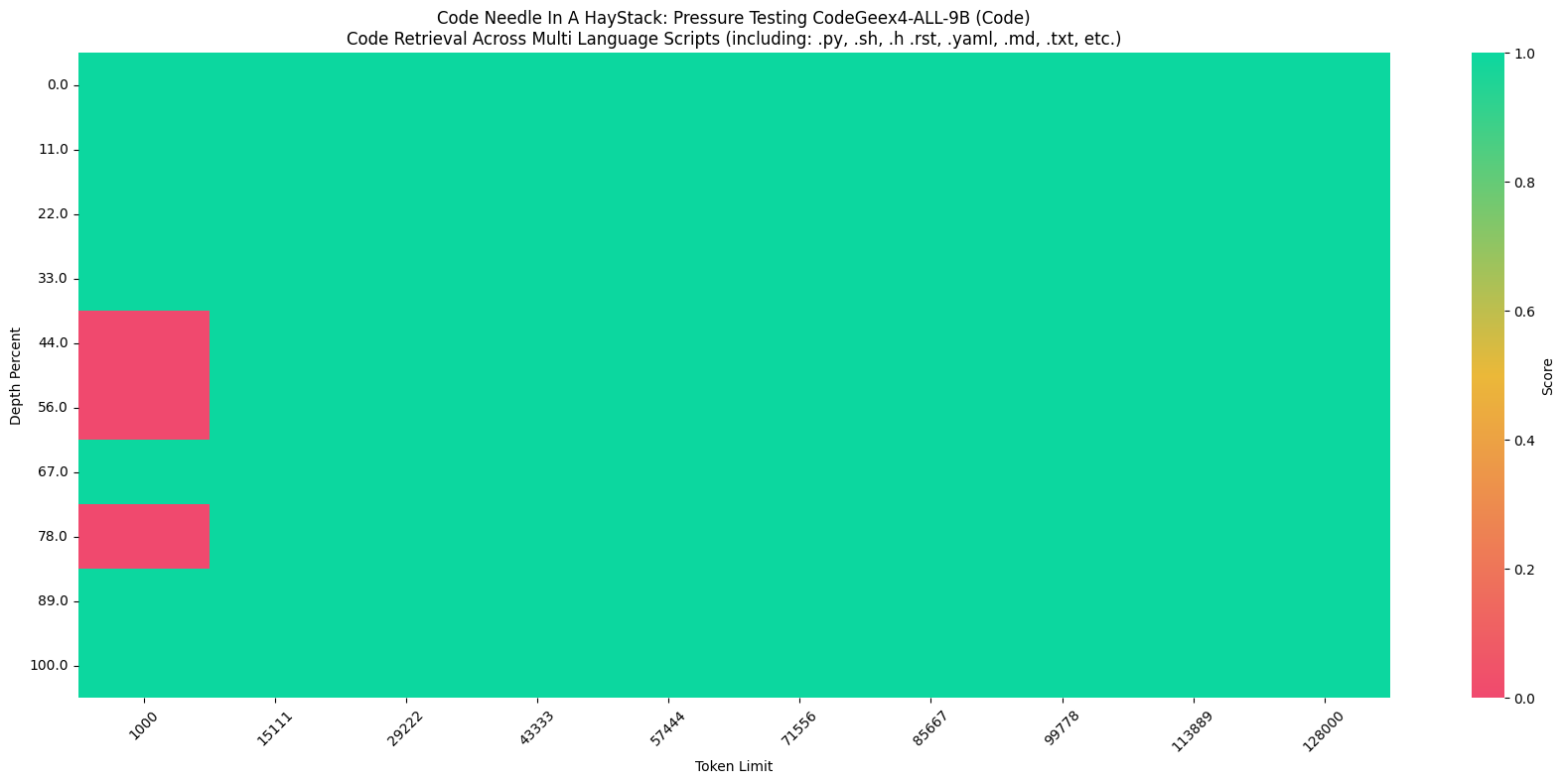
在“Code Needle In A Haystack” (NIAH) 评估中,CodeGeeX4-ALL-9B 模型展示了在 128K 范围内检索代码的能力,在python语言环境达到了 100% 的检索准确率,并在跨文件补全任务中表现出色。

|
|
上图展示的是在一个全部由Python代码组成的测试集中,插入一个赋值语句如:
zhipu_codemodel = "codegeex"(Needle),测试模型是否可以正确回答出zhipu_codemodel的值,CodeGeeX4-ALL-9B 100%完成任务。
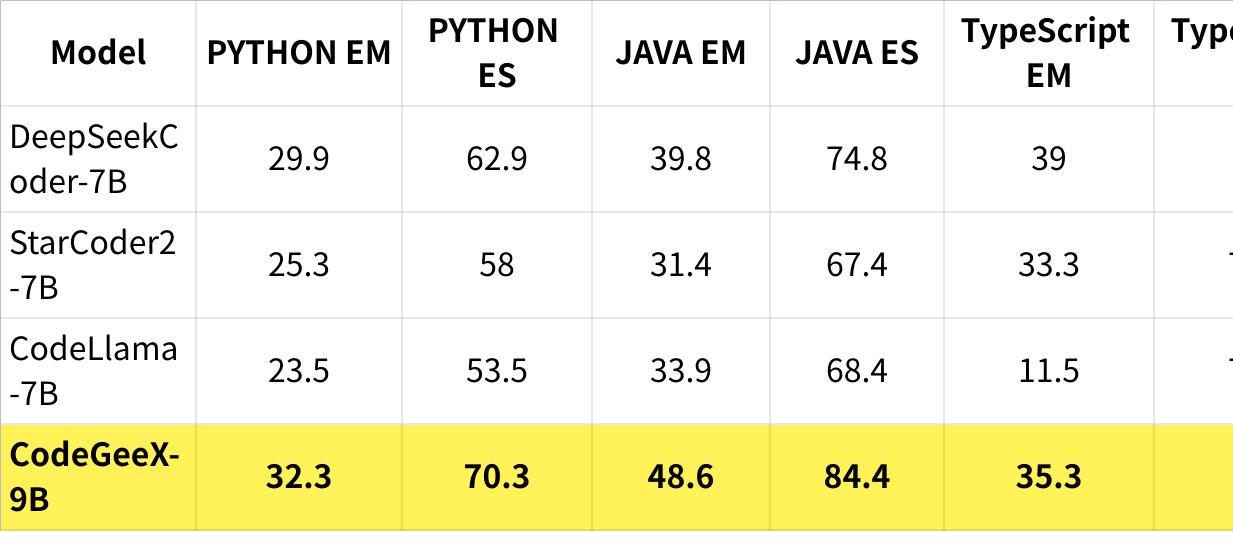
Cross-File Evaluation是一个多语言的基准,建立在Python、Java、TypeScript和C#的多样化真实仓库之上。它使用基于静态分析的方法,严格要求跨文件上下文以实现准确的代码补全。
点击图片可查看完整电子表格
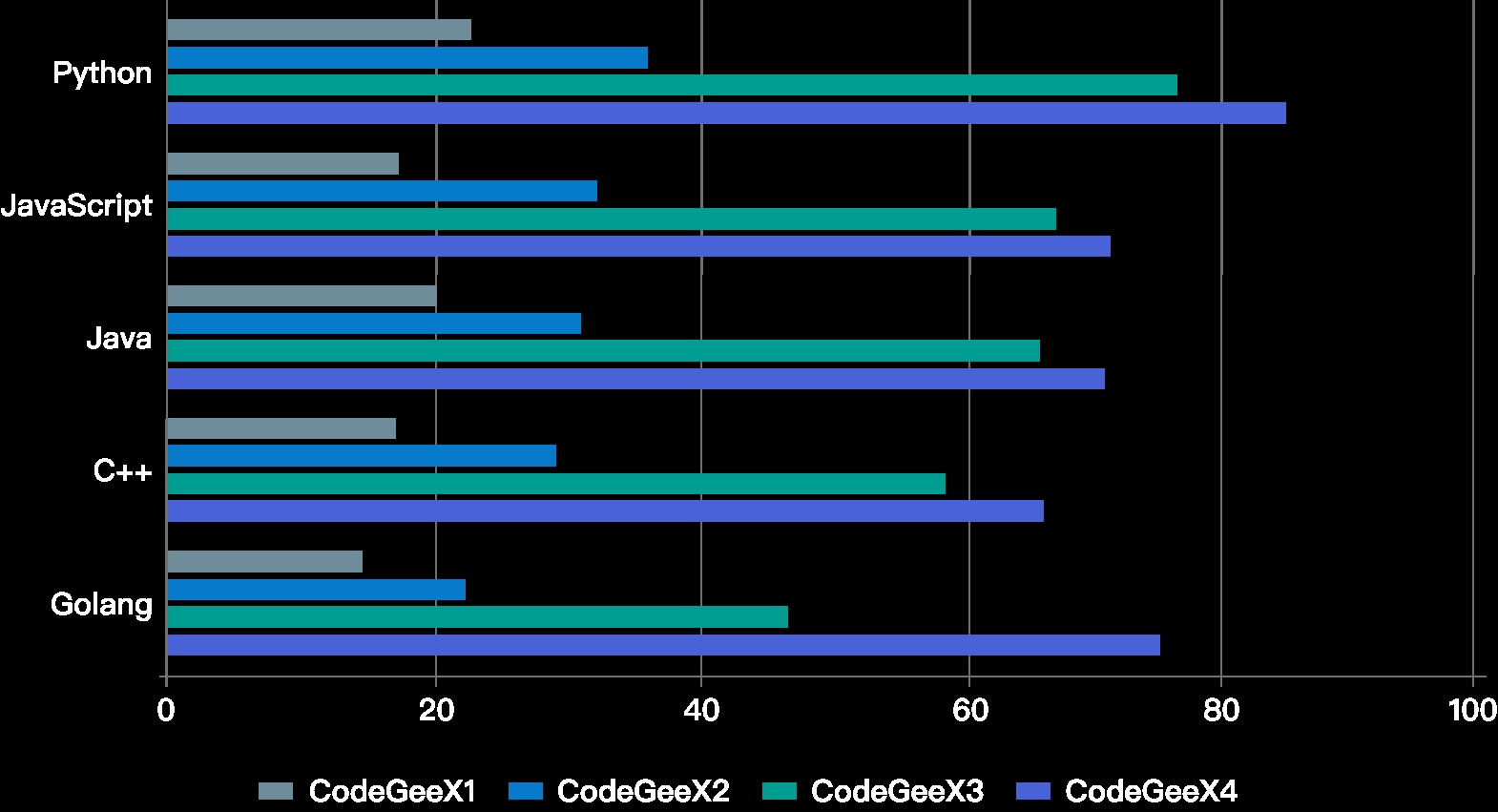
在主流编程语言的效果评测上,CodeGeeX4代模型相比上一代模型优化效果明显。