AI人工智能 生成单音音频信号
到目前为止您看到的两个步骤对于学习信号非常重要。现在,如果您想生成具有一些预定义参数的音频信号,这一步将非常有用。请注意,这一步会将音频信号保存到输出文件中。
示例
在以下示例中,我们将使用 Python 生成一个单音信号,并将其存储在文件中。为此,您需要执行以下步骤:
导入必要的包,如下所示:
import numpy as np
import matplotlib.pyplot as plt
from scipy.io.wavfile import write提供输出文件的保存路径:
output_file = 'audio_signal_generated.wav'现在,指定您选择的参数,如下所示:
duration = 4 # 秒
frequency_sampling = 44100 # Hz
frequency_tone = 784
min_val = -4 * np.pi
max_val = 4 * np.pi在这一步中,我们可以生成音频信号,如下所示:
t = np.linspace(min_val, max_val, duration * frequency_sampling)
audio_signal = np.sin(2 * np.pi * frequency_tone * t)现在,将音频文件保存到输出文件中:
write(output_file, frequency_sampling, audio_signal.astype(np.int16))提取前 100 个值用于绘制图表:
audio_signal = audio_signal[:100]
time_axis = 1000 * np.arange(0, len(audio_signal), 1) / float(frequency_sampling)现在,可视化生成的音频信号:
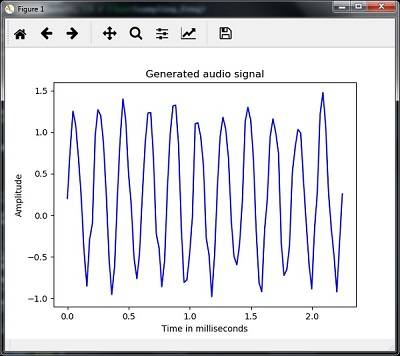
plt.plot(time_axis, audio_signal, color='blue')
plt.xlabel('Time in milliseconds')
plt.ylabel('Amplitude')
plt.title('Generated audio signal')
plt.show()您可以观察到如下所示的图表: