
AI人工智能 分类器的性能评估
实现机器学习算法后,我们需要评估模型的有效性,评估标准取决于数据集和评估指标。选择合适的评估指标至关重要,因为它直接决定了模型性能的衡量和对比方式。以下是常用的分类器性能评估指标:
混淆矩阵
混淆矩阵适用于二分类或多分类问题,是衡量分类器性能最直观的方法。它是一个二维表格,两个维度分别为真实标签和预测标签,表格中的核心元素包括:真阳性(TP)、真阴性(TN)、假阳性(FP)、假阴性(FN)。

二分类问题的混淆矩阵结构(1为正类,0为负类):
| 预测标签\真实标签 | 1(正类) | 0(负类) |
|---|---|---|
| 1(正类) | 真阳性(TP) | 假阳性(FP) |
| 0(负类) | 假阴性(FN) | 真阴性(TN) |
各元素的定义:
- 真阳性(TP):真实标签为 1,预测标签也为 1;
- 真阴性(TN):真实标签为 0,预测标签也为 0;
- 假阳性(FP):真实标签为 0,预测标签为 1(第一类错误);
- 假阴性(FN):真实标签为 1,预测标签为 0(第二类错误)。
准确率(Accuracy)
混淆矩阵本身并非性能指标,但几乎所有性能指标都基于它计算。准确率是指模型正确预测的样本数占总样本数的比例,计算公式为:
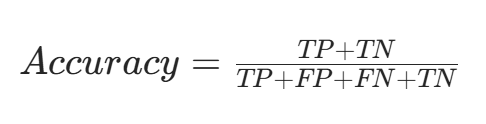
$$Accuracy = \frac{TP+TN}{TP+FP+FN+TN}$$
精确率(Precision)
精确率主要用于文档检索等场景,指预测为正类的样本中,真实为正类的比例,计算公式为:
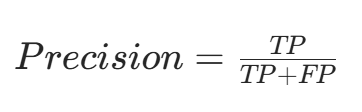
$$Precision = \frac{TP}{TP+FP}$$
召回率/灵敏度(Recall/Sensitivity)
召回率(又称灵敏度)指真实为正类的样本中,被模型预测为正类的比例,计算公式为:
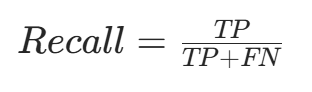
$$Recall = \frac{TP}{TP+FN}$$
特异性(Specificity)
特异性与召回率相反,指真实为负类的样本中,被模型预测为负类的比例,计算公式为:
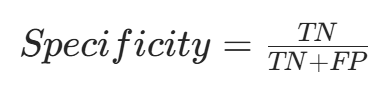
$$Specificity = \frac{TN}{TN+FP}$$