AI人工智能 分块(Chunking):将数据分成块
分块是自然语言处理中用于将文本分割成称为块(chunks)的较小部分的过程。它用于识别和提取有意义的短语和结构,如名词短语或动词短语,通过将单词组合在一起。分块有助于分析句子结构,提取相关信息,并理解文本中单词之间的关系。NLTK 库提供了用于分块的工具和算法。
分块的类型如下:
向上分块(Chunking up)
在这种分块过程中,对象、事物等趋向于变得更加一般化,语言变得更加抽象。达成共识的机会更多。在这个过程中,我们放大视角(zoom out)。例如,如果我们对"汽车的用途是什么?"这个问题进行向上分块,我们可能会得到答案"运输"。
向下分块(Chunking down)
在这种分块过程中,对象、事物等趋向于变得更加具体,语言变得更加深入。在向下分块中,会检查更深层的结构。在这个过程中,我们缩小视角(zoom in)。例如,如果我们对"具体谈谈一辆汽车?"这个问题进行向下分块,我们将获得关于这辆汽车的更小信息片段。
示例
在这个示例中,我们将使用 Python 中的 NLTK 模块进行名词短语分块(Noun-Phrase chunking),这是一种分块类别,用于在句子中查找名词短语块。
在 Python 中实现名词短语分块,请遵循以下步骤:
步骤 1 – 在此步骤中,我们需要定义分块的语法。它将包含我们需要遵循的规则。
步骤 2 – 在此步骤中,我们需要创建一个分块解析器。它将解析语法并给出输出。
步骤 3 – 在最后一步中,输出以树形格式生成。
首先导入必要的 NLTK 包:
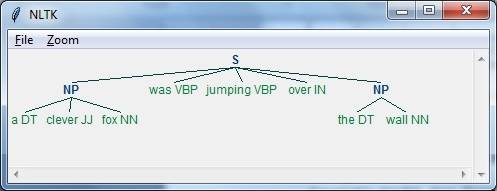
import nltk现在,我们需要定义句子。这里,DT 表示限定词(Determiner),VBP 表示动词(Verb),JJ 表示形容词(Adjective),IN 表示介词(Preposition),NN 表示名词(Noun)。
sentence=[("a","DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]现在,我们需要给出语法。这里,我们将以正则表达式的形式给出语法。
grammar = "NP:{<DT>?<JJ>*<NN>}"我们需要定义一个解析器来解析语法。
parser_chunking = nltk.RegexpParser(grammar)解析器按如下方式解析句子:
parser_chunking.parse(sentence)接下来,我们需要获取输出。输出生成在名为 output_chunk 的简单变量中。
Output_chunk = parser_chunking.parse(sentence)执行以下代码后,我们可以以树形形式绘制我们的输出:
output.draw()