
AI人工智能 K-近邻分类器
K-近邻(KNN)分类器是一种使用最近邻算法对给定数据点进行分类的分类模型。我们在上一节中已经实现了 KNN 算法,现在我们将使用该算法构建一个 KNN 分类器。
KNN 分类器的概念
K-近邻分类的基本概念是找到预定数量的训练样本(即 'k' 个)——这些样本在距离上与待分类的新样本最接近。新样本的标签将从这些邻居本身获得。KNN 分类器有一个固定的用户定义常数,用于确定邻居的数量。对于距离计算,最常用的选择是标准欧几里得距离。KNN 分类器直接作用于已学习的样本,而不是创建学习规则。KNN 算法是所有机器学习算法中最简单的之一。它在大量分类和回归问题中非常成功,例如字符识别或图像分析。
示例
我们正在构建一个 KNN 分类器来识别数字。为此,我们将使用 MNIST 数据集。我们将在 Jupyter Notebook 中编写此代码。
导入必要的包,如下所示。
这里我们从 sklearn.neighbors 包中使用 KNeighborsClassifier 模块:
from sklearn.datasets import *
import pandas as pd
%matplotlib inline
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
import numpy as np以下代码将显示数字图像,以验证我们要测试的图像:
def Image_display(i):
plt.imshow(digit['images'][i], cmap = 'Greys_r')
plt.show()现在,我们需要加载 MNIST 数据集。实际上总共有 1797 张图像,但我们使用前 1600 张图像作为训练样本,剩余的 197 张用于测试目的。
digit = load_digits()
digit_d = pd.DataFrame(digit['data'][0:1600])现在,显示图像时,我们可以看到如下输出:
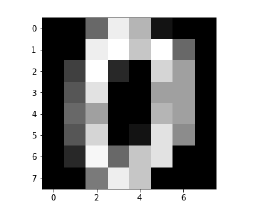
Image_display(0)Image_display(0)
数字 0 的图像显示如下:
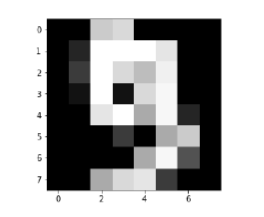
Image_display(9)
数字 9 的图像显示如下:
digit.keys()
现在,我们需要创建训练和测试数据集,并将测试数据集提供给 KNN 分类器。
train_x = digit['data'][:1600]
train_y = digit['target'][:1600]
KNN = KNeighborsClassifier(20)
KNN.fit(train_x, train_y)以下输出将创建 K 近邻分类器构造函数:
KNeighborsClassifier(algorithm = 'auto', leaf_size = 30, metric = 'minkowski',
metric_params = None, n_jobs = 1, n_neighbors = 20, p = 2,
weights = 'uniform')我们需要通过提供任意大于 1600 的数字来创建测试样本,这些是训练样本。
test = np.array(digit['data'][1725])
test1 = test.reshape(1, -1)
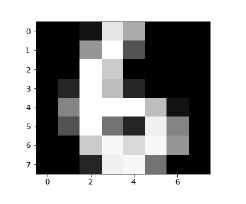
Image_display(1725)Image_display(6)
数字 6 的图像显示如下:
现在我们将预测测试数据,如下所示:
KNN.predict(test1)上述代码将生成以下输出:
array([6])现在,考虑以下内容:
digit['target_names']上述代码将生成以下输出:
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])以上内容完整翻译了 TutorialsPoint 教程中 K-Nearest Neighbors Classifier 部分的核心内容,包括 KNN 分类器的概念、原理以及使用 Python 和 scikit-learn 实现手写数字识别的完整示例代码。