
TRAE AI 编程实践:“积流成江” 的开发故事
“积流成江” (Streams to River)是一款英语学习应用,初衷是通过将日常所见的英语单词、句子和相关的上下文进行记录、提取和管理,结合艾宾浩斯遗忘曲线,进行周期性的学习和记忆。应用里包含模型对话、单词管理与复习、用户登录以及其他一些复杂的交互。本文将以 “积流成江” 的开发过程为例,介绍 TRAE 的部分核心功能。
图注:“积流成江” APP 功能的现场演示
体验地址
https://sstr.TRAE.com.cnGitHub 仓库
https://github.com/TRAE-AI/stream-to-river技术概述
“积流成江” 是一个基于 Hertz 和 Kitex 框架构建的单词学习与语言处理微服务系统。该系统提供了从 API 服务到 RPC 实现的完整解决方案, 包含用户认证、单词管理、复习进度跟踪、实时聊天、语音识别和图像转文本等核心功能模块。
系统采用前后端分离的微服务架构,主要分为以下几层:
- API 服务层:基于 Hertz 框架,提供 HTTP API 接口,处理来自前端的请求
- RPC 服务层:基于 Kitex 框架,实现业务逻辑,处理来自 API 服务层的请求
- 数据访问层:包括 MySQL 数据库和 Redis 缓存,负责数据的持久化存储和缓存
- 智能处理层:集成大语言模型 (LLM)、语音识别 (ASR) 和图像转文本等功能
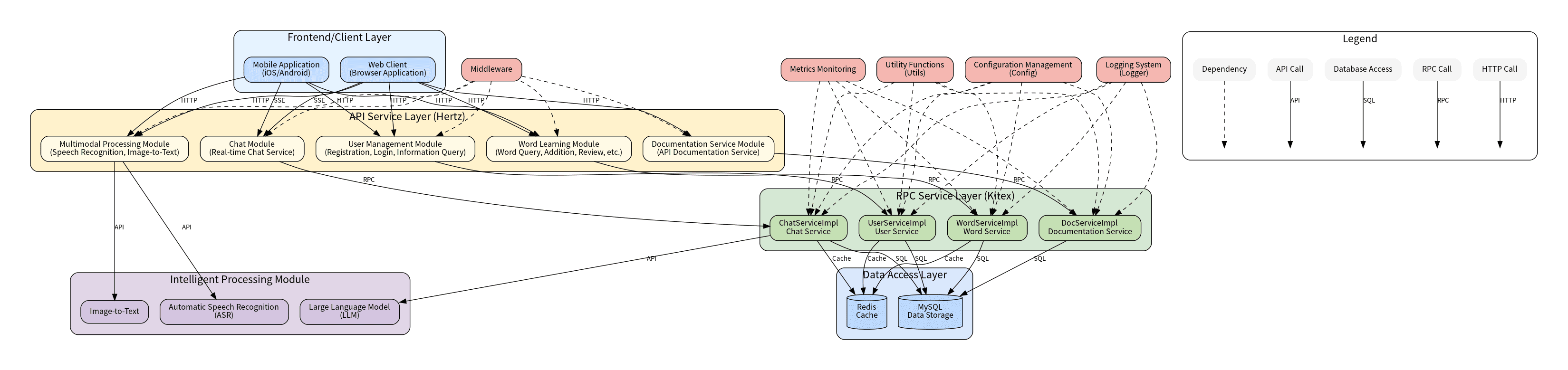
图注:系统架构图
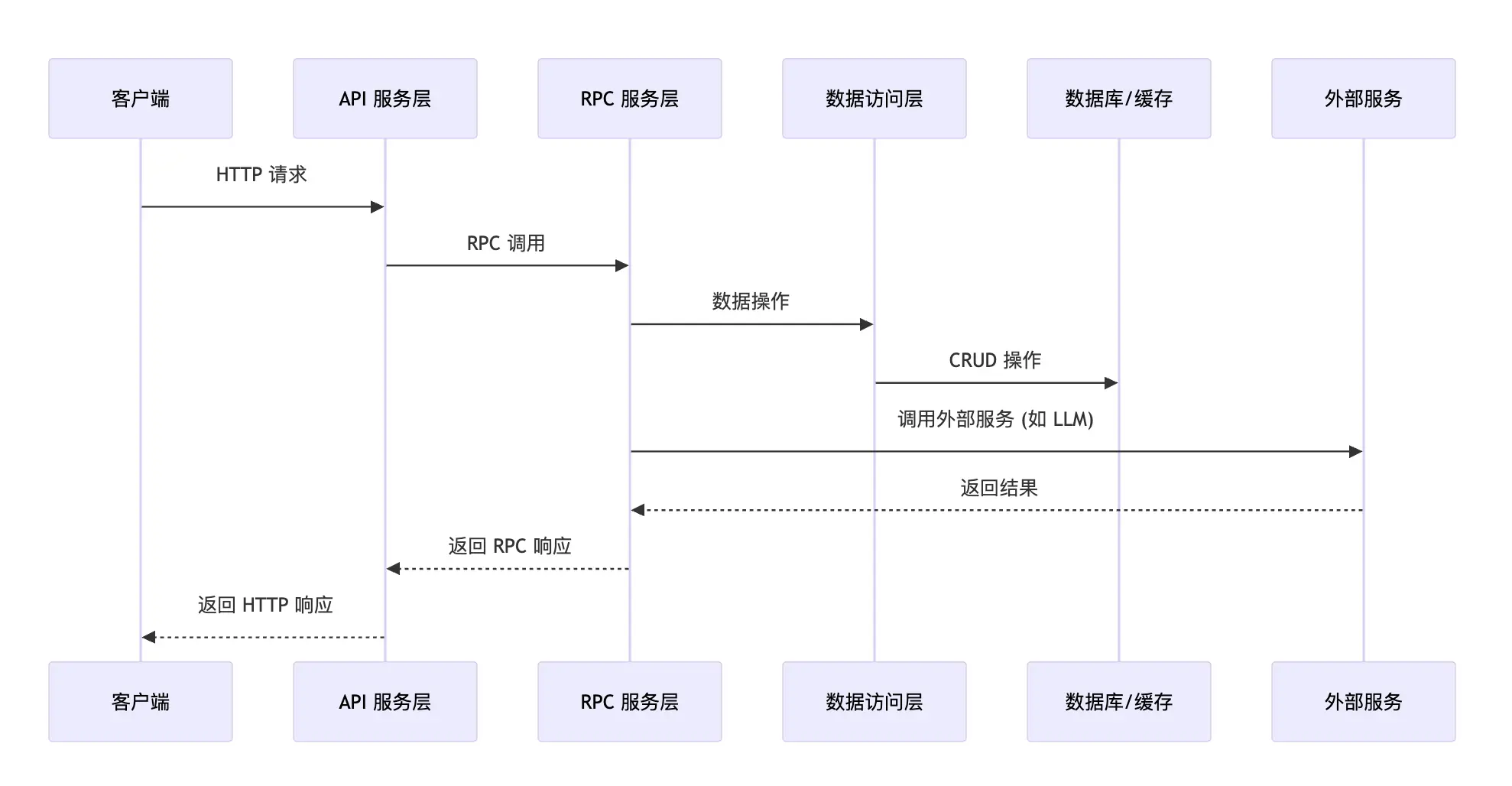
图注:组件间调用关系
开发过程
“积流成江” 约 85% 的代码由 AI 根据自然语言指令而生成。其中所使用的 TRAE 的两个基础核心功能是代码补全和局部代码生成。
TRAE 的上下文理解引擎(context understanding engine,CUE)能根据用户的编辑行为以及上下文,精准预测接下来要修改的地方,直接跳转对应位置,并持续进行代码补全和生成。代码补全和生成的效率大幅提升。详情参考《Cue》

图注:TRAE的 “修改点预测” 功能
此外,TRAE 是一个为 AI 编程量身打造的原生开发环境,不仅具备代码生成、项目导航、上下文感知等基本能力,也支持代码重构、批量修改、知识问答等复杂任务。得益于这些能力,“积流成江” 应用的开发方式与传统的手写代码方式大不相同,可以称其为自然语言编程。
当然,这里的自然语言编程,并不是一般意义上理解的,把所需功能描述一遍后,将整个开发过程完全托管给 AI 的开发方式。“积流成江” 的开发过程,仍然是典型意义上的工程师开发。除去功能描述外,更多的是编码逻辑和技术方案本身的描述。只是,这种逻辑是用自然语言,而非代码的方式呈现。
图注:”积流成江“ 开发过程演示
提示词
开发 “积流成江” 过程中所使用的提示词如下:
获取待背单词列表
接下来,实现一个获取待背单词的功能。其基本逻辑如下:
从 words_resite_record 表里面,取出当前 user(user_id 为调用者传参)的所有记录里面 next_review_time 早于当前时间的所有记录。
每一条记录,通过他们的 word_id 从 words 表里面拿到详细信息。
每条记录,生成 3 种类型的复习题目。每个题目,包含题干和 4 个答案选项。
- 第一种类型:选择正确的中文含义,实现逻辑为,题干是 words 表里面的 word_name。选项包含两部分,其中一个是 words 表里面这个单词的 explains 选项。另外从 ansswer_list 数据表里面再随机找 3 个答案。选择方法为,先从 answer_list 表里面,到 user 等于当前用户的记录中,order_id 最大的一个。然后随机从 1 到最大的 order_id 里面选 3 个 order_id,把这 3 条记录中的 description 字段作为选项。注意,还要实现一个除重逻辑。
- 第二种类型:选择正确的英文含义,可定义为常量 CHOOSE_EN。实现逻辑和上面的相似。区别为:题干是 words 表里面的 explains。选项是 answer_list 里面的 word_name。
- 第三种类型:根据读音选择正确的中文含义,可定义常量 PRONOUNCE_CHOOSE,实现逻辑也和第一个类似。区别为:题干是 words 表里面的 pronounce_us。选项是星 answer_list 里面的 description。
generateChooseQuestion 做如下优化和改进,首先 getRandomOptions 函数,在生成了 3 个随机选项之后。把当前 word_id 在 answer_ist 表里面查询到对应的 order_id,也加入到 randomOrderIds 里面,这里加入时候的顺序,可以在 1 到 4 里面做一个随机数。这样就是 4 个 order_id 了。之后的逻辑就可以进一步简化,直接 for 循环 4 次,填充数据就行。注意填充时候,Answerld 不是 word.Wordld 而是 model.AnswerList 里面的 answerld。提交答案
接下来,实现答案提交功能的 rpc 服务:
首先,上层传递的参数为三个整数:userId,wordId,answerId 和 QuestionType,我们需要从 answer_list 表里面根据 user_id 和 answer_id 取到对应记录,从 words_resite_record 表里面根据 user_id 和 word_id 取到记录。如果两个有任一没取到,返回失败。
取到数据之后,首先校验 answer_list 表取到的数据中的 wordld 和当前的 wordid 是否一直,如果一致,表示答案正确,否则答案错误。
接下来,根据回答情况更新 words_resite_record 对应记录。
- 答案正确,则 total_correct 加 1,score 的二进制第 QustionType-1 位设置为 1。更新完成之后,如果 score 的二进制 0、1、2 位都为 1,也就是 7,则表示进入下一个 Level,更新数据表里面的 level。同时,next_review_time 也进行修改,增加的时间规则使用艾宾浩斯记忆曲线。具体如下:当前 level 为 0,增加 5 分钟。level1:24小时,level2:24小时,level3:48小时,level4:48小时,level5:72小时,level6:192小时。level7 及以上:365天。不要魔鬼数字,这里可以在 global.go 里面定义常量。
- 答案错误,total_wrong 加 1,score 的二进制第 QustionType-1 位设置为 0。更新完成之后如果 score 变为 0 且之前 score 大于 0,则 level 相应减 1。同时,next_reviewtime 修改为当前时间。增加一种题目类型
在现有 3 种题型的基础上,增加一个填空题:FILL_IN_BLANK。需求为把 word_name 挖掉几个空返回。挖掉的规则是:word_name 只随机留下 1/5 的字母,其他都是空。返回的字段,增加一个 show_info,是一个 string 数组,每个元素是一个字符,其中空用 _ 表示。
修改提交部分的功能,首先 url 参数增加一个 filled_name。传给后端 service,判断是否正确的逻辑是:从 words 表中根据 word_id 取到信息,对比 filled_name 是否和表里面的 word_name 相同。相同则正确。号外,要注意,因为新增了一种类型,全部答对会从 7 变成 15。标签功能
我想实现一个新功能,现在每个题目,默认都有 4 种题型。我想做个性化功能,每个题目可以有一个标签,不同的标签,会有不同的题型组合。比如 “能看懂” 这个标签,题目类型只需要英选中和中选英。你看看怎么实现。先不要要着急写代码,把你的实现思路整理一下:包括数据表怎么设计、核心流程等。
我们实现一个标签的新功能。增加一个标签数据表,里面有标签名、题型组合这两个核心字段。每个单词,会有一个标签。题型组合是一个整数,通过二进制位运算,表示这个标签下的单词,需要复习的题目类型。比如数字为 11,代表需要的题型组合有 0、1、3,对应到 question_type 是1、2、4。然后在单词复习和答案提交的时候,都需要重新修改下逻辑。之前是默认每个题都是需要 4 种类型,满分 15 分。现在要根据单词的标签来判断需要哪些题型,以及提交答案时候满分不同标签也是不同的。复习进度接口
接下来实现一个新接口:获取今天需要的复习单词数,已经复习的的单词数。你看一下应该这么实现,先不着急写代码,思考和描述下技术方案。
接下来实现一个新接口:获取今天需要的复习单词数,已经复习的单词数。实现方案如下:新建一个数据表,记录用户复习进度信息。里面包括的字段有 user_id,待复习单词数、已复习单词数和最近一次更新时间。接口访问的时候,如果数据表中没有这个用户记录或者最近一次更新时间是在今天 00:00 之前,那么进行如下更新:实现一个 init 方法,从 words_resite_records 表里面取出 next_review_time 早于当前时间的所有记录,总数作为待复习单词数更新到数据表中,同时修改最新更新时间和待复习单词数。单词列表增加字段
接下来,给 words 这个接口增加两个返回字段:1、单词的 tag_id 2、单词的复习进度:当前等级 level,最大等级 max_level。这里的复习进度是指 words_resite_record 表里面的 level 字段。然后定义一个常量 MAX_RISITE_LEVEL作为max_level 值。增加总单词数和已复习单词数接口
reviewprogress 这个 http 接口增加两个返回值:1、总单词数,从 words 表里面 count 就行。2、已完成复习的单词数:words_risite_rocord 里面属于该用户的 level 大于等于 7 的记录数。在 rpc service 的 bizs 里面,可以单独实现一个取这两个数的方法,方便其他接口未来复用。
我感觉通过查询 words_resite_record 表中属于该用户且 level>=7 的记录数获得已完成复习单词数这个实现不太理想。每次都要扫表 count。咱们改成这样实现:在 review_progress 表里面,增加一个 all_completed_count 字段,代表已完成的单词总数。每次取这个数就行。这个数的更新方法为:在 initReviewProgress 的时候,查询 word_risite_record 表更新。每次提交答案的时候,如果 level 发生了变化并且 level 达到 7,那么把总数再加一。添加索引
把 dal 层代码仔细读一遍,看看需要给数据库添加哪些索引。分析一下并给出加某个索引的原因。