
OceanBase 基于规则的路径选择
本文主要介绍 OceanBase 数据库路径选择的规则体系。
目前 OceanBase 数据库路径选择的规则体系分为前置规则(正向规则)和 Skyline 剪枝规则(反向规则)。前置规则直接决定了一个查询使用什么样的索引,是一个强匹配的规则体系。
Skyline 剪枝规则会比较两个索引,如果一个索引在一些定义的维度上优于(dominate)另外一个索引,那么不优的索引会被剪掉,最后没有被剪掉的索引会进行代价比较,从而选出最优的计划。
目前 OceanBase 数据库的优化器会优先使用前置规则选择索引,如果没有匹配的索引,那么 Skyline 剪枝规则会剪掉一些不优的索引,最后代价模型会在没有被剪掉的索引中选择代价最低的路径。
如下例所示,OceanBase 数据库的计划展示中会输出相应的路径选择的规则信息。
obclient>CREATE TABLE t1(a INT PRIMARY KEY, b INT, c INT, d INT, e INT,
UNIQUE INDEX k1(b), INDEX k2(b,c), INDEX k3(c,d));
Query OK, 0 rows affected (0.38 sec)
obclient> EXPLAIN EXTENDED SELECT * FROM t1 WHERE b = 1;
+-----------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------+
| =====================================
|ID|OPERATOR |NAME |EST. ROWS|COST|
-------------------------------------
|0 |TABLE SCAN|t1(k1)|2 |94 |
=====================================
Outputs & filters:
-------------------------------------
0 - output([t1.a(0x7f3178058bf0)], [t1.b(0x7f3178058860)], [t1.c(0x7f3178058f80)], [t1.d(0x7f3178059310)], [t1.e(0x7f31780596a0)]), filter(nil),
access([t1.b(0x7f3178058860)], [t1.a(0x7f3178058bf0)], [t1.c(0x7f3178058f80)], [t1.d(0x7f3178059310)], [t1.e(0x7f31780596a0)]), partitions(p0),
is_index_back=true,
range_key([t1.b(0x7f3178058860)], [t1.shadow_pk_0(0x7f31780784b8)]), range(1,MIN ; 1,MAX),
range_cond([t1.b(0x7f3178058860) = 1(0x7f31780581d8)])
Optimization Info:
-------------------------------------
t1:optimization_method=rule_based, heuristic_rule=unique_index_with_indexback
obclient> EXPLAIN EXTENDED SELECT * FROM t1 WHERE c < 5 ORDER BY c;
+-----------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------+
| ====================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
------------------------------------
|0 |SORT | |200 |1054|
|1 | TABLE SCAN|t1 |200 |666 |
====================================
Outputs & filters:
-------------------------------------
0 - output([t1.a(0x7f3178059220)], [t1.b(0x7f31780595b0)], [t1.c(0x7f3178058e90)], [t1.d(0x7f3178059940)], [t1.e(0x7f3178059cd0)]), filter(nil), sort_keys([t1.c(0x7f3178058e90), ASC])
1 - output([t1.c(0x7f3178058e90)], [t1.a(0x7f3178059220)], [t1.b(0x7f31780595b0)], [t1.d(0x7f3178059940)], [t1.e(0x7f3178059cd0)]), filter([t1.c(0x7f3178058e90) < 5(0x7f3178058808)]),
access([t1.c(0x7f3178058e90)], [t1.a(0x7f3178059220)], [t1.b(0x7f31780595b0)], [t1.d(0x7f3178059940)], [t1.e(0x7f3178059cd0)]), partitions(p0),
is_index_back=false, filter_before_indexback[false],
range_key([t1.a(0x7f3178059220)]), range(MIN ; MAX)always true
t1:optimization_method=cost_based, avaiable_index_name[t1,k3], pruned_index_name[k1,k2]其中 optimization_method 展示了具体的规则信息,它有以下两种形式:
-
如果
optimization_method=rule_based, 那么就是命中了前置规则,同时会展示出具体命中的规则名称,unique_index_with_indexback 表示命中了前置规则的第三条规则(唯一性索引全匹配+回表+回表数量少于一定的阈值)。 -
如果
optimization_method=cost_based, 那么就是基于代价选择出来的,同时会展示出来 Skyline 剪枝规则剪掉了那些访问路径(pruned_index_name)以及剩下了那些访问路径(avaiable_index_name)。
前置规则
目前 OceanBase 数据库的前置规则只用于简单的单表扫描。因为前置规则是一个强匹配的规则体系,一旦命中,就直接选择命中的索引,所以要限制它的使用场景,以防选错计划。
目前 OceanBase 数据库根据“查询条件是否能覆盖所有索引键”和“使用该索引是否需要回表”这两个信息,将前置规则按照优先级划分成如下三种匹配类型:
-
匹配“唯一性索引全匹配+不需要回表(主键被当成唯一性索引来处理)”,则选择该索引。如果存在多个这样的索引,选择索引列数最小的一个。
-
匹配“普通索引全匹配+不需要回表”,则选择该索引。如果存在多个这样的索引,选择索引列数最小的一个。
-
匹配“唯一性索引全匹配+回表+回表数量少于一定的阈值”,则选择该索引。如果存在多个这样的索引,选择回表数量最小的一个。
这里需要注意的是,索引全匹配是指在索引键上都存在等值条件(对应于 get 或者 multi-get)。
如下示例中,查询 Q1 命中了索引 uk1(唯一性索引全匹配+不需要回表);查询 Q2 命中了索引 uk2(唯一性索引全匹配+回表+回表行数最多 4 行)。
obclient>CREATE TABLE test(a INT PRIMARY KEY, b INT, c INT, d INT, e INT,
UNIQUE KEY UK1(b,c), UNIQUE KEY UK2(c,d) );
Query OK, 0 rows affected (0.38 sec)
Q1:
obclient>SELECT b,c FROM test WHERE (b = 1 OR b = 2) AND (c = 1 OR c =2);
Q2:
obclient>SELECT * FROM test WHERE (c = 1 OR c =2) OR (d = 1 OR d = 2);Skyline 剪枝规则
Skyline 算子是学术界在 2001 年提出的一个新的数据库算子(它并不是标准的 SQL 算子)。自此之后,学术界对 Skyline 算子有大量的研究(包括语法、语义和执行等)。
Skyline 从字面上的理解是指天空中的一些边际点,这些点组成搜索空间中最优解的集合。例如要寻找价格最低并且路途最短的一家旅馆,想象一个二维空间,有两个维度,横轴表示价格,纵轴表示距离,二维空间上的每个点表示一个旅馆。
如下图所示,不论最后的选择如何,最优解肯定是在这一条天空的边际线上。假设点 A 不在 Skyline 上,那么肯定能够在 Skyline 上找到在两个维度上都比 A 更优的点 B,在这个场景中就是距离更近,价格更便宜的旅馆,称为点 B dominate A。所以 Skyline 一个重要应用场景就是用户没办法去衡量多个维度的比重,或者多个维度不能综合量化(如果可以综合量化,使用 “SQL 函数+ ORDER BY ”就可以解决了)。
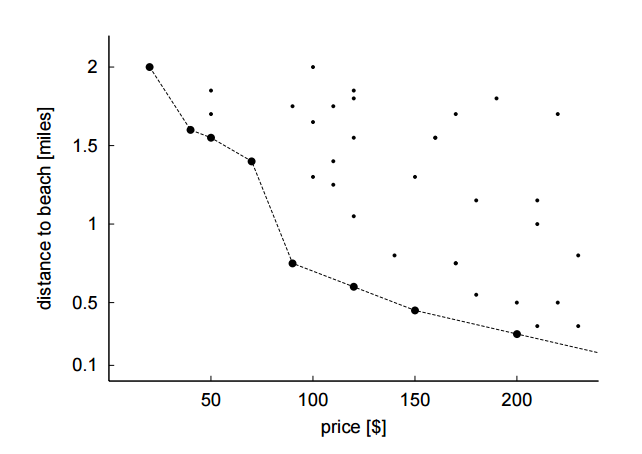
Skyline 操作是在给定对象集 O 中找出不被别的对象所 dominate 的对象集合。若一个对象 A 在所有维度都不被另一个对象 B 所 dominate,并且 A 至少在一个维度上 dominate B,则称 A dominate B。所以在 Skyline 操作中比较重要的是维度的选择以及在每个维度上的 dominate 的关系定义。假设有 N 个索引的路径 <idx_1,idx_2,idx_3...idx_n> 可以供优化器选择,如果对于查询
Q,索引 idx_x 在定义的维度上 dominate 索引 idx_y,那就可以提前把索引 idx_y 剪掉,不让它参与最终代价的运算。
维度的定义
针对 Skyline 剪枝,对每个索引(主键也是一种索引)定义了如下三个维度:
-
是否回表
-
是否存在 intersting order
-
索引前缀能否抽取 query range
通过如下示例进行分析:
obclient> CREATE TABLE skyline(
pk INT PRIMARY KEY, a INT, b INT, c INT,
KEY idx_a_b(a, b),
KEY idx_b_c(b, c),
KEY idx_c_a(c, a));
Query OK, 0 rows affected (0.09 sec)-
回表:该查询是否需要需要回查主表。
/* 走索引 idx_a_b 的话就需要回查主表,因为索引 idx_a_b 没有 c 列*/ obclient>SELECT /*+INDEX(skyline idx_a_b)*/ * FROM skyline;
-
interesting order: 考虑是否有合适的序可以利用。
/* 索引 idx_b_c 可以把 ORDER BY 语句消除*/ obclient>SELECT pk, b FROM skyline ORDER BY b;
-
索引前缀能否抽取 query range。
/*可以看到走索引 idx_c_a 就可以快速定位到需要的行的范围,不用全表扫描*/ obclient>SELECT pk, b FROM skyline WHERE c > 100 AND c < 2000;
基于这三个维度,定义了索引之间的 dominate 关系,如果索引 A 在三个维度上都不比索引 B 差,并且其中至少有一个维度比 B 好,那么就可以直接把 B 索引剪掉,因为基于索引 B 最后生成的计划肯定不会比索引 A 好。
-
如果索引 idx_A 不需要回表,而索引 idx_B 需要回表,那么在这个维度上索引 idx_A dominate idx_B。
-
如果在索引 idx_A上抽取出来的 intersting order 是向量
Va<a1, a2, a3 ...an>, 在索引 idx_B 上抽出来的interesting order 是向量Vb<b1, b2, b3...bm>, 如果n > m, 并且对于ai = bi (i=1..m), 那么在这个维度上索引 idx_A dominate idx_B。 -
如果在索引 idx_A 能用来抽取的 query range 的列集合是
Sa<a1, a2, a3 ...an>,在索引 idx_B 上能用来抽取 query range 的列集合是Sb <b1, b2, b3...bm>, 如果 Sa 是 Sb 的 super set, 那么在这个维度上索引 idx_A dominate idx_B。
回表
这个维度初看比较简单,就是查询所需列是否在索引中。其中,一些案例需要特殊考虑,例如当主表和索引表都没有 interesting order 和抽取不了 query range 的情况下,直接走主表不一定是最优解。
obclient>CREATE TABLE t1(
pk INT PRIMARY KEY, a INT, b INT, c INT, v1 VARCHAR(1000),
v2 VARCHAR(1000), v3 VARCHAR(1000), v4 VARCHAR(1000),INDEX idx_a_b(a, b));
Query OK, 0 rows affected (0.09 sec)
obclient>SELECT a, b,c FROM t1 WHERE b = 100;|
索引 |
Index Back |
Interesting Order |
Query Range |
|---|---|---|---|
|
primary |
no |
no |
no |
|
idx_a_b |
yes |
no |
no |
主表很宽,而索引表很窄,虽然从维度上主表 dominate 索引 idx_a_b,然而,索引扫描加回表的代价不一定会比主表全表扫描来的慢。简单来说,索引表可能只需要读一个宏块,而主表可能需要十个宏块。这种情况下,需要对规则做一些放宽,考虑具体的过滤条件。
Interesting Order
优化器通过 Interesting Order 利用底层的序,就不需要对底层扫描的行做排序,还可以消除 ORDER BY,进行 MERGE GROUP BY,提高 Pipeline(不需要进行物化)等。
obclient>CREATE TABLE skyline(
pk INT PRIMARY KEY, v1 INT, v2 INT, v3 INT, v4 INT, v5 INT,
KEY idx_v1_v3_v5(v1, v3, v5),
KEY idx_v3_v4(v3, v4));
Query OK, 0 rows affected (0.10 sec)
obclient>CREATE TABLE tmp (c1 INT PRIMARY KEY, c2 INT, c3 INT);
Query OK, 0 rows affected (0.06 sec)
obclient>(SELECT DISTINCT v1, v3 FROM skyline JOIN tmp WHERE skyline.v1 = tmp.c1
ORDER BY v1, v3) UNION (SELECT c1, c2 FROM tmp);
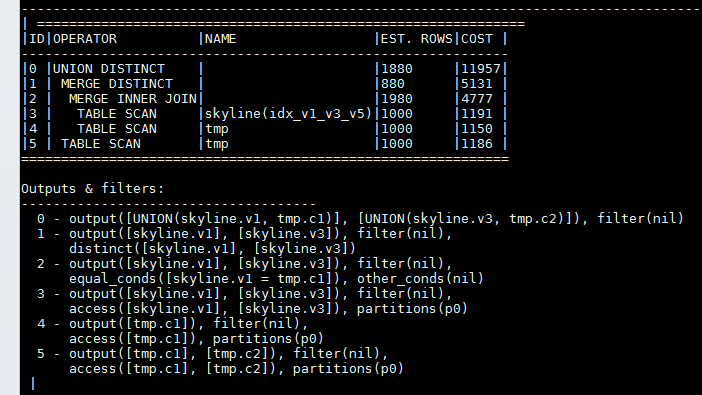
从执行计划可以看到,ORDER BY 被消除了,同时使用了 MERGE DISTINCT,UNION 也没有做 SORT。可以看到,从底层 TABLE SCAN 吐出来的序,可以被上层的算子使用。换句话说,保留 idx_v1_v3_v5 吐出来的行的顺序,可以让后面的算子在保序的情况下执行更优的操作。优化器在识别这些序的情况下,才能生成更优的执行计划。
所以 Skyline 剪枝对 interesting order 的判断,需要充分考虑各个索引能够最大利用的序。例如上述最大的序其实是 v1,v3 而不仅仅是 v1,它从 MERGE JOIN 吐出来的序(v1, v3) 可以到 MERGE DISINCT 算子, 再到最后的 UNISON DISTINCT 算子。
Query Range
Query range 的抽取可以方便底层直接根据抽取出来的 range 定位到具体的宏块,而从减少存储层的 IO。
例如 SELECT * FROM t1 WHERE pk < 100 AND pk > 0 就可以直接根据一级索引的信息定位到具体的宏块,加速查询,越精确的 query range 能够让数据库扫描更少的行。
obclient> CREATE TABLE t1 (
pk INT PRIMARY KEY, a INT, b INT,c INT,
KEY idx_b_c(b, c),
KEY idx_a_b(a, b));
Query OK, 0 rows affected (0.12 sec)
obclient>SELECT b FROM t1 WHERE a = 100 AND b > 2000;对于索引 idx_b_c 它能抽出 query range 的索引前缀是 (b),对于索引 idx_a_b 它能抽出 query range 的索引前缀是 (a, b),所以在这个维度上,索引 idx_a_b dominate idx_b_c。
综合举例
obclient>CREATE TABLE skyline(
pk INT PRIMARY KEY, v1 INT, v2 INT, v3 INT, v4 INT, v5 INT,
KEY idx_v1_v3_v5(v1, v3, v5),
KEY idx_v3_v4(v3, v4));
Query OK, 0 rows affected (0.10 sec)
obclient>CREATE TABLE tmp (c1 INT PRIMARY KEY, c2 INT, c3 INT);
Query OK, 0 rows affected (0.06 sec)
obclient>SELECT MAX(v5) FROM skyline WHERE v1 = 100 AND v3 > 200 GROUP BY v1;|
索引 |
Index Back |
Interesting order |
Query range |
|---|---|---|---|
|
primary |
Not need |
No |
No |
|
idx_v1_v3_v5 |
Not need |
(v1) |
(v1, v3) |
|
idx_v3_v4 |
Need |
No |
(v3) |
可以看到索引 idx_v1_v3_v5 在三个维度上都不比主键索引或索引 idx_v3_v4 差。所以在规则系统下,会直接剪掉主键索引和索引 idx_v3_v4。维度的合理定义,决定了 Skyline 剪枝是否合理。错误的维度,将会导致该索引提前被剪掉,从而导致永远生成不了最优的计划。