
OceanBase SELECT
SELECT 的语法相对比较复杂。本节首先会介绍 SIMPLE SELECT 语法结构,然后介绍集合类 SELECT 的语法结构,最后介绍带有 with clause 的 SELECT。
SIMPLE SELECT
描述
该语句用于查询表中的内容。
格式
simple_select:
SELECT [/*+ hint statement */] [DISTINCT | UNIQUE | ALL]
select_expr_list FROM from_list [WHERE condition]
[GROUP BY group_expression_list] [ROLLUP group_expression_list] [HAVING condition]]
[ORDER BY order_expression_list]
[FOR UPDATE [OF column] [ {NOWAIT | WAIT integer | SKIP LOCKED } ] ]
select_expr:
table_name.*
| table_alias_name.*
| expr [[AS] column_alias_name]
from_list:
table_reference [, table_reference ...]
table_reference:
simple_table
| joined_table
simple_table:
table_factor [partition_option] [[AS] table_alias_name]
| (select_stmt) [AS] table_alias_name
| (table_reference_list)
joined_table:
table_reference [INNER] JOIN simple_table [join_condition]
| table_reference outer_join_type JOIN simple_table join_condition
partition_option:
PARTITION (partition_name_list)
partition_name_list:
partition_name [, partition_name ...]
outer_join_type:
{LEFT | RIGHT | FULL} [OUTER]
join_condition:
ON expression
condition:
expression
group_expression_list:
group_expression [, group_expression ...]
group_expression:
expression [ASC | DESC]
order_expression_list:
order_expression [, order_expression ...]
order_expression:
expression [ASC | DESC]参数解释
|
参数 |
描述 |
|---|---|
|
DISTINCT | UNIQUE | ALL |
在数据库表中,可能会包含重复值。
|
|
select_expr |
列出要查询的表达式或列名,用“,”隔开。也可以用“*”表示所有列。 |
|
AS othername |
为输出字段重新命名。 |
|
FROM table_references |
指名了从哪个表或哪些表中读取数据(支持多表查询)。 |
|
WHERE where_conditions |
可选项, |
|
GROUP BY group_by_list |
按一些字段进行分组,产生统计值。 |
|
ROLLUP group_expression_list |
合并 Group By 的分组,产生统计值。 |
|
HAVING search_confitions |
|
|
ORDER BY order_list order_list : colname [ASC | DESC] [,colname [ASC | DESC]…] |
用来按升序(ASC)或者降序(DESC)显示查询结果。不指定 ASC 或者 DESC 时,默认为 ASC。 |
|
FOR UPDATE |
对查询结果所有行上排他锁,以阻止其他事务的并发修改,或阻止在某些事务隔离级别时的并发读取。
说明 SKIP LOCKED 暂不支持多表 JOIN 加锁的场景。 |
|
PARTITION(partition_list) |
指定查询表的分区信息。例如: |
示例
以如下表 a 为例。
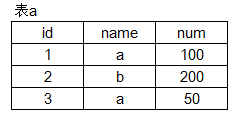
CREATE TABLE a (id INT,name VARCHAR(10),num INT);
INSERT INTO a VALUES (1, 'a',100);
INSERT INTO a VALUES (2, 'b',200);
INSERT INTO a VALUES (3, 'a',50);- 从表a中读取name数据。
obclient> SELECT name FROM a; +------+ | NAME | +------+ | a | | b | | a | +------+ 3 rows in set (0.00 sec)
- 在查询结果中对name进行去重处理。
obclient> SELECT DISTINCT name FROM a; +------+ | NAME | +------+ | a | | b | +------+ 2 rows in set (0.00 sec)
- 从表
a中查询 id、name和num,然后把num列除以 2 输出,输出的列名为avg。obclient> SELECT id, name, num/2 AS avg FROM a; +----+------+------+ | ID | NAME | AVG | +----+------+------+ | 1 | a | 50 | | 2 | b | 100 | | 3 | a | 25 | +----+------+------+ 3 rows in set (0.00 sec)
- 从表
a中根据筛选条件“ name = 'a' ”,输出对应的id 、name和num 。obclient> SELECT id, name, num FROM a WHERE name = 'a'; +----+------+------+ | ID | NAME | NUM | +----+------+------+ | 1 | a | 100 | | 3 | a | 50 | +----+------+------+ 2 rows in set (0.00 sec)
- 从表
a中查询name,按照name分组对num求和,并输出。obclient> SELECT id, name, num FROM a WHERE name = 'a'; +----+------+------+ | ID | NAME | NUM | +----+------+------+ | 1 | a | 100 | | 3 | a | 50 | +----+------+------+ 2 rows in set (0.00 sec)
- 从表
a中查询name,按照name分组对num求和,查询num总和小于 160 的行,并输出。obclient> SELECT name, SUM(num) as sum FROM a GROUP BY name HAVING SUM(num) < 160; +------+------+ | NAME | SUM | +------+------+ | a | 150 | +------+------+ 1 row in set (0.00 sec)
- 从表
a中查询id、name和num,根据num按升序(ASC)输出查询结果。obclient> SELECT * FROM a ORDER BY num ASC; +----+------+-----+ | ID | NAME | NUM | +----+------+-----+ | 3 | a | 50 | | 1 | a | 100 | | 2 | b | 200 | +----+------+------+ 3 rows in set (0.00 sec)
- 从表
a中查询id、name和num,根据num按降序(DESC)输出查询结果。obclient> SELECT * FROM a ORDER BY num DESC; +----+------+------+ | ID | NAME | NUM | +----+------+------+ | 2 | b | 200 | | 1 | a | 100 | | 3 | a | 50 | +----+------+------+ 3 rows in set (0.00 sec)
- 从表a中查询指定id的行,并使用FOR UPDATE子句把查询结果行进行锁定。
/* 在会话 1 中查询表 a 中 id=1 的行并锁定 */ obclient> SELECT * FROM a WHERE id=1 FOR UPDATE; +------+------+------+ | ID | NAME | NUM | +------+------+------+ | 1 | a | 100 | +------+------+------+ 1 row in set (0.01 sec) /* 在会话 2 中查询表 a 中 id=1 或 id=2 的行并锁定 */ obclient> SELECT * FROM a WHERE id=1 or id=2 FOR UPDATE; ORA-30006: resource busy; acquire with WAIT timeout expired obclient> SELECT * FROM a WHERE id=1 or id=2 FOR UPDATE SKIP LOCKED; +------+------+------+ | ID | NAME | NUM | +------+------+------+ | 2 | b | 200 | +------+------+------+ 1 row in set (0.01 sec)
集合类 SELECT
描述
该语句用于对多个SELECT查询的结果进行UNION、MINUS、INTERSECT。
格式
select_clause_set:
simple_select [ UNION | UNION ALL | | INTERSECT] select_clause_set_right
[ORDER BY sort_list_columns]
select_clause_set_right:
simple_select |
select_caluse_set参数解释
|
参数 |
描述 |
|---|---|
|
UNION ALL |
合并两个查询的结果 |
|
UNION |
合并两个查询的结果,并去重 |
|
MINUS |
从左查询结果集中去重出现在右查询中的结果,并去重 |
|
INTERSECT |
保留左查询结果集中出现在右查询中的结果,并去重 |
示例
以如下两表的数据为例:
CREATE TABLE t1 (c1 INT, c2 INT);
CREATE TABLE t2 (c1 INT, c2 INT);
INSERT INTO t1 VALUES (1, -1), (2, -2);
INSERT INTO t2 VALUES (1, 1), (2, -2), (3, 3);- 计算
t1、t2的所有的记录obclient>SELECT c1, c2 FROM t1 UNION ALL SELECT c1, c2 FROM t2; +------+------+ | C1 | C2 | +------+------+ | 1 | -1 | | 2 | -2 | | 1 | 1 | | 2 | -2 | | 3 | 3 | +------+------+ 5 rows in set (0.01 sec)
- 计算
t1、t2的去重后的所有记录obclient>SELECT c1, c2 FROM t1 UNION SELECT c1, c2 FROM t2; +------+------+ | C1 | C2 | +------+------+ | 1 | -1 | | 2 | -2 | | 1 | 1 | | 3 | 3 | +------+------+ 4 rows in set (0.01 sec)
- 计算
t1和t2的交集SELECT c1, c2 FROM t1 INTERSECT SELECT c1, c2 FROM t2; +------+------+ | C1 | C2 | +------+------+ | 2 | -2 | +------+------+
- 计算
t1和t2的差集obclient>SELECT c1, c2 FROM t1 INTERSECT SELECT c1, c2 FROM t2; +------+------+ | C1 | C2 | +------+------+ | 2 | -2 | +------+------+
带有 with clause 的 SELECT
描述
如果查询语句中有多个相同的子查询,可以把相同的子查询放在with clause作为公共表达式,在主体查询中直接引用即可。
格式
with_clause_select:
with_clause simple_select
with_clause:
WITH table_name [opt_column_alias_name_list] AS ( select_clause )
select_clause:
simple_select | select_clause_set
opt_column_alias_name_list:
(column_name_list)
column_name_list:
column_name | column_name , column_name_list参数解释
无
示例
以如下表格数据和SELECT查询为例。
CREATE TABLE t1(c1 INT, c2 INT, c3 INT);
CREATE TABLE t2(c1 INT);
INSERT INTO t1 VALUES(1,1,1);
INSERT INTO t1 VALUES(2,2,2);
INSERT INTO t1 VALUES(3,3,3);
INSERT INTO t2 VALUES(4);
obclient>SELECT * FROM t1 WHERE c1 > (SELECT COUNT(*) FROM t2)
AND c2 > (SELECT COUNT(*) FROM t2)
AND c3 > (SELECT COUNT(*) FROM t2);
+------+------+------+
| C1 | C2 | C3 |
+------+------+------+
| 2 | 2 | 2 |
| 3 | 3 | 3 |
+------+------+------+
2 rows in set (0.01 sec)可以抽取相同子查询为with clause:
obclient>WITH TEMP(cnt) AS (SELECT COUNT(*) FROM t2)
SELECT t1.* FROM t1, temp WHERE c1 > temp.cnt AND c2 > temp.cnt
AND c3 > temp.cnt;
+------+------+------+
| C1 | C2 | C3 |
+------+------+------+
| 2 | 2 | 2 |
| 3 | 3 | 3 |
+------+------+------+
2 rows in set (0.00 sec)