
OceanBase 快速参数化
参数化过程是指把 SQL 查询中的常量变成变量的过程。
同一条 SQL 语句在每次执行时可能会使用不同的参数,将这些参数做参数化处理,可以得到与具体参数无关的 SQL 字符串,并使用该字符串作为计划缓存的键值,用于在计划缓存中获取执行计划,从而达到参数不同的 SQL 能够共用相同的计划目的。
由于传统数据库在进行参数化时一般是对语法树进行参数化,然后使用参数化后的语法树作为键值在计划缓存中获取计划,而 OceanBase 数据库使用的词法分析对文本串直接参数化后作为计划缓存的键值,因此叫做快速参数化。
OceanBase 数据库支持自适应计划共享(Adaptive Cursor Sharing)功能以支持不同参数条件下的计划选择。
基于快速参数化而获取执行计划的流程如下图所示:
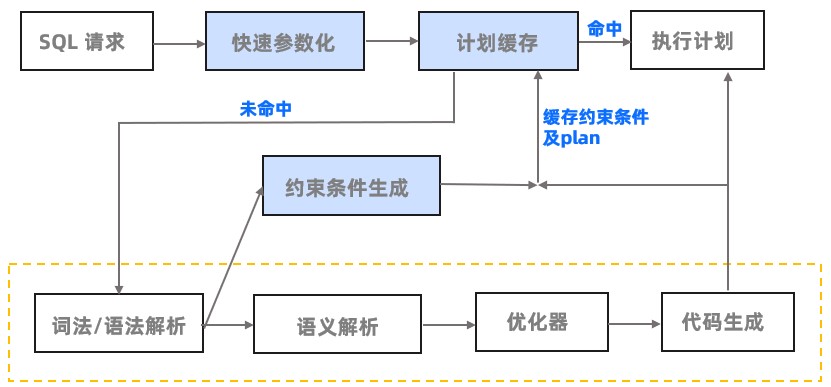
示例解析
obclient>SELECT * FROM T1 WHERE c1 = 5 AND c2 ='oceanbase';上述示例中的 SQL 查询参数化后结果如下所示,常量 5 和 oceanbase 被参数化后变成了变量 @1 和 @2:
obclient>SELECT * FROM T1 WHERE c1 = @1 AND c2 = @2;但在计划匹配中,不是所有常量都可以被参数化,例如 ORDER BY 后面的常量,表示按照 SELECT 投影列中第几列进行排序,所以不可以被参数化。
如下例所示,表 t1 中含 c1、c2 列,其中 c1 为主键列,SQL 查询的结果按照 c1 列进行排序,由于 c1 作为主键列是有序的,所以使用主键访问可以免去排序。
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY,c2 INT);
Query OK, 0 rows affected (0.06 sec)
obclient>INSERT INTO t1 VALUES (1,2);
Query OK, 1 row affected (0.01 sec)
obclient>INSERT INTO t1 VALUES (2,1);
Query OK, 1 row affected (0.01 sec)
obclient>INSERT INTO t1 VALUES (3,1);
Query OK, 1 row affected (0.01 sec)
obclient>SELECT c1, c2 FROM t1 ORDER BY 1;
+----+------+
| C1 | C2 |
+----+------+
| 1 | 2 |
| 2 | 1 |
| 3 | 1 |
+----+------+
3 rows in set (0.00 sec)
obclient>EXPLAIN SELECT c1, c2 FROM t1 ORDER BY 1\G;
*************************** 1. row ***************************
Query Plan:
| ===================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
-----------------------------------
|0 |TABLE SCAN|t1 |1000 |1381|
===================================
Outputs & filters:
-------------------------------------
0 - output([T1.C1], [T1.C2]), filter(nil),
access([T1.C1], [T1.C2]), partitions(p0)但如果执行如下命令:
obclient>SELECT c1, c2 FROM t1 ORDER BY 2;
+----+------+
| C1 | C2 |
+----+------+
| 2 | 1 |
| 3 | 1 |
| 1 | 2 |
+----+------+
3 rows in set (0.00 sec)则结果需要对 c2 排序,因此需要执行显示的排序操作,执行计划如下例所示:
obclient>EXPLAIN SELECT c1, c2 FROM t1 ORDER BY 2\G;
*************************** 1. row ***************************
Query Plan:
| ====================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
------------------------------------
|0 |SORT | |1000 |1886|
|1 | TABLE SCAN|t1 |1000 |1381|
====================================
Outputs & filters:
-------------------------------------
0 - output([T1.C1], [T1.C2]), filter(nil), sort_keys([T1.C2, ASC])
1 - output([T1.C1], [T1.C2]), filter(nil),
access([T1.C1], [T1.C2]), partitions(p0)因此,如果将 ORDER BY 后面的常量参数化,不同 ORDER BY 的值具有相同的参数化后的 SQL,从而导致命中错误的计划。除此之外,如下场景中的常量均不能参数化(即参数化的约束条件):
- 所有 ORDER BY 后常量(例如
ORDER BY 1,2;) - 所有 GROUP BY 后常量(例如
GROUP BY 1,2;) - LIMIT 后常量(例如
LIMIT 5;) - 作为格式串的字符串常量(例如
SELECT DATE_FORMAT('2006-06-00', '%d');里面的 %d) - 函数输入参数中,影响函数结果并最终影响执行计划的常量(例如
CAST(999.88 as NUMBER(2,1)) 中的 NUMBER(2,1),或者 SUBSTR('abcd', 1, 2) 中的 1 和 2) - 函数输入参数中,带有隐含信息并最终影响执行计划的常量(例如
SELECT UNIX_TIMESTAMP('2015-11-13 10:20:19.012'); 里面的“2015-11-13 10:20:19.012”,指定输入时间戳的同时,隐含指定了函数处理的精度值为毫秒)
为了解决上面这种可能存在的误匹配问题,在硬解析生成执行计划过程中会对 SQL 请求使用分析语法树的方法进行参数化,并获取相应的不一致的信息。例如,某语句对应的信息是“快速参数化参数数组的第 3 项必须为数字 3”,可将其称为“约束条件”。
对于下例所示的 Q1 查询:
Q1:
obclient>SELECT c1, c2, c3 FROM t1
WHERE c1 = 1 AND c2 LIKE 'senior%' ORDER BY 3;经过词法分析,可以得到参数化后的 SQL 语句如下例所示:
obclient>SELECT c1, c2, c3 FROM t1
WHERE c1 = @1 AND c2 LIKE @2 ORDER BY @3 ;
/*参数化数组为 {1,‘senior%’ ,3}*/当 ORDER BY 后面的常量不同时,不能共用相同的执行计划,因此在通过分析语法树进行参数化时会获得另一种参数化结果,如下例所示:
obclient>SELECT c1, c2, c3 FROM t1
WHERE c1 = @1 AND c2 LIKE @2 ORDER BY 3 ;
/*参数化数组为{1, ‘senior’}
约束条件为“快速参数化参数数组的第 3 项必须为数字 3”*/Q1 请求新生成的参数化后的文本及约束条件和执行计划均会存入计划缓存中。
当用户再次发出如下 Q2 请求命令:
Q2:
obclient>SELECT c1, c2, c3 FROM t1
WHERE c1 = 1 AND c2 LIKE 'senior%' ORDER BY 2;经过快速参数化后结果如下例所示:
obclient>SELECT c1, c2, c3 FROM t1
WHERE c1 = @1 and c2 like @2 ORDER BY @3;
/*参数化数组为 {1,'senior%' ,2}*/这与 Q1 请求快速参数化后 SQL 结果一样,但由于不满足“快速参数化参数数组的第 3 项必须为数字 3”这个约束条件,无法匹配该计划。此时 Q2 会通过硬解析生成新的执行计划及约束条件(即“快速参数化参数数组的第 3 项必须为数字 2”),并将新的计划和约束条件加入到缓存中,这样在下次执行 Q1 和 Q2 时均可命中对应正确的执行计划。
基于快速参数化的执行计划缓存优点如下:
- 节省了语法分析过程。
- 查找 HASH MAP 时,可以将对参数化后语法树的 HASH 和比较操作,替换为对文本串进行 HASH 和 MEMCMP 操作,以提高执行效率。